



Part I
Fundamental Concepts
Docsity.com

































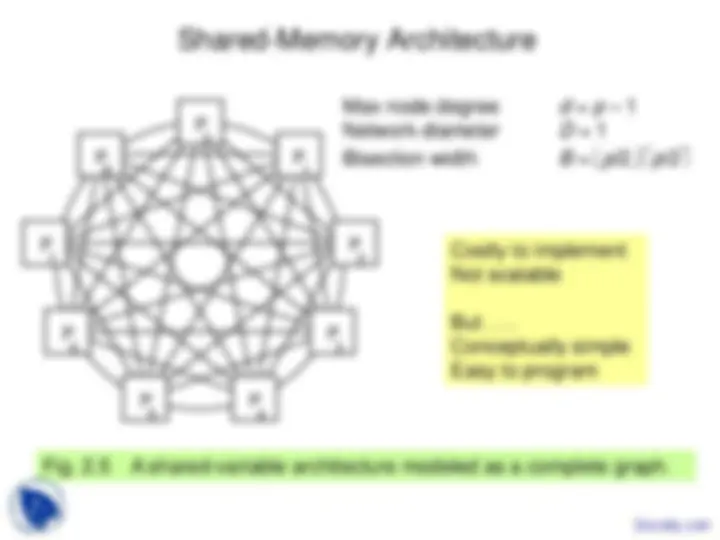



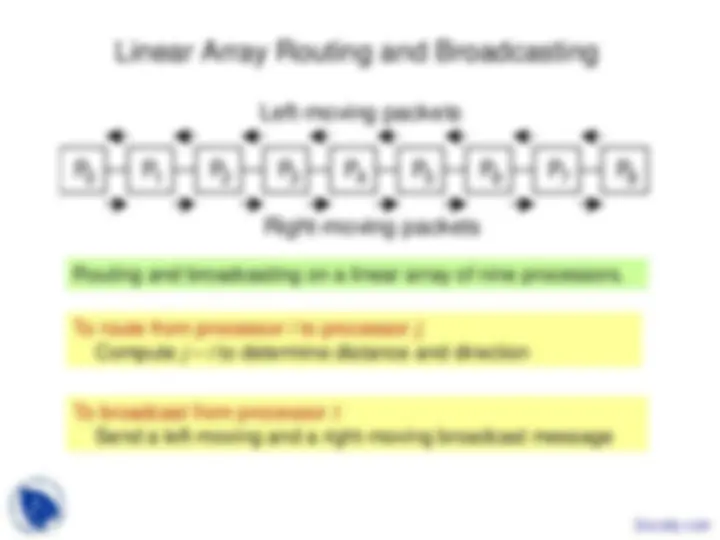


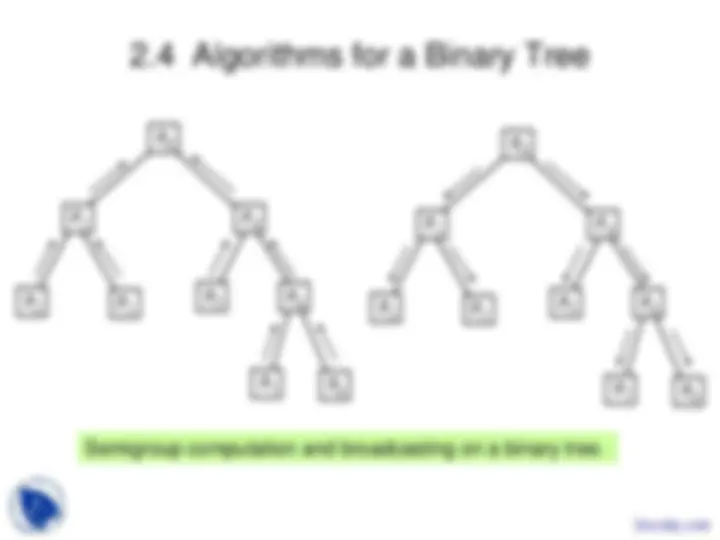



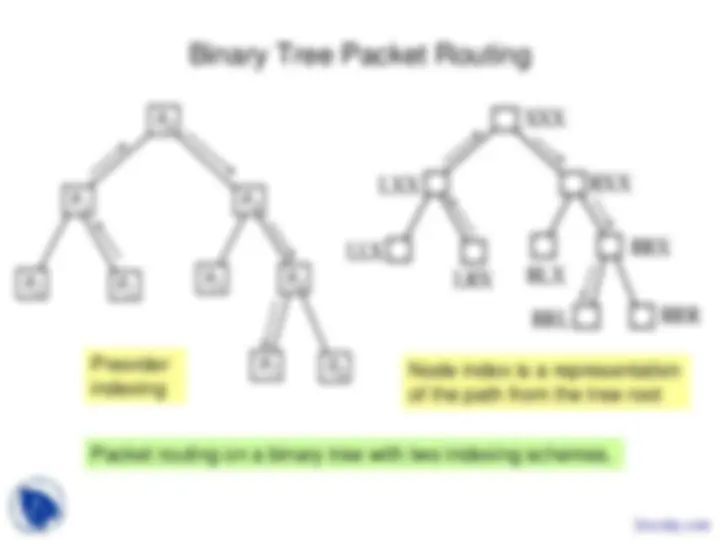





























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Some concept of Parallel Processing are Anatomy, Cache Access Time, Instruction Formats, Instruction Formats, Instruction Formats, Multidimensional Meshes, Network Processors, Snooping Protocol. Main points of this lecture are: Fundamental Concepts, Taxonomy, Tools For Evaluation, Comparison, Theory, Delineate, Hard Problems, Introduction to Parallelism, Taste of Parallel Algorithms, Parallel Algorithm Complexity
Typology: Slides
1 / 97

