Download Detecting Epileptic Seizures from Electroencephalography and more Lecture notes Compiler Design in PDF only on Docsity!
▪ We can extract features from EEG signals for automated seizure detection. ▪ Using a combination of features enhanced true positive rate and reduced the false positive rate. ▪ Spectral features combined with power or zero-crossings performed the best.
Detecting Epileptic Seizures from Electroencephalography
Duha Awad
1
, Jeff Craley
2
, Emily L. Johnson, M.D.
3
, Archana Venkataraman, Ph.D.
2 Introduction Further Research Method Conclusion 1 Department of Electrical and Computer Engineering, University of Maryland, College Park, USA 2 Department of Electrical and Computer Engineering, Malone Center, Johns Hopkins University, Baltimore, USA 3 Department of Neurology, Epilepsy Center, Johns Hopkins Hospital, Baltimore, USA Features Motivation ▪ Epilepsy affects 1 % of the world population. ▪ Epilepsy seizure detector would save doctors & specialists time. Background ▪ EEG is a non-invasive method that measures the electrical activity of the brain. ▪ Epilepsy is a neurological disorder caused by abnormal nerve cell activity in the brain that causes episodes known as seizures. Hypothesis ▪ Using ensemble of features will increase performance in seizure detection. Acknowledgments References ▪ Noninvasive Seizure Localization for Focal Epilepsy. ▪ Seizure detector could be further used to an automated anti-seizure therapy. This work was funded by JHMI Synergy Award. A special thanks to Jeff Craley, Niharika Shimona D’Souza, Ravi Shankar, Dr. Archana Venkataraman, Dana Walter-Shock, and the CSMR– REU family.
- Shoeb, A.H., Guttag, J.V.: Application of machine learning to epileptic seizure detection. In: International Conference on Machine Learning. (2010) 975–982.
- Orosco, L., Garces, A., & Laciar, E.: Review: A Survey of Performance and Techniques for Automatic Epilepsy Detection. (2013). Results Test seizure recording Test non-seizure recording
- Seizure
- All non-seizure recordings but 1
- Non-Seizure
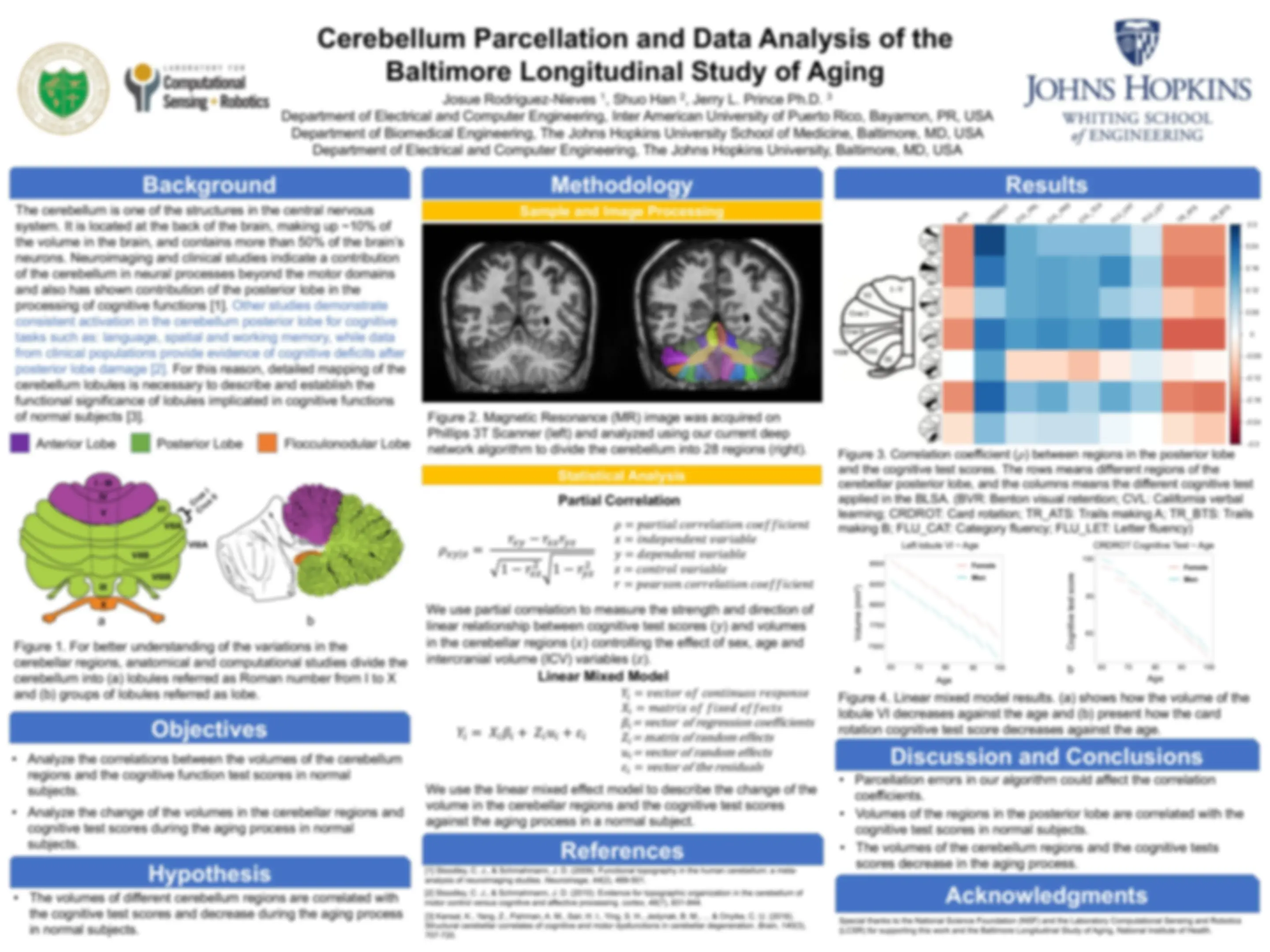
- All seizure recordings but 1 𝑦 𝑡𝑟𝑎𝑖𝑛 𝑦𝑡𝑒𝑠𝑡 Raw EEG Data Low Pass Filter Cutoff =30 Hz High Pass Filter Cutoff =1.5 Hz Removes muscle artifacts Removes DC trends & slow artifacts Signal Pre-Processing Power and Zero Crossings Cross Correlation, Pearson r Correlation, and Mean Phase Coherence Fast Fourier Transform and Band Pass Feature Extraction Time Domain Cross Channels Spectral Classification Muscle Action Eye Movement Seizure Evaluation 0
