



Data Preprocessing
Week 2























































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of data preprocessing techniques used in data mining to improve accuracy, simplify results, and reduce data volume. Topics include data cleaning for handling missing values and noisy data, data integration for schema and object matching, and data reduction through techniques such as data cube aggregation and attribute subset selection. The document also covers concepts like correlation analysis and discretization.
Typology: Essays (high school)
1 / 67

This page cannot be seen from the preview
Don't miss anything!
Data
Types
Data
Repositories
Data
Preprocessing
Present
homework
assignment
f^
h^
d^
i^
i^
f^
j
Prepare
for
the
one
‐page
d
escription
of
your
group
project
topic
-^
Prepare for presentation using slidesPrepare
for
presentation
using
slides
Due
date
beginning
of
the
lecture
on
Friday
February
th
Figur disco
re 1.4 Data overy
a Mining as a step in the proceess of knowwledge
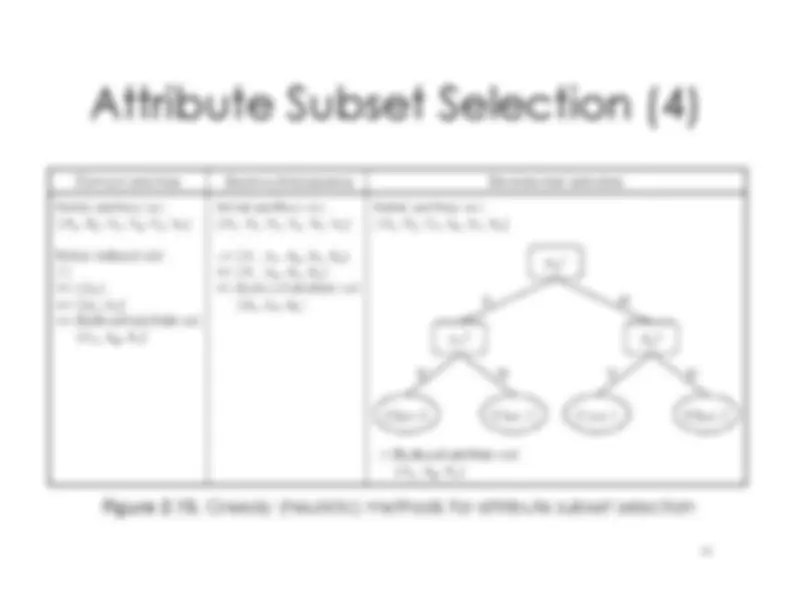
Figure 2.1 Forms of data preprocessing
Less
data
data
mining
methods
can
learn
faster
Hi h
-^
Hi
gher
accuracy
data
mining
methods
can
generalize
better
Simple results
-^
Simple
results
they
are
easier
to
understand
Fewer
attributes
For
the
next
round
of
data
collection,
saving
can
be
made
by
removing
redundant
and
irrelevant
features
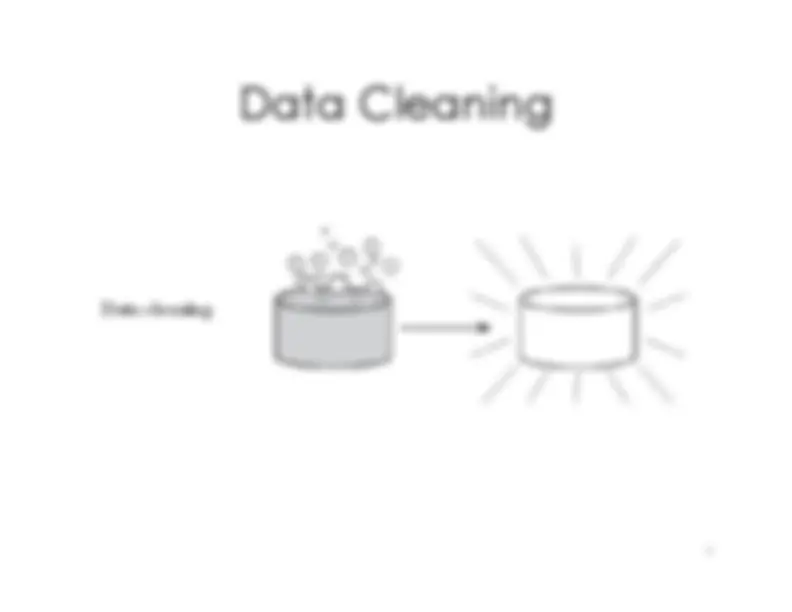
“Data
cleaning
is
one
of
the
biggest
problems
in
data
warehousing”
Ralph
Kimball
“Data
cleaning
is
the
number
one
problem
in
data
warehousing”
survey
-^
-^
Ignore
the
tuple
Fill in the missing value manuallyFill
in
the
missing
value
manually
Use
a
global
constant
to
fill
in
the
missing
value
Use
the
attribute
mean
to
fill
in
the
missing
value
Use
the
attribute
mean
for
all
samples
belonging
to
the
same
class
as
the
given
tuple
Use
the
most
probable
value
to
fill
in
the
missing
value
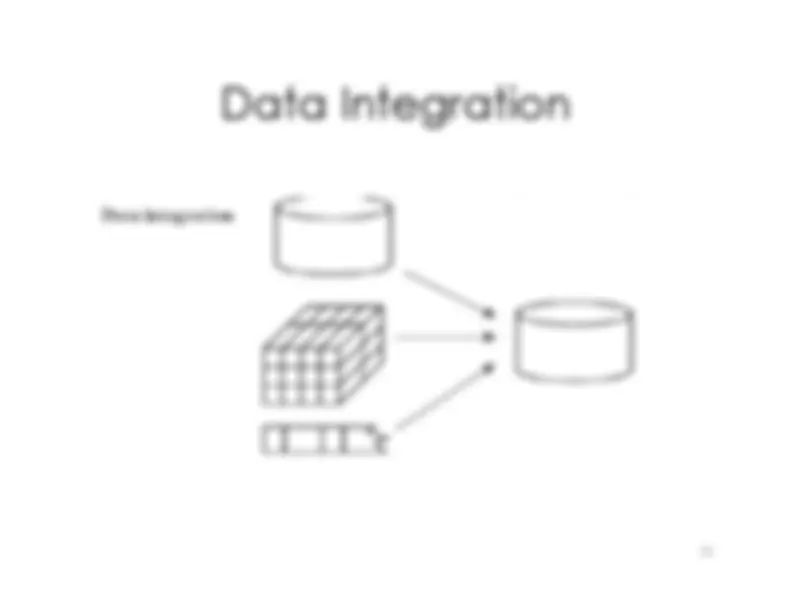
Schema
integration
and
object
matching
Entity
identification
problem
Redundant
data
(between
attributes)
occur
often
when
integration
of
multiple
databases
Redundant
attributes
may
be
able
to
be
detected
by
l ti
l^
i^
d^
hi
th d
correlation
analysis,
and
chi
‐square
method