



Announcements
• Today
–RAID
– Begin Indexes
• Program 1 due Friday
– Office Hours today 2-3 pm
– I’ll have limited email contact over the weekend
– later today I’ll give info for turning in the program
















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An announcement for a computer science class, discussing topics such as raid (redundant arrays of inexpensive disks), data striping, and indexing structures. Raid aims to balance speed and reliability by using multiple physical disks as a single logical disk. Data striping stores data across multiple disks, and indexing structures provide alternative access paths to records. The document also touches upon the organization and considerations of indexing structures, as well as definitions of primary, secondary, clustered, and dense indices.
Typology: Study Guides, Projects, Research
1 / 24

This page cannot be seen from the preview
Don't miss anything!
Today– RAID– Begin Indexes
-^
Program 1 due Friday– Office Hours today 2-3 pm– I’ll have limited email contact over the weekend– later today I’ll give info for turning in the program
Goal of RAID is to even out rates of diskimprovements (small) w/ those in RAM and CPU
-^
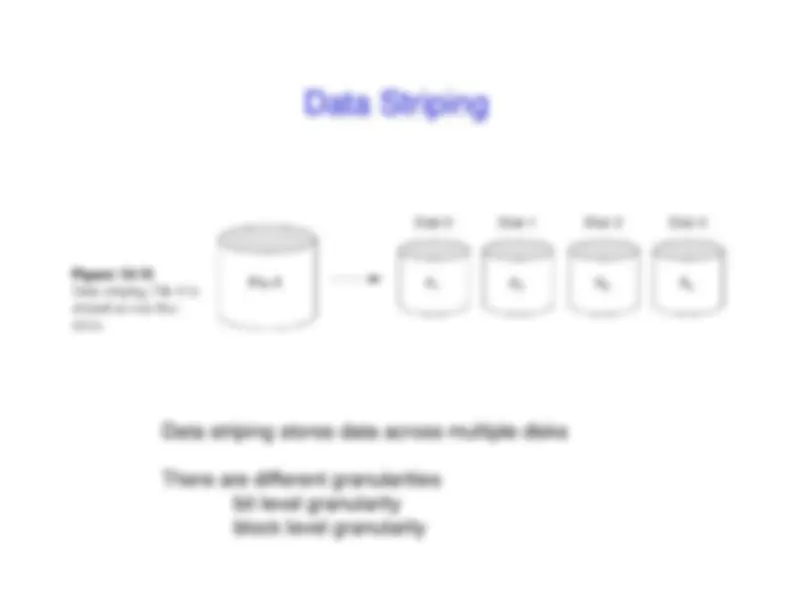
RAID use multiple physical disks to behave as asingle logical disk
Likelihood of failure increases w/ # of disks– Mirroring, error correcting codes are used to increase
reliability at the expense of speed
But is this statement correct?– (from Section 13.10.1)“For an array of
n disks
, the likelihood of failure is
n
times as much as that for one disk. Hence, if theMTTF of a disk drive is 200,000 hours (22.8years), that of a bank of 100 disk drives becomesonly 2000 hours (83 days)”
Query: Find record for student “Troy Allen”
Index on“name”
Step 1: query the index for the RID for the record (hopefully a few IOs)Step 2: query the buffer manager for the appropriate block (1 IO)
RID = (3438, 9)
“Troy Allen”
What is the organization of the underlying file– Eg, is it ordered on the search key?
-^
Are the values of the indexing field unique (ie, isthe indexing field a key field)?
-^
How are the data entries of the index organized?– Example: make index a hashed file on index field
where each record contains (value, RID) pairs
-^
primary index: an index on the ordering key field of aordered file
-^
secondary index: an index on any non-ordering field ofthe file
-^
clustered index: an index whose data entries are orderedin the same way as the underlying file
-^
dense index: has an index entry for every search keyvalue (and hence every record) in the data file.
-^
sparse index: has index entries for only some of thesearch values
Inserting of record in the ordered file (alreadyexpensive) may require significant updates tothe index– Why is this?
one way to handlethe “insert” problemof ordered files
What if the indexing field is not a key field?– Option 1: Keep index entry for each record, so we will
have multiple index entries for each value
“RID list” for each value. Thus the index records arevariable length records• <‘Jim’, { (389, 3), (3239,30), (193, 78) } >