1 Single Features Sensitivity: True seizures detection Specificity: False seizure detection Sensitivity training/test evaluation (^) Specificity training/test evaluation dataset Majority-voting TREE # TREE #2 (^) TREE # TREE # 𝑦 𝑦𝑡𝑒𝑠𝑡 𝑡𝑟𝑎𝑖𝑛 Data Acquisition: Boston Children's Hospital. Data : 20 epileptic patients; 154 seizure recordings and 495 non-seizure recordings. Each recording is ~ an hour long. Windowing 2 seconds window
Time Domain:
𝑖= 1 𝑁 𝑋 2 [𝑖] Zero Crossings (ZC)
Cross Channels:
Spectral:
Band Pass Filter (BP) Count places the signal crosses the x-axis Power (P) Fast Fourier Transform (FFT) Cross Coherence (CC), Pearson r (PR), Mean Phase Coherence (MPC) Eight bandpass filters for computing power across different frequency bands CC – Amplitude Similarity PR – Scaled Amplitude Similarity MPC – Phase Similarity 0
1 Combined Features True Positive Rate False Positive Rate
- High dimensional datasets usually contain multiple low-dimensional subspaces.
- Subspace clustering is the problem of learning a union of subspaces from unlabeled data, with applications in motion segmentation and facial recognition
Induced 1-Norm Subspace Clustering via Accelerated ADMM
Evan Frenklak 1, , Chong You 2 , Guilherme França 2 , Benjamin B. Haro 2 , René Vidal 2 1 Electrical Engineering and Computer Science Department, University of California Berkeley 2 Mathematical Institute for Data Science, Johns Hopkins University Conclusions Challenge Induced 1-Norm Subspace Clustering Conclusions
- Our work provides theoretical backing for further research into induced 1-norm subspace clustering
- Induced 1-norm regularization leads to reduced SSR error and reduced median clustering error in some datasets
- Accelerated ADMM improves on ADMM for convergence rate in this problem Future Work
- Experiment on more data sets to further explore the accuracy improvement potential of the induced 1- norm
- Different optimization approaches to improve convergence in the induced 1-norm SSC problem Acknowledgements
- NSF grant number 1618637
- Work performed by EF as a summer (2018) student with the Vision Lab at JHU. References
- E. Elhamifar and R. Vidal, “Sparse subspace clustering,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition. June, 2009.
