



Physical DB Issues, Indexes,
Query Optimisation
Docsity.com

















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An in-depth exploration of raid (redundant array of independent disks) and indexing techniques used for database optimization. Topics covered include raid arrays, raid levels (0, 1, and 3), parity checking, recovery with parity, indexing concepts, and choosing indexes. Learn how to efficiently store and access data, improve speed, and ensure data redundancy.
Typology: Slides
1 / 30

This page cannot be seen from the preview
Don't miss anything!
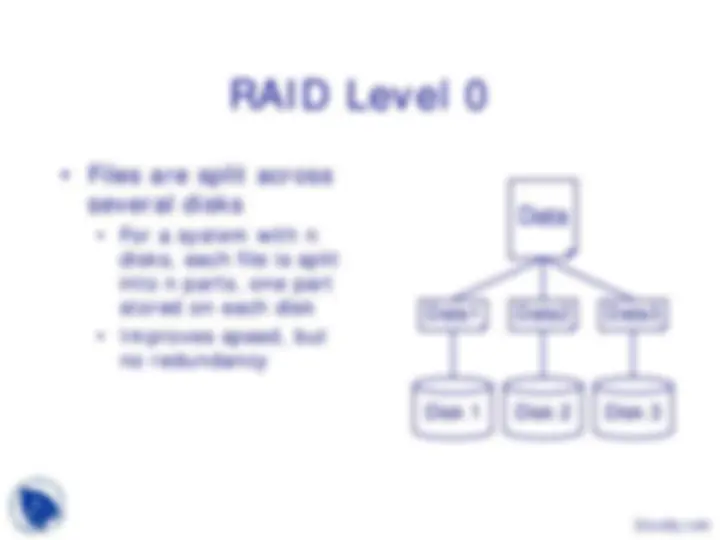
