Download Understanding Hypothesis Testing & Probability in Statistical Data Analysis and more Slides Computational and Statistical Data Analysis in PDF only on Docsity!
G. Cowan Lectures on Statistical Data Analysis^1
Statistical Data Analysis: Lecture 5
1 Probability, Bayes’ theorem, random variables, pdfs 2 Functions of r.v.s, expectation values, error propagation 3 Catalogue of pdfs 4 The Monte Carlo method 5 Statistical tests: general concepts 6 Test statistics, multivariate methods 7 Goodness-of-fit tests 8 Parameter estimation, maximum likelihood 9 More maximum likelihood 10 Method of least squares 11 Interval estimation, setting limits 12 Nuisance parameters, systematic uncertainties 13 Examples of Bayesian approach 14 tba
G. Cowan Lectures on Statistical Data Analysis^2
Hypotheses
A hypothesis H specifies the probability for the data, i.e., the outcome of the observation, here symbolically: x. x could be uni-/multivariate, continuous or discrete. E.g. write x ~ f ( x | H ). x could represent e.g. observation of a single particle, a single event, or an entire “experiment”. Possible values of x form the sample space S (or “data space”). Simple (or “point”) hypothesis: f ( x | H ) completely specified. Composite hypothesis: H contains unspecified parameter(s). The probability for x given H is also called the likelihood of the hypothesis, written L ( x | H ).
G. Cowan Lectures on Statistical Data Analysis^4
Definition of a test (2)
But in general there are an infinite number of possible critical
regions that give the same significance level α.
So the choice of the critical region for a test of H 0 needs to take into account the alternative hypothesis H 1
Roughly speaking, place the critical region where there is a low probability to be found if H 0 is true, but high if H 1 is true:
G. Cowan Lectures on Statistical Data Analysis^5
Rejecting a hypothesis
Note that rejecting H 0 is not necessarily equivalent to the statement that we believe it is false and H 1 true. In frequentist statistics only associate probability with outcomes of repeatable observations (the data). In Bayesian statistics, probability of the hypothesis (degree of belief) would be found using Bayes’ theorem:
which depends on the prior probability π( H ).
What makes a frequentist test useful is that we can compute the probability to accept/reject a hypothesis assuming that it is true, or assuming some alternative is true.
G. Cowan Lectures on Statistical Data Analysis^7
Example setting for statistical tests:
the Large Hadron Collider
Counter-rotating proton beams in 27 km circumference ring pp centre-of-mass energy 14 TeV Detectors at 4 pp collision points: ATLAS CMS LHCb (b physics) ALICE (heavy ion physics) general purpose
G. Cowan Lectures on Statistical Data Analysis^8
The ATLAS detector
2100 physicists 37 countries 167 universities/labs 25 m diameter 46 m length 7000 tonnes ~ 8 electronic channels
Lectures on Statistical Data Analysis 10
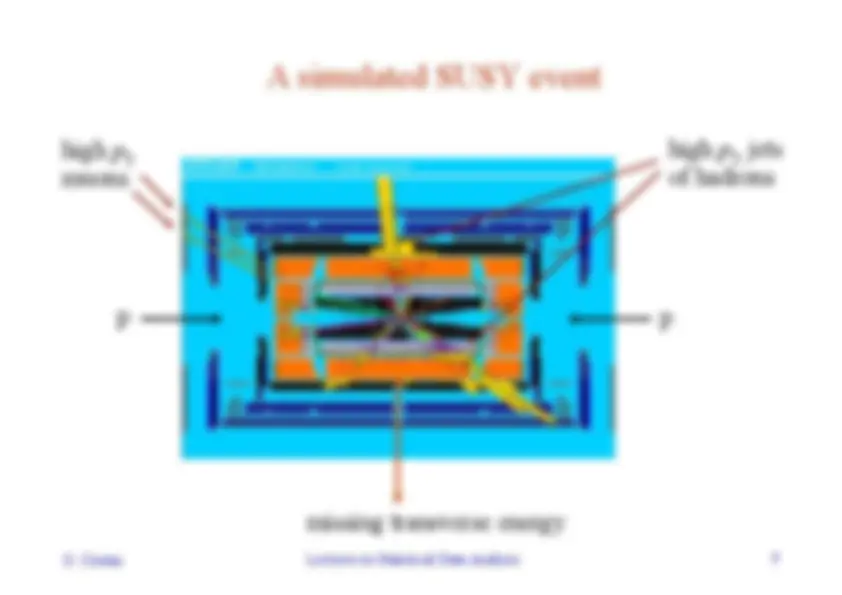
Background events
This event from Standard Model ttbar production also has high p T jets and muons, and some missing transverse energy. → can easily mimic a SUSY event. G. Cowan
Lectures on Statistical Data Analysis 11 For each reaction we consider we will have a hypothesis for the pdf of , e.g.,
Statistical tests (in a particle physics context)
Suppose the result of a measurement for an individual event is a collection of numbers x 1 = number of muons, x 2 = mean p T of jets, x 3 = missing energy, ... follows some n -dimensional joint pdf, which depends on the type of event produced, i.e., was it etc. E.g. call H 0 the background hypothesis (the event type we want to reject); H 1 is signal hypothesis (the type we want). G. Cowan
Lectures on Statistical Data Analysis 13
Other ways to select events
Or maybe use some other sort of decision boundary: accept
H
1
H
0 accept
H
1
H
0 linear or nonlinear How can we do this in an ‘optimal’ way? G. Cowan
Lectures on Statistical Data Analysis 14
Test statistics
The decision boundary can be defined by an equation of the form We can work out the pdfs Decision boundary is now a single ‘cut’ on t , which divides the space into the critical (rejection) region and acceptance region. This defines a test. If the data fall in the critical region, we reject H
where t ( x 1 ,…, x n ) is a scalar test statistic. G. Cowan
Lectures on Statistical Data Analysis 16
Purity of event selection
Suppose only one background type b; overall fractions of signal
and background events are π
s
and π
b (prior probabilities). Suppose we select signal events with t > t cut
. What is the ‘purity’ of our selected sample? Here purity means the probability to be signal given that the event was accepted. Using Bayes’ theorem we find: So the purity depends on the prior probabilities as well as on the signal and background efficiencies. G. Cowan
Lectures on Statistical Data Analysis 17
Constructing a test statistic
How can we choose a test’s critical region in an ‘optimal way’? Neyman-Pearson lemma states: To get the highest power for a given significance level in a test of H 0 , (background) versus H 1 , (signal) the critical region should have inside the region, and ≤ c outside, where c is a constant which determines the power. Equivalently, optimal scalar test statistic is N.B. any monotonic function of this is leads to the same test. G. Cowan
G. Cowan Lectures on Statistical Data Analysis^19
Multivariate methods
Many new (and some old) methods: Fisher discriminant Neural networks Kernel density methods Support Vector Machines Decision trees Boosting Bagging New software for HEP, e.g., TMVA , Höcker, Stelzer, Tegenfeldt, Voss, Voss, physics/ StatPatternRecognition , I. Narsky, physics/
G. Cowan Lectures on Statistical Data Analysis^20
Linear test statistic
Ansatz: → Fisher: maximize Choose the parameters a 1 , ..., a n so that the pdfs have maximum ‘separation’. We want:
s^ Σb
t
g ( t ) τ
b large distance between mean values, small widths
s