- T. Goldstein, et al., “Fast Alternating Direction Optimization Methods,” SIAM Journal on Imaging Sciences 7 no. 3, (2014).
- G. França and D. P. Robinson and R. Vidal, “ADMM and Accelerated ADMM as Continuous Dynamical Systems,” ICML (2018)
- W. Su, S. Boyd, and E. J. Candès, “A Differential Equation for Modeling Nesterov’s Accelerated Gradient Method: Theory and Insights,” Journal of Machine Learning Research 17 no. 153, (2016). Motivation Accelerated ADMM
- The L1 matrix norm is equal to the sum of the matrix’s columns’ 1-norms: 𝐶 " = $ 𝑐 & " ' &("
- L1 regularization allows for greater sparsity in some columns over others, so solutions lack consistent column- wise sparse regularization in the SSC optimization problem Initialize 𝐴 3 , 𝐶 3 , 𝐶^5 3 ∆ 3 , ∆^7 3 , 𝑘 7 = 0 𝑓𝑜𝑟 𝑘 = 0 , 1 , 2 , … 𝐝𝐨: 𝐴 CD" = 𝜆𝑌 G 𝑌 + 𝜌𝐼 K" (𝜆𝑌 G 𝑌 + 𝜌𝐶^5 C − ∆^7 C ) 𝑀 CD" = 𝐴 CD"
- 𝜌 K" ∆^7 C 𝐶 CD" = prox T UV W (^) V,V 𝑀 CD" − 𝑑𝑖𝑎𝑔(𝑀 CD" ) ∆ CD" = ∆ C
- 𝜌(𝐴 CD" − 𝐶 CD" ) γ CD" = 𝑘 7 / (𝑘 7
- 3 ) ∆^7 CD" = ∆ CD"
- γ CD" ∆ CD" − ∆ C 𝐶^5 CD" = 𝐶 CD"
- γ CD" (𝐶 CD" − 𝐶 C ) 𝑖𝑓 𝐴 CD" − 𝐴 C _ < 𝐴 C − 𝐴 CK" _ 𝐝𝐨: 𝑘 7 = 1 𝑒𝑙𝑠𝑒 𝐝𝐨: 𝑘 7 = 𝑘 7
- 1
- Each data point can be expressed as a linear combination of the entire dataset excluding itself. That is: 𝑌 = 𝑦 " … 𝑦 ' 𝑦 & = 𝑌𝑐 & 𝑐 & (𝑗) = 0
- SSC finds the sparsest such representation by solving: min g 𝐶 "
𝜆 2 𝑌 − 𝑌𝐶 h _
- If the sparsity of 𝑐& is upper bounded by the dimension of its respective subspace, SSC tends to perform more accurately Sparse Subspace Clustering Table 1: The induced 1-norm’s proximal operator is more computationally intensive. Accelerated optimization methods can help reduce total iterations required to solve induced 1-norm SSC.
- The induced matrix 1-norm is defined as the largest 1-norm of all columns: 𝐶 "," = max & 𝑐 & "
- Thus, the induced 1-norm acts as a threshold, upper bounding each column to produce similar regularization across all columns Prox. Operator Method Complexity L1 Matrix Norm Closed Form 𝑂(𝑁 _ ) Induced 1-Norm Iterative 𝑂 𝑁 _ log 𝑁 " = (^) +
- ⋯ + "," = (^) + (^) + ⋯ + SSC-L1 SSC-1, Hopkins155 Motion Segmentation, 2 Cluster Sequences Mean SSR Error: 4.24% 4.25% Mean Clustering Error: 1.56% 2.96% Median Clustering Error: 0.00% 0.00% Hopkins155 Motion Segmentation, 3 Cluster Sequences Mean SSR Error: 7.25% 5.42% Mean Clustering Error: 4.32% 6.82% Median Clustering Error: 0.80% 0.56% Hopkins155 Motion Segmentation, All Sequences Mean SSR Error: 4.92% 4.51% Mean Clustering Error: 2.19% 3.83% Median Clustering Error: 0.00% 0.00% Table 2 (Above): Comparative performance on the Hopkins Motion Segmentation dataset (no representation matrix threshold). Induced 1-Norm Regularization reduced or matched Mean Subspace Recovery Error and Median Clustering Error while increasing Mean Clustering Error. Figure 7 (Left): Descending values of column 1-Norms from final representation matrix for Sequence 85. Induced 1-Norm Regularization produced a more even distribution across columns. Figures 1 - 6 : 5 subspaces each of dimension 6 were randomly generated with ambient dimension 9. On a dataset containing 100 points sampled from each subspace (N = 500 total), convergence plots demonstrate reduced error and increased time per iteration for SSC-1,1 compared to SSC-L1. Acceleration of SSC-1,1 led to faster convergence with a similar time per iteration. 𝜌m" = 1000 , λm" = 1000 / 𝜇m" 𝑌 , 𝜌"," = λ"," = 1000 / 𝜇"," 𝑌 , SSR Error Clustering Error Obj. Value (Log Scale) Experiments Synthetic Data Hopkins 155 Motion Data min g 𝐶 ","
p _ 𝑌 − 𝑌𝐶 h _ SSC-1,1 Optimization Problem: Lemma 1: Minimum Regularization Parameter for Induced 1-norm SSC The solution of the SSC-1,1 problem is nontrivial, 𝐶 ≠ 0 , provided: 𝜆 ≥ 1 𝜇 "," 𝑌 where 𝜇 "," 𝑌 = $ 𝑥 & v ' &(" X = Y y Y − 𝑑𝑖𝑎𝑔(Y y Y) Accelerated variables interpolate based on difference from previous iteration Based on a differential equation model, the restart scheme allows acceleration to regain momentum during the algorithm’s convergence _Column Index, Ordered by 1-Norm 1
