Download Face recognization using PCA and more Study Guides, Projects, Research Linear Algebra in PDF only on Docsity!
ĐẠI HỌC QUỐC GIA THÀNH PHỐ HỒ CHÍ MINH
TRƯỜNG ĐẠI HỌC BÁCH KHOA
KHOA KHOA HỌC ỨNG DỤNG
BÁO CÁO BÀI TẬP LỚN
MÔN ĐẠI SỐ TUYẾN TÍNH
PHÂN TÍCH PCA ĐỂ NHẬN DIỆN KHUÔN MẶT
GVHD: NGUYỄN THỊ HOÀI THƯƠNG
LỚP: L
NHÓM SỐ: 3
DANH SÁCH THÀNH VIÊN:
STT HỌ VÀ TÊN MSSV
1
Dương Nguyễn Minh Huấn 2411158
2
Dương Bá Anh Quân 2412870
3
Đỗ Quốc Tưởng 2413901
4
Đoàn Tuấn Khang 2411429
5
Đoàn Ngô Phương Uyên 2051072
6
Đỗ Quốc Trường 2413734
Thành phố Hồ Chí Minh - 2024
LỜI CẢM ƠN
Trong quá trình hoàn thiện báo cáo nhóm chúng em đã gặp không ít khó khăn bởi lần đầu còn nhiều bỡ
ngỡ nhưng nhờ có sự giúp đỡ nhiệt tình từ cô và các bạn đã giúp nhóm chúng em có thể hoàn thành báo cáo
một cách tốt nhất. Nhóm xin gửi lời tri ân và cảm ơn chân thành nhất đến cô Nguyễn Thị Hoài Thương là giảng
viên bộ môn Đại Số Tuyến Tính của Trường Đại học Bách K hoa TP.HCM cũng như là giáo viên hướng dẫn
nhóm thực hiện đề tài này. Nhờ sự tận tình, hết lòng giảng dạy và truyền đạt những lý thuyết, kiến thức quan
trọng một cách kĩ càng để chúng em có một nền tảng kiến thức vững chắc để thực hiện báo cáo. Không chỉ
vậy, cô còn gợi ý cho nhóm các bước cần thiết và quan trọng, nhờ đó nhóm đã hoàn thành báo cáo đúng tiến độ
và đúng theo yêu cầu được đưa ra.. Sự hướng dẫn của cô chính là kim chỉ nam chỉ dẫn cho nhóm chúng em
phương hướng để tìm hiểu và hoàn thành báo, giúp các thành viên trong nhóm có thể phát huy được hết khả
năng tiềm ẩn của bản than.
Lời cuối, nhóm chúng em xin một lần nữa gửi lời cảm ơn sâu sắc đến cô và mọi người
đã dành thời gian giúp đỡ, góp ý cho nhóm. Đây chính là nguồn động lực to lớn để nhóm
có thể hoàn thành và đạt được kết quả này.
Chân thành cảm ơn sự giúp đỡ của cô và mọi người rất nhiều!
MỤC LỤC
- LỜI CẢM ƠN - LỜI MỞ ĐẦU
- PHẦN 1: TỔNG QUAN VỀ HỆ THỐNG NHẬN DIỆN KHUÔN MẶT
- 1.1. Hệ thống sinh trắc học - 1.1.1 Định nghĩa - 1.1. 2 Tổng quan lịch sử và vai trò
- 1 .2. Hệ thống nhận diện khuôn mặt - 1 .2.1. Các pha trong nhận diện khuôn mặt - 1 .2.2. Ưu điểm và Nhược điểm:.....................................................................................................................................
- PHẦN 2: THUẬT TOÁN PCA TRONG NHẬN DIỆN KHUÔN MẶT...............................................................................................
