



Introduction to Parallel
Processing
Docsity.com




































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
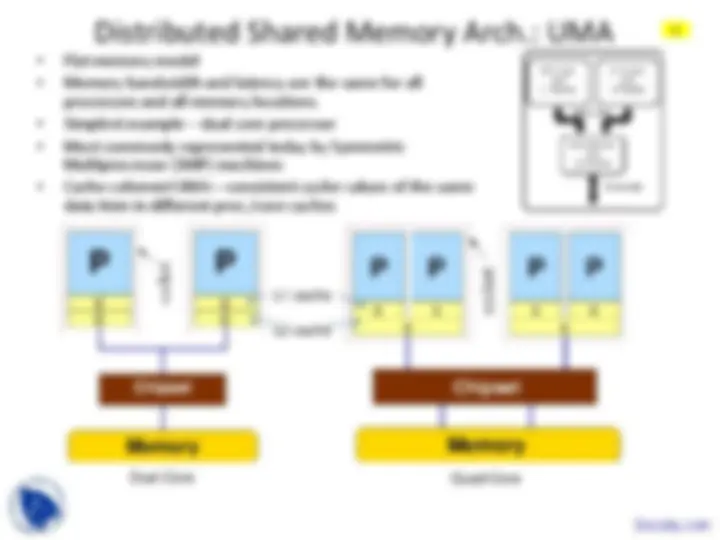
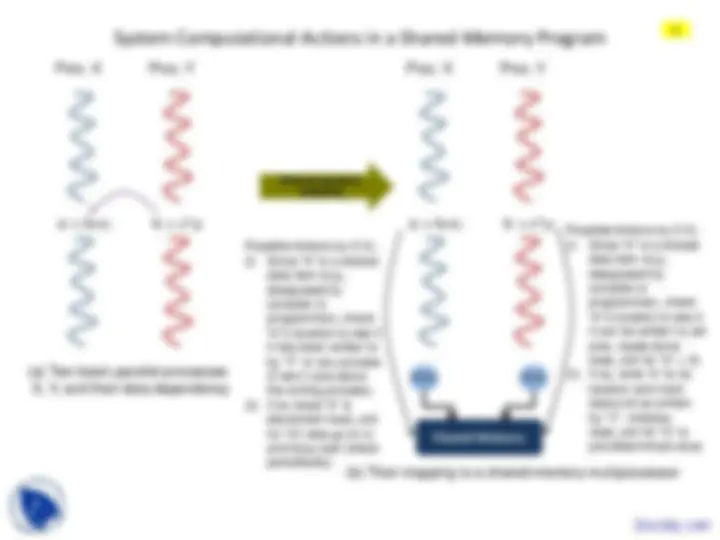
Some concept of Parallel Processing are Anatomy, Cache Access Time, Instruction Formats, Instruction Formats, Instruction Formats, Multidimensional Meshes, Network Processors, Snooping Protocol. Main points of this lecture are: Introduction, Moore'S Law and Its Limits, Different Uni-Processor Performance, Enhancement, Techniques and Their Limits, Classification, Parallel Computations, Parallel Architectures, Distributed, Parallel Processing
Typology: Slides
1 / 49

This page cannot be seen from the preview
Don't miss anything!
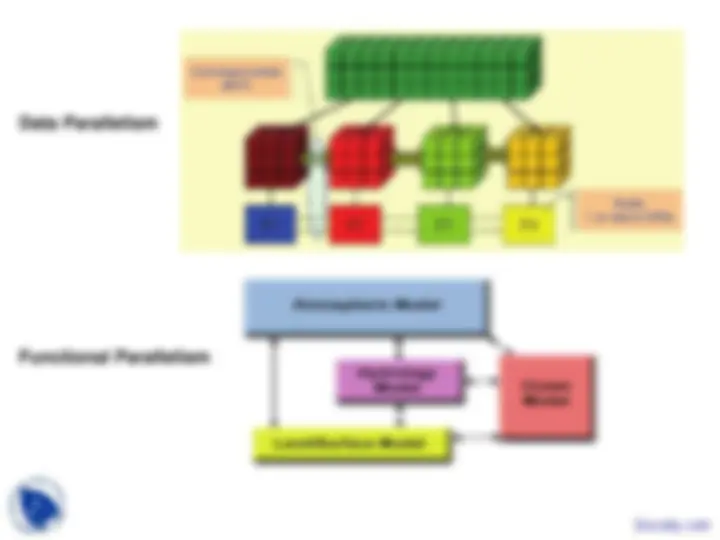
(exs. of limited data parallelism)
(exs. of limited & low-level functional parallelism)
(single-instr. multiple data)
: instruction-level parallelism—degree generally low and dependent on how the sequential code has been written, so not v. effective
based on a fundamental understanding of the parallelism inherent in a problem, and exploiting that parallelism with minimum interaction/communication between the parallel parts
(simultaneous multi- threading)
(multi-threading)