Norm Column Value Iteration Time (s)_
Time(s) Time(s) Unsafe error percentage: 53.45% Fig 1: Force sensing tool (^) Fig 2: Neural network architecture
Robot-Assisted Retinal Microsurgery with
Real-Time Sclera Force Predictions
Taaha Kamal, Changyan He, Iulian Iordachita
Conclusions
Methods Results
Results
Introduction
Methods
Purpose
Predicting forces 25 milliseconds in the future with collected data resulted in a root mean squared error of: Fx: 6.81 mN, Fy: 6.61 mN And max force was: Fx: 120.30 mN, Fy: 198.44 mN Multi-user study to see how active control is adapted by groups of different levels of surgical expertise The ability to predict future excessive forces and counter them decreases sclera damage Robot-assistance with active control enhances safety during retinal microsurgery
Acknowledgements
Experiment: The force sensing tool is inserted through the scleratomy port (Fig 4) and follows the vessels with and without active control. Sclera forces are then analyzed to determine how reliably the robot’s active feedback performed. Time(s) When tested in real-time, the root mean squared error was: Fx: 14.20 mN, Fy: 16.13 mN And max force was: Fx: 221.62 mN , Fy: 150.11 mN Fs (mN) Fx_Predicted Fx_Groundtruth Fy_Predicted Fy_Groundtruth Fig 5: Comparison of groundtruth and predicted sclera forces (Fx and Fy) with active control. Predicting sclera forces 25 milliseconds in the future. Fig 4: Experimental setup and eye phantom
Future Directions
Fs (mN) Fs (mN) Unsafe error percentage: 12.63% Active robot control did counter excessive forces, however, the threshold was still passed. Increasing prediction time further into the future can increase force insight and decrease error Fig 6: Sclera force norm without active robot control Fig 7: Sclera force norm with active robot control U.S. National Institutes of Health under grant number 1R01EB023943- Force sensors on the end of the surgical tool allow us to analyze the force on the eye (Fig 1). The tool’s sclera force measurement error is 2.3 mN. The data we retrieve from these sensors is used to train a neural network to infer ensuing forces (Fig 2) Performing surgery on the human eye is an intricate procedure. Unexpected force during surgery could damage the sclera (white part of the eye). Robot-assistance can reduce the risk of error but cannot protect against unexpected movement by a user Predicting sclera forces in advance can prevent upcoming unsafe manipulations The project’s aim was to keep sclera forces under 140 mN in order to improve the safety of retinal microsurgery A neural network was trained to predict sclera forces 25 (ms) in the future and provide active robot feedback if an excessive force is predicted If the predicted sclera forces exceed 140 mN, the velocity is altered to scale down the force to prevent an excessive force on the eye (Fig 3) Fig 3: Prediction and robot control process
Heading Pitch Force/ torque Sensor Data Acquisition System for Physics-based Robot Obstacle Traversals Acknowledgements Many applications require robots to traverse complex 3 - D terrain where cluttered obstacles are unavoidable. Unlike most robots, animals can actively adjust their motion using mechanical sensing of the physical environment. Need for Physics-based Control & Planning Autonomous Data Acquisition System Motivation (^) Robot-Obstacle State Estimation Using Forces Future Work: Traversal of Cluttered Obstacles We will develop ability to autonomously traverse cluttered terrain using physics-based control/planning. Measured internal forces/torques during traversal of a single obstacle matched well with predictions of a quasi-static force model using robot-obstacle interaction state. This means that the robot can use internal force to estimate interaction state, confirming our hypothesis. Recent Work in Traversal via Physical Contact We showed that a wheeled robot can traverse cluttered pillars by properly using physical interaction with obstacles. Timothy