


第第第第第第第第第第第第
第第第第第第第第第第第第
第第第
第第第第第第第第第第第




































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A lecture note from a university course on probability theory. It covers the concepts of probability density functions (pdf), histograms, and estimation of parameters using maximum likelihood estimators and the information inequality. The document also includes examples using various probability distributions such as binomial, poisson, exponential, gaussian, and chi-square.
Typology: Study notes
1 / 45

This page cannot be seen from the preview
Don't miss anything!
第第第 第第 (^) 第第第第第第第第 (^) 第第第第第第第第第第第第第第第 (^) 第第第第第第第第第第第第第第第第第第第第 (^) 第第第第第第第第第第第第第第第 (^) 第第第第第第第第第第第第 第第第 第第第第第第第第第第第第第第 (^) 第第第第第第第第第第第第 (^) 第第第第第第第第第第第第第第第第 第第第 第第第第第第第第 (^) 第第第第第第第第第第第第第第第第第第第第第 (^) 第第第第第第第第第第第第 (^) 第第第第第第第第第第第第第第第第
第第第 第第第第 (^) 第第第第第第第第第第第第第第第第第第第第 (^) 第第第第第第第第第第第第第 (^) 第第第第第第第第第第第第第第第第第第第 第第第 第第第第第第第第第第第第第第第第第 (^) 第第第第第第第第第第第 (^) 第第第第第第第第第第第第第第第第第 第第第 第第第第第第第第第 (^) 第第第第第第第第第第第第
A random variable is a numerical characteristic assigned to an element of the sample space; can be discrete or continuous. Suppose outcome of experiment is continuous value x
→ f(x) = Probability Density Function (pdf)
Or for discrete outcome xi with e.g. i = 1, 2, ... we have
x must be somewhere
probability mass function
x must take on one of its possible values
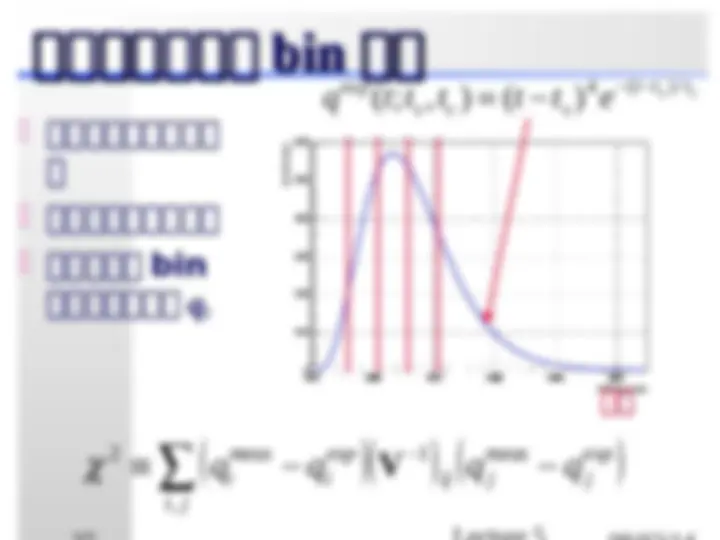
histogram: a graphical display of tabulated frequencies.
Probability Density Function
(pdf): histogram with
infinite data sample, zero bin width, normalized to unit area.
第第第 第第第 && PDFPDF
( ) ( )
number of entries bin width
N x f x n x n x
第第第第第第第第第第第第 BinomialBinomial 第第
第第第
(^) Roll a standard die第第
第第 ten times and count the number 第 k 第 of sixes. The distribution of this random number is a binomial distribution with n = 10 and p = 1/
(^) 第第第
(^) 第第第第第 Binomial
Gaussian
第第第第第第第第第第 PoissonPoisson 第第
第第第
(^) 第第第第第第第第第第第第第 k 第
第第第第第第第第第第第第第第第第 第第 第第第第
(^) 第第第第第第第第第
(^) 第第第第第 Poisson
Gaussian
Define covariance cov[ x , y ] (also use matrix notation Vxy ) as
Correlation coefficient (dimensionless) defined as
If x , y , independent, i.e., , then
→ x and y , ‘uncorrelated’
第第第第第第第第第第 第第第第第第第第第第
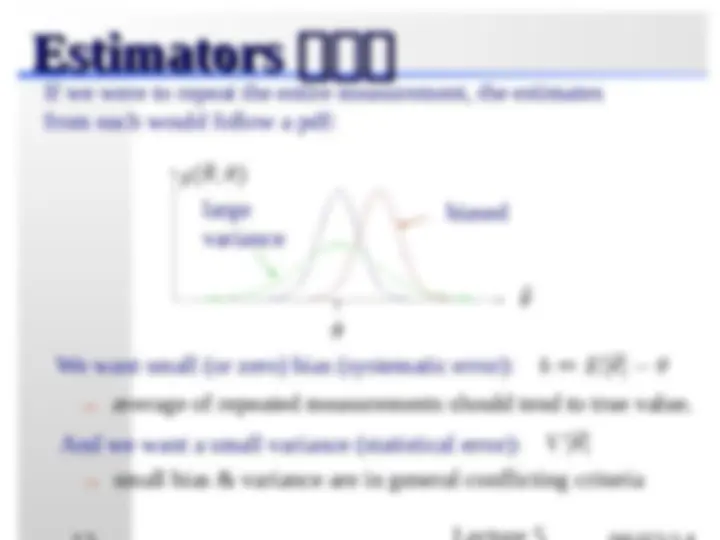
If we were to repeat the entire measurement, the estimates from each would follow a pdf:
large biased variance
best
We want small (or zero) bias (systematic error): → average of repeated measurements should tend to true value. And we want a small variance (statistical error): → small bias & variance are in general conflicting criteria
Estimators Estimators 第第第第第第
Parameter:
Estimator:
We find:
Suppose the outcome of an experiment is: x 1 , ..., xn , which
Now evaluate this with the data sample obtained and regard it as a function of the parameter(s). This is the likelihood function:
( xi constant)
第第第第 第第第第
a high probability to get data like that which we actually found.
So we define the maximum likelihood (ML) estimator(s) to be the parameter value(s) for which the likelihood is maximum. ML estimators not guaranteed to have any ‘optimal’ properties, (but in practice they’re very good).
Find its maximum by setting
→
Monte Carlo test: generate 50 values
We find the ML estimate:
parameter of exponential pdf (2) parameter of exponential pdf (2)
Having estimated our parameter we now need to report its ‘statistical error’, i.e., how widely distributed would estimates be if we were to repeat the entire measurement many times.
One way to do this would be to simulate the entire experiment many times with a Monte Carlo program (use ML estimate for MC).
For exponential example, from sample variance of estimates we find:
Note distribution of estimates is roughly Gaussian − (almost) always true for ML in large sample limit.
estimators estimators 第第第第第第 : Monte Carlo: Monte Carlo 第第第第