- 2.1. Thuật toán PCA - 2 1 .1. Lịch sử ra đời:....................................................................................................................................................... - 2.1.2. Tổng quan về phương pháp PCA.......................................................................................................................... - 2.2.3. Ứng dụng.............................................................................................................................................................. - 2.2.4. Cơ sở lý thuyết
- 2.2. Thuật toán PCA trong Nhận diện khuôn mặt............................................................................................................ - 2.2.1. Các bước dùng PCA để Nhận diện khuôn mặt - 2.2.2. Ưu điểm và nhược điểm
- PHẦN 3: ỨNG DỤNG THUẬT TOÁN PCA TRONG NHẬN DIỆN KHUÔN MẶT BẰNG PYTHON
- 3 .1. Sơ đồ khối hoạt động của chương trình Nhận diện khuôn mặt
- 3 .2. CODE:
- 3.3. Kết quả:
- PHẦN IV: TÀI LIỆU THAM KHẢO
PHẦN 1 : TỔNG QUAN VỀ HỆ THỐNG NHẬN DIỆN KHUÔN
MẶT
1. 1. Hệ thống sinh trắc học
1. 1 .1 Định nghĩa - Sinh trắc học (biometric) là một lĩnh vực nghiên cứu và ứng dụng công nghệ liên quan đến việc xác minh
danh tính và nhận dạng con người dựa trên các đặc điểm sinh học duy của họ các đặc điểm sinh học này có thể
bao gồm vân tay, giọng nói, khuôn mặt, chữ viết. Sinh trắc học được thay thế hoặc bổ sung cho các phương
pháp xác minh danh tính truyền thống như thẻ mật khẩu, thẻ thông tin hoặc mã PIN. Lĩnh vực này sử dụng các
công nghệ tiên tiến để thu thập và phân tích các đặc điểm sinh học của con người như cảm biến sinh học, hình
ảnh y học, cùng với các kỹ thuật đo lường để thu thập dữ liệu về các chỉ số sinh học, như nhịp tim, nhiệt độ cơ
thể và lưu trữ trong một cơ sở dữ liệu. Do vậy việc bảo mật sinh trắc rất thuận tiện và an toàn. Sinh trắc học
không chỉ nâng cao kiến thức của chúng ta về cơ thể còn người mà còn được ứng dụng vào nhiều lĩnh vực như
thể thao,y học, công nghiệp,…
1. 1. 2. Tổng quan lịch sử và vai trò
- Trong các thập kỷ trở lại đậy công nghệ đang phát triển rất nhanh và phổ cập với phần lớn người dân các
nước. Nhưng bên cạnh đó mang lại những rủi ro về quyền riêng tư, thông tin cá nhân và dữ liệu người dùng.
Thế nên đòi hỏi con người cần tìm ra một phương thức bảo mật thông tin và dữ liệu giúp xác minh danh tính
và đáng tin cậy. Sinh trắc học được tạo ra để làm lời giải cho bài toán bảo mật thông tin của con người.
1 .1.2.1. Lịch sử:
Hình 1: Dấu vân tay được chụp William Herschel
- Sinh trắc học là một trong những ngành khoa học lâu đời. Khái niệm này được bắt nguồn từ tiếng Anh
“biometry” hoặc tiếng Pháp “biometrie”. Nhưng vào năm 1831 thuật ngữ này được W. Whewell sử dụng để
tìm hiểu tính quy luật về tuổi thọ của những người mà ông nghiên cứu. Đến năm 1901 sinh trắc học đã được F.
Galton gọi là Biometrika hình thành và định nghĩa.
- Vào những năm 5000 TCN ở Babylon đã xuất hiện những ghi chép sớm nhất về việc lấy dấu vân tay để nhận
dạng, dấu vân tay ở đây được sử dụng để ký tên trên các tài liệu đất sét. Tại Châu Á các thương nhân người
Trung Quốc cũng đã biết dùng dấu vân tay để chứng thực tài liệu và nhận diện con người từ hàng nghìn năm
trước Công Nguyên.
