



Advanced Database Systems
Data Mining
1
Docsity.com

































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Some concept of Advanced Database System are Types Supported, Simple Data Model, Concurrency Control Two, Continuously Adaptive, Cost-Based Optimization, Data Access From Disks, Data Warehousing. Main points of this lecture are: Data Mining, Subsidiary Issues, Data Cleansing, Visualization, Warehousing of Data, Megabyte, Bogus Data, Decision Trees, Clusters, Hidden-Markov
Typology: Slides
1 / 42

This page cannot be seen from the preview
Don't miss anything!
4
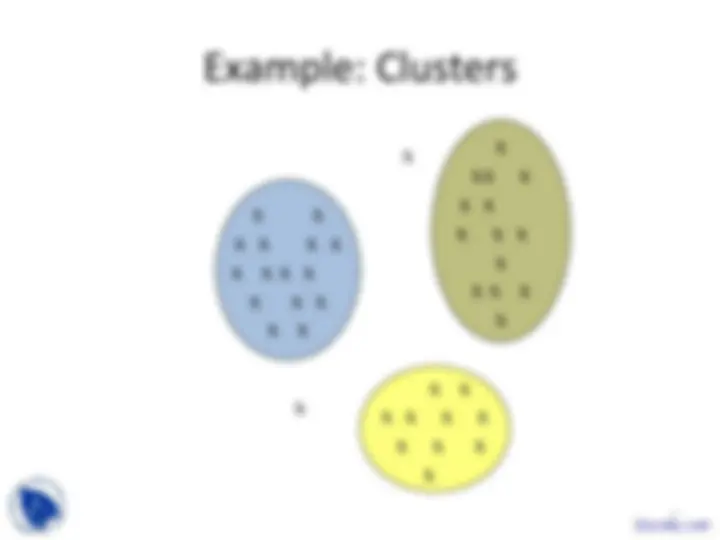
x x x x x x x x x x x x x x x
x xx x x x x x x x x x x x
x x x x x x x x x x
x
x
Market Baskets Frequent Itemsets A-priori Algorithm
of i 1 ,…, i (^) k then it is likely to contain j.