Greco, Yuanfeng (Rick) Han, Yucheng Kang, Yulong Wang, Noah Cowan, Chen Li Department of Mechanical Engineering, Laboratory for Computational Sensing & Robotics Johns Hopkins University Approach (^) Contact Stuck Hypothesis A locomotor (animal/robot) can use internal forces due to physical interaction with the terrain to estimate its terrain- interaction state for control/planning to traverse obstacles. −𝐹 𝑛 ∙ 𝑙 ∙ sin 𝜙 + 𝑀𝑔 ∙ 𝑠 ∙ cos 𝜙 = 0 𝐹 𝑁 ∙ sin 𝜙 − mg ∙ cos 𝜙 + 𝐹 𝑧 = 0 −𝐹 𝑁 ∙ sin 𝜙 ∙ 𝑑 + 𝑇 𝑥 = 0 tan 𝜃 = 𝑑/𝑙 ∙ cos 𝜙 We thank Marin Kobilarov for discussion, and Yaqing Wang, Qiyuan Fu, and Ratan Othayoth for technical assistance. This work is funded by NSF CSMR REU (TG) and an Army Research Office Young Investigator Award, a Burroughs Wellcome Fund Career Award at the Scientific Interface, and JHU WSE Startup funds (CL). An automated experimental system was developed (by Tim Greco) to move the robot and measure its internal force and robot-obstacle interaction state (position and orientation of robot relative to obstacle) over the state space possible (- 65 º < pitch < - 35 º, - 15 º < heading < 15 º). Experimental Setup 𝜏𝑥 Side View Top View Side View Top View
Future Work Oil Compensator Development of the JHU ROV II
Katherine Mao, Florian Pontani, Aiden Devaney, Charlie
Watkins, Eli Pivo, Tyler Paine, Louis Whitcomb
Background and Goals Power Housing CPU Housing Frame Acknowledgements
- Design & Manufacture Power Housing Mark II
- Assemble & Test CPU Housing
- Manufacture & Assemble Frame
- Test Oil Compensation System Background and Goals
- Torqeedo Travel 1003 L Thruster
- Original lip seal failed waterproofing test
- Attempted replacement seals failed waterproofing test
- Flood internals with mineral oil Objectives
- Improve frame design for JHU ROV II
- Layout housings & sensors onboard JHU ROV II Previous State of Design
- JHU ROV I – 52” x 33” x 22”
- Smaller than JHU ROV I – 42” x 35” x 29”
- No room for wiring
- Old thruster model Features
- 1 - 1/4 Pipe size speed rail
- Dimensions: 43” x 48” x 33”
- 6 thrusters, 6 degrees of freedom
- Improved design for housing mounting
- Inertial Measurement Units (IMU) and Doppler Velocity Log Sonar (DVL) aligned along frame centerline
- Hard-lift point for transportation
- Bumper guards for thrusters JHU ROV (Remotely Operated
- Test bed for experimental research in ROV control and navigation algorithms
- 15 years old JHU ROV II – Existing Design
- Continuation of previous two year’s REU work Project Goals
- Assemble power housing Mark I
- Finalize CPU housing design
- Design JHU ROV II frame & trim
- Manufacture oil compensator Mark I
- Remove battery wheels
- Power JHU ROV II via tether
- Extra connector needed to supply power Mark II
- Redesign power distribution boards & charging circuitry
- Modify battery wheels
- Power JHU ROV II via tether or batteries Updates
- Extended length of housing from 20” to 26”
- Designed mounting for Vicor DC-DC converters
- Added chassis roller wheels
- Modified connector layout Thanks to Dana Walter-Shock, the CSMR REU program coordinator, and to Zak Harris, Andrew Spielvogel, Rachel Hegeman, and Andy Cohen Torqeedo Travel 1003 L Thruster Mark II JHU ROV sitting on deck in the Dynamics System and Control Laboratory (DSCL) JHU ROV ( R emotely O perated underwater V ehicle) Design
- Six thrusters linked to central compensator
- Watertight rubber sock holds mineral oil
- Spring (k = 12 lbs/ft) compresses oil
- Quick disconnect connectors from thruster
- Flooded housing Vicor DC-DC Converter mounting Chassis Roller Wheels Modified Connector Layout Modified Connector Layout Mark I Circuit Testing Preliminary JHU ROV II Frame Design Latest JHU ROV II Frame Design Housing Mounting Holders Mounting Plate DVL CPU Housing Power Housing PHINS Inertial Navigation System KVH Gyrocompass Thrusters Hard Lift Point Mark I Stationary Endcap Disconnect Valves Oil Sleeve Adjustable Endcap Spring CPU Housing Stationary Endcap Bumper Guards Not Pictured