- Đối với các hệ thống bậc còn có thể nhận diện xuyên qua các lớp khẩu trang hay trang điểm
- Có thể cùng lúc nhận diện được nhiều người
1 .2.2.2. Nhược điểm:
- Một số người sẽ cảm thấy không thoải mái khi khuôn mặt mình bị làm giả
- có thể nhận dạng không chính xác và dễ dàng bị làm giả
- Chi phí tốn kém
PHẦN 2 : THUẬT TOÁN PCA TRONG NHẬN DIỆN KHUÔN MẶT
2.1. Thuật toán PCA
2. 1 .1. Lịch sử ra đời:
- Phân tích thành phần chính (Principal Component Analysis - PCA) được trình bày theo nhiều quan điểm khác
nhau. Với các nhà thống kê cổ điển thì PCA là tìm các trục chính của ellipsoid nhiều chiều bao hàm đám mây
số liệu phân phối chuẩn nhiều chiều, các trục đó được ước lượng từ một mẫu n cá thể, trên mỗi cá thể người ta
đo p chỉ tiêu. Người đầu tiên đưa ra kỹ thuật này là H.Hotelling (1933), sau đó là T.W.Anderson (1958) và
A.M.Kshirsagar (1972).
- Với các nhà nhân tố học cổ điển thì kỹ thật này là phương pháp phân tích nhân tố trong trường hợp đặc biệt,
khi các phương sai này bằng không hoặc xấp xỉ bằng không. Phương pháp này thường được sử dụng trong
phân tích tâm lý, do Horst (1965) và Harman (1966) đề xuất. - Sau cùng, theo quan điểm phổ biến hơn cả của
các nhà phân tích số liệu thì PCA là một kỹ thuật biểu diễn các số liệu một cách tối ưu theo một tiêu chuẩn đại
số và hình học đặc biệt. khi sử dụng kỹ thuật này người ta không đòi hỏi một giả thuyết thống kê hoặc một mô
hình đặc biệt nào. Quan điểm này trở nên phổ biến từ khi có máy tính điện tử, và là quan điểm mới nhất.
Những tư tưởng của phương pháp này do K.Pearson (1901) đề xuất. Trong công trình của C.R Rao (1964) nội
dung lý thuyết của phương pháp PCA được trình bày khá đơn giản và rõ ràng.
- Lĩnh vực ứng dụng của phương pháp PCA rất rộng trong công nghiệp, nông nghiệp, kinh tế, khoa học cơ
bản… với bảng số liệu mà các cột là các biến và các dòng là các cá thể, trên đó đo giá trị của biến.
2.1.2. Tổng quan về phương pháp PCA
- Phân tích thành phần chính (Principal Component Analysis) hay còn gọi là PCA là một trong những kết quả
đẹp từ việc áp dụng đại số tuyến tính. PCA được sử dụng nhiều trong các khuôn mẫu phân tích bởi vì nó là
phương pháp không cần tham số và đơn giản hóa cho việc trích xuất thông tin thích hợp từ các tập dữ liệu
không rõ ràng. PCA cung cấp một hướng đi cho việc làm thế nào để hạn chế một tập dữ liệu phức tạp tới một
tập dữ liệu với số chiều nhỏ hơn để thể hiện ra thông tin ẩn dưới tập dữ liệu không rõ ràng đó.
- Để hiểu rõ và phân tích một hiện tượng nào đó, ta thường đo lường một vài đại lượng trong hệ thống. Ta có
thể không tính toán được điều gì đã xảy ra do dữ liệu đo được rất mù mờ, không rõ ràng, số lượng các biến đo
lường có thể rất lớn và tại các thời điểm khác nhau cũng có thể dễ gây nhầm lẫn. Thuật toán PCA rất hữu dụng
trong những trường hợp này. Nó có thể biến đổi tập dữ liệu đo lường dư thừa, nhiễu lớn về tập dữ liệu mà biểu
diễn tốt nhất (dễ quan sát nhất, dễ phân biệt nhất) hệ thống. Với một hệ thống liên tục và tuyến tính nếu ta đưa
các đo lường vào một không gian vecto nơi mà mỗi thể hiện của hệ thống được xem như một vector trong
không gian vector đó (số các vecto cơ sở là số chiều của không gian đó). Ta sẽ sử dụng phép biến đổi tuyến
tính để ánh xạ tập dữ liệu gốc vào tập dữ liệu mới có giảm sự dư thừa và nhiễu dữ liệu.