This page cannot be seen from the preview
Don't miss anything!
1.1 Why Parallel Processing?
Fig. 1.1 The exponential growth of microprocessor performance, known as Moore’s Law, shown over the past two decades (extrapolated).
1980 1990 2000 2010
KIPS
MIPS
GIPS
TIPS
Processor performance
Calendar year
80286
68000
80386
80486 68040
Pentium
Pentium II R
×1.6 / yr
2020
Projection, circa 1998 Projection, circa 2012
The number of cores has been increasing from a few in 2005 to the current 10s, and is projected to reach 100s by 2020
From: “Robots After All,” by H. Moravec, CACM , pp. 90-97, October 2003.
Mental power in four scales
NRC Report (2011): The Future of Computing Performance: Game Over or Next Level?
Density
Perf’ce
Power
Cores
Clock
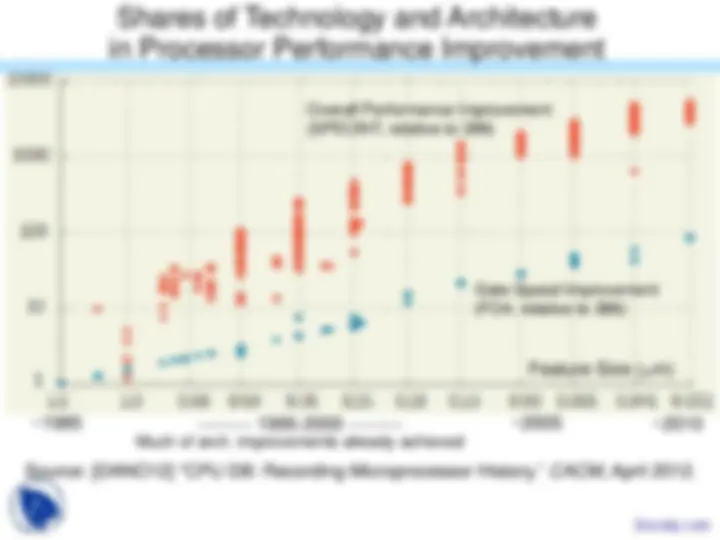
Source: [DANO12] “CPU DB: Recording Microprocessor History,” CACM , April 2012.
Feature Size (μm)
Overall Performance Improvement (SPECINT, relative to 386)
Gate Speed Improvement (FO4, relative to 386)
~1985 (^) --------- 1995-2000 --------- ~ Much of arch. improvements already achieved
~
Reasonable running time = Fraction of hour to several hours (10 3 -10 4 s) In this time, a TIPS/TFLOPS machine can perform 10 15 -10 16 operations
Example 2: Fluid dynamics calculations (1000 × 1000 × 1000 lattice) 10 9 lattice points × 1000 FLOP/point × 10 000 time steps = 10 16 FLOP
Example 3: Monte Carlo simulation of nuclear reactor 10 11 particles to track (for 1000 escapes) × 10 4 FLOP/particle = 10 15 FLOP
Decentralized supercomputing ( from Mathworld News , 2006/4/7 ): Grid of tens of thousands networked computers discovers 2 30 402 457 – 1, the 43rd Mersenne prime, as the largest known prime (9 152 052 digits )
Example 1: Southern oceans heat Modeling (10-minute iterations) 300 GFLOP per iteration × 300 000 iterations per 6 yrs = 10 16 FLOP
1995 2000 2005 2010
Performance (TFLOPS)
Calendar year
ASCI Red
ASCI Blue
ASCI White
1+ TFLOPS, 0.5 TB
3+ TFLOPS, 1.5 TB
10+ TFLOPS, 5 TB
30+ TFLOPS, 10 TB
100+ TFLOPS, 20 TB
1
10
100