- Flotation blocks
- SHARPS system
- Depth Sensor
- Oil Compensator
FPGA Firmware Development for the Da Vinci Research Kit Mikiyas Bokan , Prof. Peter Kazanzides Laboratory For Computational Sensing and Robotics Johns Hopkins University Conclusion Filters play a significant role in digital signal processing systems. Filters improve signal quality by discriminating certain part of a signal and retaining another part of a signal. Therefore, filters are used to remove noise from signal. Filters can be classified as analog and digital based on implementation. The main purpose of filters in the Da Vinci Research Kit is to clean potentiometer signals and motor currents. Currently the DVRK systems in the field are equipped with Analog filters that implement a low pass filter with a cutoff frequency of 60hz. A low pass filter is a type of filter which eliminates signals whose frequency is above the cutoff frequency while retaining signals whose frequency is below the cutoff frequency. The signals that are filtered in this project are potentiometer signals. Potentiometers have two major purposes in the DVRK system. These are preloading the encoder values and for performing safety checks. In this research project we propose replacing analog filters with digital filters. Digital filters perform filtering by executing a set of mathematical operations on a sampled discrete time signal. One the main advantages of using a digital filter is that the cutoff frequency can adjusted to produce various types of filters. Digital filters can be reprogrammed via software. All of these features makes digital filters more suitable for the DVRK system. For this project digital filters are implemented in Field Programmable Gate Array (FPGA). The particular type of FPGA used is the IEEE-1394 FPGA Controller. FPGAs have a special hardware known as DSP48 slice which is dedicated for digital signal processing. FPGAs expedite computation because of their parallel architecture. There are two broad categories of digital filters based on implementation. These are Finite Impulse Response (FIR) and Infinite Impulse Response(IIR) filters. For this project we chose FIR filters. FIR filters are filters in which the output is expressed as the weighted sum of past inputs. A hardware description language called Verilog is used to program the FPGA. The Xilinx ISE software package comes with an FIR compiler that allows a user to produce the desired filter. Method We have implemented a low pass filter with a cutoff frequency of 5khz. A software package called Chipscope is used to perform low level debugging. The figure below shows a 5khz lowpass filter passing a 1khz input signal. The yellow sine wave is the input 1khz signal while the blue sine wave is the filtered output. The sampling frequency is 0.02MHZ while the delay is 0.5 millisecond. Introduction Acknowledgment While a 60hz analog filter performs significant amount of filtering, the cut off frequency can’t be adjusted via software. Hence analog filters aren’t suitable in situations where we need to change the cut off frequency as desired. Another issue that arises from analog filters is that they can sometimes be affected by thermal and environmental factors. Moreover, filtering at 60hz is associated with a significant amount of delay during operation. Hence, filtering at a low frequency makes multiplexing between setup joints slow. Problem statement Results We then applied a 10khz signal through the function generator. As expected the 5khz low pass filter removed this input signal. Just as the previous case the yellow signal is the 10khz input while blue signal is the eliminated signal. We have successfully implemented a 5khz low pass filter. Unlike the analog filter this digital filter can be reprogrammed to produce different types of filters. However, more work should be done in eliminating the delay between input and output. Finally this digital filter can used to clean potentiometer and motor current signals.