- Tổng quan về phương pháp PCA. PCA là phương pháp:
- Loại bỏ thành phần phụ
- Giữ thành phần chính
- Không ảnh hưởng nhiều dữ liệu so với dữ liệu gốc
- Lợi ích của phương pháp PCA:
- Giảm chiều dữ liệu nhưng vẫn giữ được độ chính xác nhất định so với dữ liệu ban đầu
- Dễ quan sát, nắm bắt thông tin, nhận biết sự tương quan
- Giúp ta tính toán nhanh hơn với độ chính xác cao
2.2.3. Ứng dụng
- Phương pháp Principle Component Analysis (PCA) là một kỹ thuật thống kê để giảm số chiều của dữ liệu mà
vẫn giữ được các đặc trưng quan trọng của dữ liệu. PCA có nhiều ứng dụng trong đời sống, ví dụ như Công
nghệ thông tin, Sinh học…
- Nhận dạng khuôn mặt: PCA có thể giúp trích xuất các đặc trưng chính của khuôn mặt từ các ảnh và
sử dụng chúng để phân biệt các khuôn mặt khác nhau.
- Phân tích dữ liệu nhiều chiều: PCA có thể giúp giảm số lượng các biến trong dữ liệu và tạo ra các
biến mới không tương quan với nhau. Điều này giúp cho việc phân tích dữ liệu dễ dàng và hiệu quả hơn.
- Trực quan hóa dữ liệu: PCA có thể giúp biểu diễn dữ liệu nhiều chiều trên các đồ thị hai hoặc ba
chiều, giúp cho việc nhìn nhận và hiểu dữ liệu trở nên rõ ràng hơn. 19 4. Nén dữ liệu: PCA có thể giúp giảm
dung lượng lưu trữ của dữ liệu mà vẫn giữ được các thông tin cần thiết.
2.2.4. Cơ sở lý thuyết
2.2.4.1. Khái niệm của PCA
- Phép phân tích thành phần chính PCA (Principal Pomponent Analysis) Là một kỹ thuật giảm chiều dữ
liệu nhằm giữ lại những thông tin quan trọng nhất của dữ liệu ban đầu. Bằng cách biến đổi trực giao dữ
liệu từ không gian ban đầu có nhiều chiều thành không gian ít chiều hơn. Cách tiếp cận này giúp giữ lại
các thông tin quan trọng nhất, hỗ trợ phân tích các đặc điểm chính của dữ liệu và xây dựng các mô hình
dự đoán hiệu quả.
𝜎
2
=
1
𝑛 − 1
∑(𝑋
𝑖
− 𝑋
̅
)
2
𝑛
𝑖= 1
2
: Phương sai mẫu của tập dữ liệu.
𝑖
: Các giá trị của phần tử thứ i trong tập dữ liệu.
: Giá trị trung bình các giá trị trong tập dữ liệu.
𝑛: Số lượng phần tử trong tập dữ liệu.
𝑛 − 1 : Là bậc tự do, giúp điều chỉnh độ lệch khi lấy mẫu từ tổng thể
2 .2.4.3.3. Hiệp phương sai (covariance):
Là một đại lượng đo mức độ liên hệ giữa hai biến số, cho biết chúng thay đổi cùng chiều hay ngược chiều với
nhau nói cách khác là mối quan hệ biến thiên của hai biến.