Disk 1 Disk 2 Disk 3
Data1 Data2 Data
Disk 1 Disk 2 Disk 3
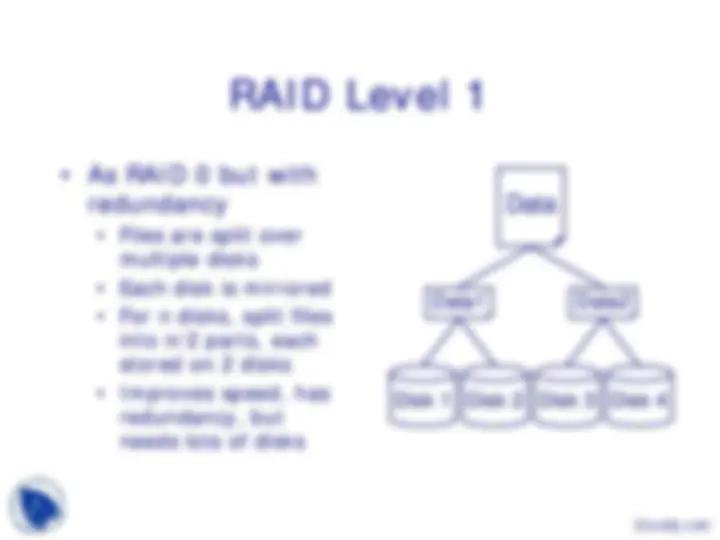
Data1 Data
Disk 4
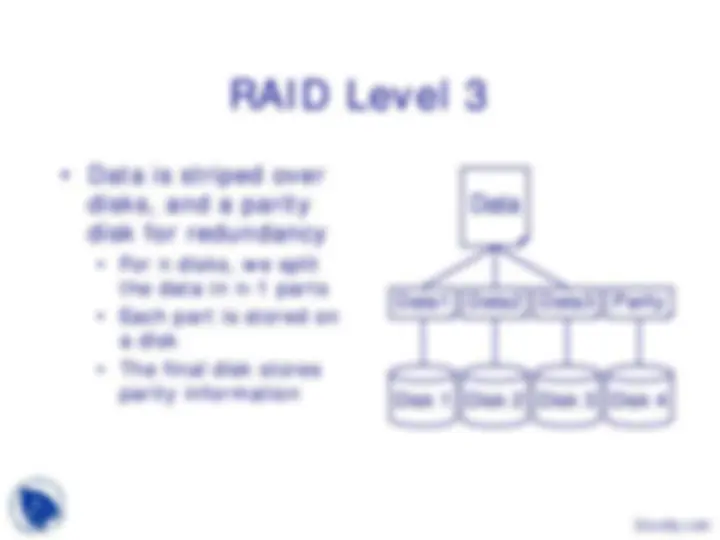
Data1 Data
Disk 4
Data3 Parity
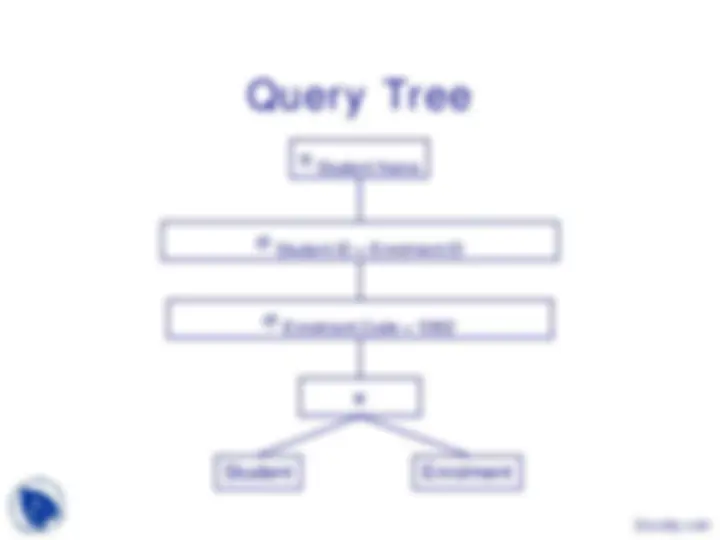
prodID prodName
prodID keyID
keyID keyWord
WHERE SELECT (
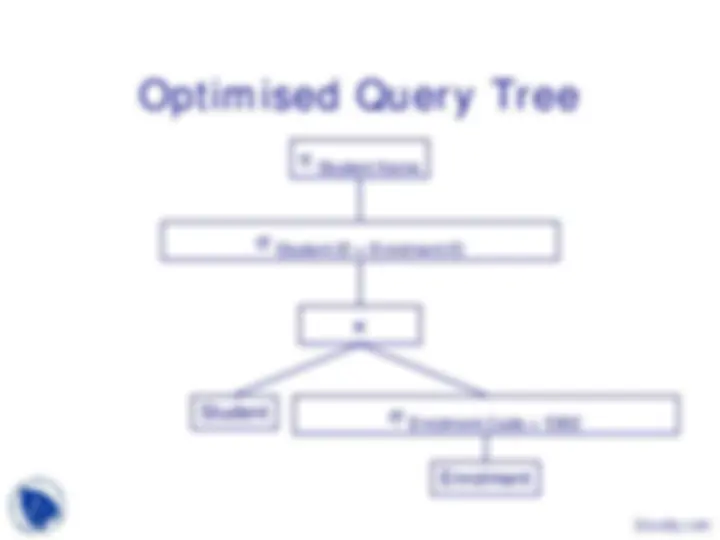
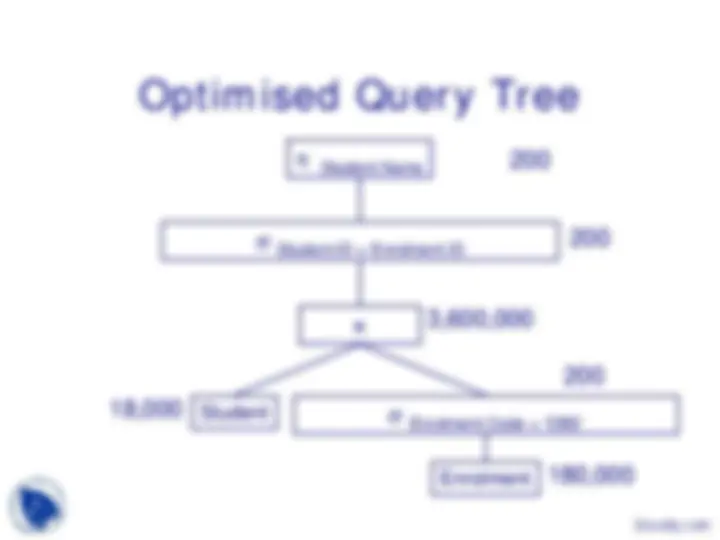
Query Processing
designed and made
we can query it
Some Relational Operators
to
SELECT DISTINCT *
FROM R
Some Relational Operators
equivalent to
SELECT DISTINCT
A1, A2, ...
FROM R
and product are
enough to express
queries of the form
WHERE