- Professor Peter Kazanzides
- Keshuai Xu Input Delay operator Summation Output Multiplier Fig 1. Frequency diagram for a low pass filter Fig 3. Block Diagram for FIR filters Fig 4. A 5khz lowpass filter passing a 1khz signal Fig 5. A 5 khz signal eliminating a 10 khz signal
Spray-Coating Flexible Optoelectronics for Solar Energy Harvesting and Sensing on Any Surface Laura Shimabukuro 1 , Botong Qiu 2 , Lulin Li 2 , Yida Lin 2 , Susanna M. Thon 2 1 Department of Electrical Engineering, Sacramento City College 2 Department of Electrical and Computer Engineering, Johns Hopkins University Introduction Methods Results Conclusion
- 1 Solution processed semiconductors offer the promise of low cost, production-scale optoelectronic devices, such as flexible solar cells and photodiode infrared sensors.
- 1 However, their current uses are limited to lab scale production methods, such as spin-coating and dip-coating.
- Spray-coating has emerged as a more efficient method to produce large-scale flexible devices that can be used on any type of surface.
- Goal: In this project we aim to build the first colloidal quantum dot solar cell in which all cell layers, including electrodes , are deposited via spray-coating as a proof-of-principle demonstration of a manufacturing method that can be applied to any surface. 8 cm, 6’30’’ (1min-spray-1min-dry) 0.5 mg/mL AgNW Electrode Spray Optimization Spin-coated ZnO References Silver Nanowires Zinc Oxide The three main parameters we tested to produce uniform and optimal density layers were:
- Distance between the nozzle and substrate
- Spray pattern
- Solution concentration Spray-coated ZnO
- Our optimized AgNW sample (1’ spray, 1’ dry) had an average transparency of 75% across the visible region and an optimal sheet resistance of 21.9-36.5 Ω/sq, comparable to the best conventionally-deposited solar cell transparent electrodes.
- We achieved a spray-cast ZnO layer of comparable thickness and optical density to conventionally-deposited materials for spraying conditions of 10’ of continuous spray from a 2mg/mL ZnO solution.
- We achieved our goal of the first demonstration of a completely spray-deposited CQD solar cell. This proof-of-principle demonstration should enable flexible deployment of solar energy harvesting and sensing technologies on a variety of urban infrastructures and surfaces in remote locations.
- Future work includes optimizing the spray parameters for the remaining layers of the solar cell and achieving comparable performance in all-spray and conventional devices. We optimized each parameter to achieve the best tradeoff between transparency and conductivity. Figure: (a) Schematic of CQD solar cell architecture (b) Custom-Build Spray- Coating System (a) (b) We tested each parameter to achieve a continuous spray distribution and uniform thickness, similar to the results from spin coating. Absorber Layer Spray Optimization Quantum Dots We began optimizing the spray coating of an untreated quantum dot layer. The tested parameters include:
- Gas Pressure
- Spray pattern
- Solution concentration AgNW ZnO Quantum Dots Best Samples Measurement Results
- 21.9-36. Ω/sq
- > 75% avg. transmission
- Thickness: ~200 nm
- Thickness comparable to spin coated films achieved **Trial Distance (cm) Concentration (mg/mL) Spray Time (min) Dry Time (min)
Spray
Cycles Transparency (avg %) Sheet Resistance (Ω/sq)** 1 5 0.5 5 15 1 50 % 18. 2 8 0.5 6.5 30 13 75 % 21.9-36. 3 8 0.5 4 15 1 75 % 474. 4 6 0.5 3 15 1 80 % 693. 5 8 0.125 10 40 20 95 % To high to measure Solvent input lines Pneumatic valves Pressure gauge (^) Substrate Compressed air lines Spray nozzle (a) AgNW Spray Parameters and Optimization Results
- I. J. Kramer, J. C. Minor, G. Moreno-Bautista, L. Rollny, P. Kanjanaboos, D. Kopilovic, S. M. Thon, G. H. Carey, K. W. Chou, D. Zhitomirsky, A. Amassian, E. H. Sargent. Efficient Spray Coated Colloidal Quantum Dot Solar Cells. Advanced Materials 10.1002/adma.201403281 (2015).