Giả sử ta có hai biến 𝑋, 𝑌 ngẫu nhiên, mỗi biến có n giá trị. Vậy công thức tính hiệp phương sai sẽ là:
𝐶𝑜𝑣(𝑋, 𝑌) =
1
𝑛 − 1
∑(𝑋
𝑖
− 𝑋
̅
𝑛
𝑖= 1
)(𝑌
𝑖
− 𝑌
̅
)
Cov(X,Y): Hiệp phương sai giữa hai biến X và Y
𝑖
𝑣à 𝑌
𝑖
: Lần lượt là các giá trị phần tử thứ i trong tập dữ liệu 𝑋 𝑣à 𝑌
𝑣à 𝑌
: Giá trị trung bình của 𝑋 𝑣à 𝑌
𝑛: Số lượng phần tử trong tập dữ liệu
Giá trị hiệp phương sai không quan trọng bằng dấu của nó
- Nếu giá trị hiệp phương sai mang giá trị dương thì 𝑋 và 𝑌 tăng hoặc giảm cùng nhau
- Nêu giá trị hiệp phương sai mang giá trị âm thì 𝑋 tăng 𝑌 khi giảm hoặc ngược lại
- Nếu giá trị hiệp phương sai bằng không thì 𝑋 và 𝑌 độc lập tuyến tính
2 .2.4.3.4_. Ma trận hiệp phương sai (covariance matrix):_
- Liên quan đến việc đo lường mức độ tương quan giữa các biến số trong một tập dữ liệu. Nó cho phép ta
xác định xem các biến có thay đổi cùng chiều hay ngược chiều, từ đó giúp phân tích mối quan hệ giữa
chúng.
- Ma trận hiệp phương sai là ma trận đối xứng, bán xác định dương. Tính chất này đảm bảo tìm ra các
trục mới sao cho phương sai của dữ liệu trên các trục mới là mới nhất
- Mọi phần tử trên đường chéo của ma trận hiệp phương sai đều là các giá trị không âm và đại diện cho
phương sai của từng chiều dữ liệu tương ứng.
- Nếu ma trận hiệp phương sai là ma trận đường chéo, ta có dữ liệu hoàn toàn không tương quan giữa các
chiều.
𝑆 =
1
𝑛 − 1
𝑋
𝑇
𝑋
S là ma trận hiệp phương sai
𝑋 là ma trận dữ liệu đã chuẩn hóa
𝑇
là ma trận chuyển vị của 𝑋
𝑛 − 1 là bậc tự do (được sử dụng để điều chỉnh khi tính toán hiệp phương sai mẫu)
2 .2.4.3.5_. Trị riêng (eigenvalue)_
- Được sử dụng để đo mức độ biến đổi của dữ liệu theo các hướng khác nhau.
- Mỗi trị riêng là mỗi đặc trưng cho mức độ biến đổi của mỗi hướng cụ thể của không gian dữ liệu.
- Khi sắp xếp các trị riêng theo thứ tự giảm dần. Các trị riêng lớn nhất đại diện cho các thành phần chính
của dữ liệu, tức là các hướng trong không gian mà biến đổi dữ liệu nhiều nhất. Các trị riêng nhỏ đại
diện cho các thành phần ít quan trọng hơn.
- Giải phương trình đặc trưng:
det(S − I) = 0
𝑆: Ma trận hiệp phương sai của 𝑋
𝐼: Ma trận đơn vị
: Trị riêng của ma trận S
- Nghiệm của phương trình là đặc trưng của trị riêng.
- Mỗi trị riêng có thể có nhiều vectơ riêng nhưng mỗi vectơ riêng chỉ ứng với một trị riêng
2 .2.4.3.6_. Vecto trị riêng (eigenvector)_
- Là một vectơ trong không gian vectơ mà khi nhân với một ma trận, vectơ chỉ thay đổi độ dài mà không
đổi hướng.
- Vectơ riêng tương ứng với giá trị riêng lớn nhất thường sẽ chỉ ra hướng mà ma trận biến đổi nhiều nhất,
ngược lại, các vectơ riêng ứng với các giá trị riêng nhỏ thường chỉ ra các hướng mà ma trận biến đổi ít
hơn.