1000 Plan^ Develop^ Use
ASCI
ASCI Purple
ASCI Q
Fig. 24.1 Milestones in the Accelerated Strategic (Advanced Simulation &) Computing Initiative (ASCI) program, sponsored by the US Department of Energy, with extrapolation up to the PFLOPS level.
LLNL, California NASA Ames, California Earth Sim Ctr, Yokohama
Material science, nuclear stockpile sim
Aerospace/space sim, climate research
Atmospheric, oceanic, and earth sciences
32,768 proc’s, 8 TB, 28 TB disk storage
10,240 proc’s, 20 TB, 440 TB disk storage
5,120 proc’s, 10 TB, 700 TB disk storage
Linux + custom OS Linux Unix
71 TFLOPS , $100 M 52 TFLOPS , $50 M 36 TFLOPS* , $400 M?
Dual-proc Power-PC chips (10-15 W power)
20x Altix (512 Itanium2) linked by Infiniband
Built of custom vector microprocessors
Full system: 130k-proc, 360 TFLOPS (est)
Volume = 50x IBM, Power = 14x IBM
Top Three Supercomputers in 2005 ( IEEE Spectrum , Feb. 2005, pp. 15-16)
ORNL, Tennessee LLNL, California RIKEN AICS, Japan
XK7 architecture Blue Gene/Q arch RIKEN architecture
560,640 cores, 710 TB, Cray Linux
1,572,864 cores, 1573 TB, Linux
705,024 cores, 1410 TB, Linux Cray Gemini interconn’t Custom interconnect Tofu interconnect
17.6/27.1 PFLOPS 16.3/20.1 PFLOPS 10.5/11.3 PFLOPS** *
AMD Opteron, 16-core, 2.2 GHz, NVIDIA K20x
Power BQC, 16-core, 1.6 GHz
SPARC64 VIIIfx, 2.0 GHz 8.2 MW power 7.9 MW power 12.7 MW power
Top Three Supercomputers in November 2012 (http://www.top500.org)
1.2 A Motivating
Example
Fig. 1.3 The sieve of Eratosthenes yielding a list of 10 primes for n = 30. Marked elements have been distinguished by erasure from the list.
Init. Pass 1 Pass 2 Pass 3 2 ← m 2 2 2 3 3 ← m 3 3 4 5 5 5 ← m 5 6 7 7 7 7 ← m 8 9 9 10 11 11 11 11 12 13 13 13 13 14 15 15 16 17 17 17 17 18 19 19 19 19 20 21 21 22 23 23 23 23 24 25 25 25 26 27 27 28 29 29 29 29 30
Any composite number has a prime factor that is no greater than its square root.
Fig. 1.4 Schematic representation of single-processor solution for the sieve of Eratosthenes.
1 2 n
Current Prime (^) Index P
Bit-vector