- K. Zilberberg, F. Gasse, R. Pagui, A. Polywka, A. Behrendt, S. Trost, R. Heiderhoff, P. Görrn, T. Riedl. Highly Robust Indium-Free Transparent Conductive Electrodes Based on Composites of Silver Nanowires and Conductive Metal Oxide. Advanced Functional Materials 10.1002/adfm.201303108, 1671-1678 (2014)
- D. Choi, H. Kang, H. Sung and S. Kim. Annealing-Free, Flexible Silver Nanowire–Polymer Composite Electrodes via a Continuous Two-Step Spray-Coating Method. Nanoscale 10.1039/c2nr32221h (2012)
- M. Yuan, M. Liu, E. H. Sargent. Colloidal Quantum Dot Solids for Solution-Processed Solar Cells. Nature Energy , Vol. 1, Article 16016, 10.1038/nenergy.2016.16 (2016)
Optimization Landscape of a Neural Network Model for Activity Recognition Ksenia Lekomtceva 1, , Connor Lane 2 , Effrosyni Mavroudi 2 , René Vidal 2 1 Montgomery College, 2 Center for Imaging Science, Johns Hopkins University Conclusions and Future Research … Synthetic data Experiment and Results Project Hypotheses Motivation and Problem Statement
- The introduction of deep learning has led to remarkable improvements in performance across many tasks, including activity recognition.
- However, a solid theoretical understanding of deep learning models’ worst-case performance is needed to avoid failures in sensitive applications. Problem Statement: Recent theoretical work provides performance guarantees for some neural networks. Do they perform better? Model and Optimization Problem A single hidden layer neural network model with multiple tunable parameters W: Neural network training solves the optimization problem, given training data: This procedure can potentially get stuck in bad local minima due to the non-convex character of the optimization problem (right): Optimization Theory According to recent theoretical work [2], we can guarantee that bad local minima do not exist if the following three properties are satisfied:
- Over-parameterization (many hidden units):
- Regularization (control weight size):
- Positive Homogeneity (predictable effect of scaling): Activity Recognition Experiment and Results SVM Deep Learning Network Pre-Deep Learning 61.7% [1] Current 80.7% (both on HMDB-51) Input (^) Input input output hidden layer loss Optimized by making small repeated updates to the parameters W: Classic Machine learning: convex (^) Deep learning: non-convex Loss Loss α (^) α First, the hypotheses were tested in a well-controlled “ideal” setting: The plots show the (regularized) loss of the model with 60 (ground truth size), 120, 240, and 480 hidden units: Task: mirror behavior of “black-box” network
- Unlimited randomly generated data
- Access to “ground truth” parameters W that generated the data (Gaussian) (target scalar) (predicted scalar) Regularization Positive homogeneity Regularization Positive homogeneity Regularization Positive homogeneity Loss + reg Loss + reg Loss Iteration Iteration Iteration Conclusion: H1 supported
- Over-parameterization with positive homogeneity improves optimization.
- Regularization not necessary is it possible the theory can be generalized? Next, the hypotheses were tested in a realistic activity recognition setting using the Deep Moving Poselets [3], where the hidden layer captures discriminative movements of body parts: Task: classify actions from short video clips Regularization Positive homogeneity Regularization Positive homogeneity Regularization Positive homogeneity Loss + reg Loss + reg Loss Iteration Iteration Iteration Conclusion: H2 supported
- Over-parameterization, positive homogeneity, regularization do not affect optimization.
- Possible that optimization landscape is too easy to begin with. The plots show the (regularized) loss for the model with 200, 400, 800, and 1600 hidden units: Bad local minima ( ) do not exist: References: [1] J. Carreira and A. Zisserman, “Quo vadis, action recognition? A new model and the kinetics dataset,” in CVPR 2017, pp. 4724–4733. [2] B. Haeffele and R. Vidal, “Global optimality in neural network training,” in CVPR 2017, pp. 7331–7339. [3] E. Mavroudi, L. Tao, and R. Vidal, “Deep moving poselets for video based action recognition,” in WACV 2017 , pp. 111–120.
- For unlimited synthetic data, we find evidence that satisfying the theoretical conditions helps training avoid bad local minima.
- However, for activity recognition task, satisfying the theoretical conditions has no effect on training performance.
- In future work, we will explore possible explanations for this result, including dataset size, and data "realizability”. Acknowledgements: This research was supported by the NSF under Grant No. 1004782 “Swing”
- Only 227 training examples
- No “Ground truth” Does satisfying the theoretical properties improve performance in practice? Without theory (^) With theory H loss + reg Iteration Without theory With theory loss + reg Iteration Hypotheses H With theory Without theory swing (^) swing (predicted) (target)