- Giải phương trình thuần nhất:
(S − I). v = 0
- Tìm vectơ riêng v, trị riêng
i
v là vector riêng của
T
A A và
i
là trị riêng tương ứng, khi đó ta có:
T
i i i
A Av = v
T
i i i
AA Av = A v
T
i i i
AA Av = Av
→ Ta thấy,
i
Av
chính là vector riêng của ma trận
T
AA
2. 2 .1. 4. Không gian khuôn mặt riêng
Sau khi có các vector riêng của ma trận
T
AA , ta sẽ chuẩn hóa chúng để thu được một cơ sở trực chuẩn của
không gian khuôn mặt:
T
C = A A có kích thước m m , với v là tập hợp các vector riêng của C và D là tập hợp
các trị riêng tương ứng.
vector riêng ứng với R
trị riêng lớn nhất trong
D
- E = Av là tập các vector riêng của
T
AA. Mỗi cột trong E là một vector riêng ứng với một khuôn mặt
riêng (Eigenfaces) trong không gian khuôn mặt.
- Chuẩn hóa các vector cột trong E
(chia mỗi vector cho độ dài của vector đó).
→ Lúc này, ta có thể coi E là một cơ sở trực chuẩn của không gian khuôn mặt.
2.2.1.5. Nhận diện ảnh
là bức ảnh có cùng kích thước với những bức ảnh trong tập huấn luyện. Ta sẽ xét xem nó có phải là
bức ảnh khuôn mặt hay không, cũng như tìm bức ảnh giống với nó nhất trong tập huấn luyện.
H
được xem là một vector trong không gian M N chiều. Đặt K = H − n (với
n
là vector ảnh trung bình).
- Giả sử Wlà một không gian con của v và có một cơ sở trực chuẩn là
1
{u ,..., }
R
u. Khi đó hình chiếu
trực giao của vector u bất kỳ lên Wđược xác định như sau:
W
1
Pr
R
o i i
i
u u u u u
=
- Tích vô hướng giữa vector u
bất kì với vector thứ i trong cơ sở trực chuẩn của
W
được sử dụng để
xác định khoảng cách giữa ảnh H và không gian khuôn mặt.
T
S = E K là tọa độ hình chiếu
f
K
của K lên không gian khuôn mặt.
i
là một cột trong ma trận A (tương ứng với bức ảnh
i
T trong tập huấn luyện).
Ta tính
T
i i
S = E
là tọa độ của hình chiếu
if
của
i
lên không gian khuôn mặt.
- Tính toán hai đại lượng quan trọng:
f
x = K − K : khoảng cách từ bức ảnh H đến không gian khuôn mặt.
i i
x = S − S : khoảng cách từ bức ảnh H
đến bức ảnh
i
T trong tập huấn luyện.
- Quyết định dựa trên ngưỡng và nào đó:
+ Nếu x thì H là bức ảnh khuôn mặt ( do H đủ gần với khuôn mặt)
i
x thì H là bức ảnh của cùng một người với
i
T ( H đủ gần với
i
T ).
- Vậy là ta đã có thể tìm bức ảnh trong tập huấn luyện giống với bức ảnh H hay xác định đó có phải là bức
ảnh khuôn mặt hay không.
- Bây giờ trong một bức ảnh H có nhiều khuôn mặt hơn. Tại mỗi vị trí ( , x y ), một vùng con của H được
xem xét, biểu diễn thành vector M N.
K x y ( , ) = H x y ( , )− n ;
f
K x y là hình chiếu của K x y ( , )lên không gian khuôn mặt.
f
s x y = K x y − K x y.
- Facemap: Tập hợp các giá trị s x y ( , )tạo thành một bản đồ giúp xác định vị trí của khuôn mặt trong
ảnh H
2.2.2. Ưu điểm và nhược điểm
2.2. 2. 1. Ưu điểm:
- Dễ cài đặt, nếu ta xét bài toán tìm khuôn mặt giống nhau thì ta chỉ cần áp dụng hoàn toàn theo lý thuyết
đã có độ chính xác khá cao, nếu áp dụng cho bài toán tìm vị trí khuôn mặt thì cần phải có một thuật
toán nữa để sử dụng face map thu được theo lý thuyết.
- Tìm được các đặc tính tiêu biểu của đối tượng cần nhận dạng mà không cần phải xác định các thành
phần và mối quan hệ giữa các thành phần đó.
- Thuật toán có thể thực hiện tốt với các ảnh có độ phân giải cao, do PCA sẽ làm giảm chiều dữ liệu của
ảnh xuống mức thấp nhất có thể.
- PCA có thể kết hợp với các phương pháp khác như mạng Noron, Support Vector Machine … để mang
lại hiệu quả nhận dạng cao hơn.
2.2. 2 .2. Nhược điểm:
- Các mẫu khuôn mặt hoàn toàn phụ thuộc vào tập huấn luyện, có nghĩa là các khuôn mặt trong ảnh kiểm
tra phải giống với các ảnh huấn luyện về kích thước, tư thế, độ sáng. Thực tế trong tập huấn luyện
thường gồm nhiều nhóm hình, mỗi nhóm là hình của một người với tư thế, độ sáng khác nhau.
- PCA phân loại theo chiều phân bố lớn nhất của tập vector. Tuy nhiên, chiều phân bố lớn nhất không
phải lúc nào cũng mang lại hiệu quả tốt nhất cho bài toán nhận dạng. Đây là nhược điểm cơ bản của
PCA.
PHẦN 3 : ỨNG DỤNG THUẬT TOÁN PCA TRONG NHẬN DIỆN
KHUÔN MẶT BẰNG PYTHON
3 .1. Sơ đồ khối hoạt động của chương trình Nhận diện khuôn mặt
1. Bắt đầu : Khởi động quy trình nhận diện khuôn mặt
- trainPath = 'd:/NEW CHAPTER/241/DSTT/face_recognize/database'
- checkPath = 'd:/NEW CHAPTER/241/DSTT/face_recognize/datain'
- datain = os.listdir(os.path.expanduser(checkPath))
- csdl = os.listdir(os.path.expanduser(trainPath))
- def prepCSDL (trainPath):
- valid_file = []
- csdl = os.listdir(os.path.expanduser(trainPath))
- for i in csdl:
- if i.endswith('.jpg') or i.endswith('.png') or i.endswith('.jpeg'):
- valid_file.append(i)
- return valid_file
- valid_file = prepCSDL(trainPath)
- #tạo cơ sở dữ liệu
- def createCSDL (valid_file, target_size=( 128 , 128 )):
- #khởi tạo ma trận T
- T = []
- for i in valid_file:
- filepath = os.path.join(trainPath, i)
- try:
- img = Image.open(filepath).convert('L')
- img = img.resize(target_size)
- img_array = np.array(img)
- img_vector= img_array.flatten()
- T.append(img_vector)
- except Exception as e:
- print (f'Không có dữ liệu!')
- T = np.column_stack(T)
- return np.array(T)
- def pca (T):
- #tìm kỳ vọng (mean) của tất cả CSDL trong ma tận T
- m = np.mean(T, axis= 1 , keepdims=True)
- soanh = T.shape[ 1 ]
- plt.imshow(m.reshape( 128 , 128 ), cmap='gray') # Giả sử ảnh có kích thước 28x28, thay đổi tùy vào kích thước ảnh
của bạn
- plt.title('Anh trung binh')
- plt.show()
- #tìm phương sai của mỗi ảnh so với kỳ vọng
- A = []
- for i in range (soanh):
- d = np.sqrt(soanh)
- m = np.repeat(m, d, axis= 1 )
- temp = T - m
- if i < 1 :
- plt.imshow(temp.reshape( 256 , 192 ), cmap='gray')
- plt.title('Anh - Anh TB')
- plt.show()
- A.append(temp)
- A = np.column_stack(A)
- #tìm ma trận hiệp phương sai L = A' * A
- L = A.T @ A
- #tìm vector riêng và trị riêng
- D, V = np.linalg.eig(L)
Sắp xếp các giá trị riêng giảm dần và chọn các vector riêng lớn nhất
- idx = np.argsort(D)[::- 1 ] # Sắp xếp giảm dần
- V = V[:, idx]
- D = D[idx]
- D_sorted = np.sort(D)
- s = len(D_sorted)
- D1 = D_sorted[s- 9 ]
Lọc và chỉ lấy num_eigenfaces vector riêng lớn nhất
- LeigV = []
- for i in range(V.shape[ 1 ]):
- if D[i] > D1:
- LeigV.append(V[:, i])
- LeigV = np.array(LeigV).T
5. Tính các Eigenfaces từ các vector riêng của A*A' bằng cách A * LeigV
- E = A @ LeigV
Chuẩn hóa các vector Eigenfaces để tạo cơ sở trực chuẩn
- for i in range( 3 ):
- eigenface = np.real(E[:, i].reshape(( 128 , 128 )))
- plt.imshow(eigenface, cmap='gray')
- plt.title('Eigenface')
- plt.show()
- plt.pause( 1 )
- num_vectors = E.shape[ 1 ]
- for i in range(num_vectors):
- E = E / np.linalg.norm(E, axis= 0 , keepdims=True)
- return m, A, E # Trả về ảnh trung bình, ma trận độ lệch và các Eigenfaces
- #ham nhan dien
- def faceRecognition (input, m, A, E):
- toado = []
- if file_path: # Nếu người dùng chọn một tệp
- TestImage = cv2.imread(file_path) # Đọc hình ảnh cần kiểm tra (giữ lại ảnh màu)
- cv2.imshow("Image to Recognize", TestImage) # Hiển thị hình ảnh cần nhận diện
- input = Image.open(file_path).convert('L')
- valid_file = prepCSDL (trainPath)
Tải CSDL huấn luyện
- T = createCSDL(valid_file) # Tạo cơ sở dữ liệu từ hình ảnh huấn luyện
Tạo Eigenfaces
- m, A, E = pca(T) # Tạo Eigenfaces và lấy trung bình
Nhận diện hình ảnh
- output = faceRecognition(input, m, A, E)
- print("Sinh Viên:", output)
- anhtim_path = trainPath + '/' + output # Tạo đường dẫn đến hình ảnh tìm được
- anhtim = cv2.imread(anhtim_path) # Đọc hình ảnh tìm được (giữ lại ảnh màu)
- cv2.imshow("Matched Image", anhtim) # Hiển thị hình ảnh tìm được
- cv2.waitKey( 0 ) # Chờ người dùng nhấn phím
- cv2.destroyAllWindows() # Đóng tất cả cửa sổ
- if name == "main": # Nếu đây là file chính
- main() # Gọi hàm main để bắt đầu chương trình
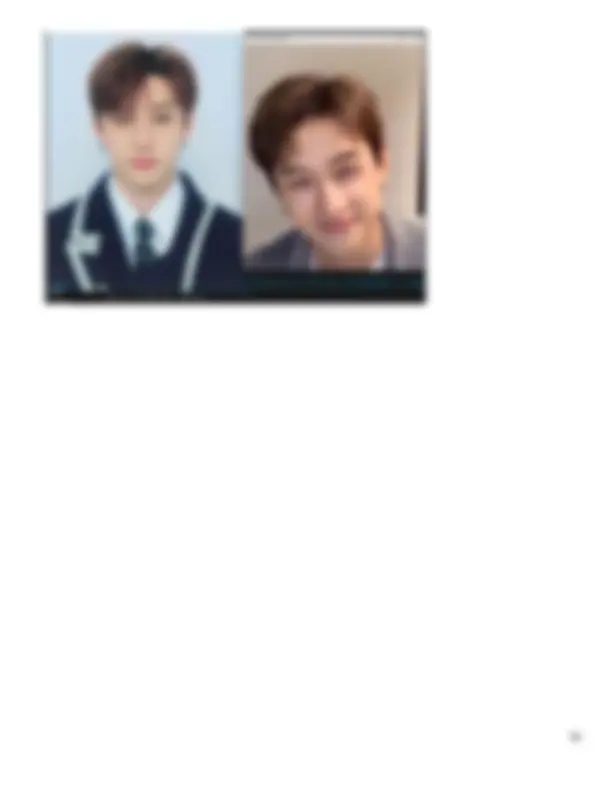
3. 3. Kết quả: