Download Decision Trees for Classification: An Overview and more Slides Robotics in PDF only on Docsity!
- Decision Tree Learning
- Practical inductive inference method
- Same goal as Candidate-Elimination algorithm
- Find Boolean function of attributes
- Decision trees can be extended to functions with more than two output values.
- Widely used
- Robust to noise
- Can handle disjunctive (OR’s) expressions
- Completely expressive hypothesis space
- Easily interpretable (tree structure, if-then rules)
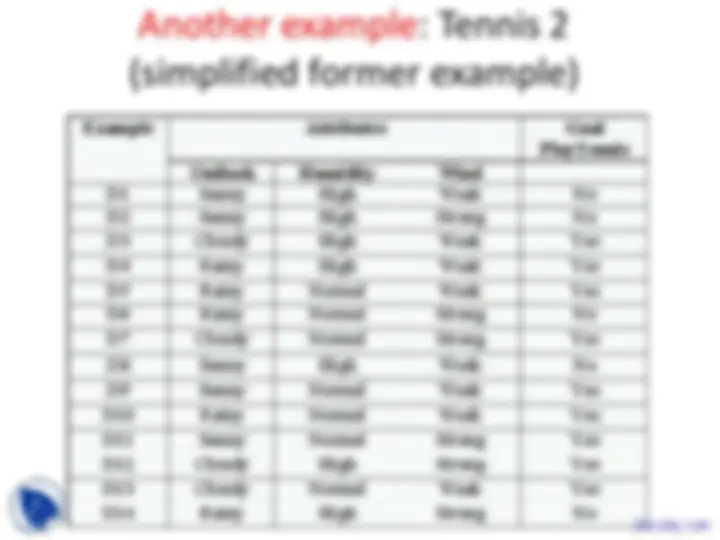
Training Examples
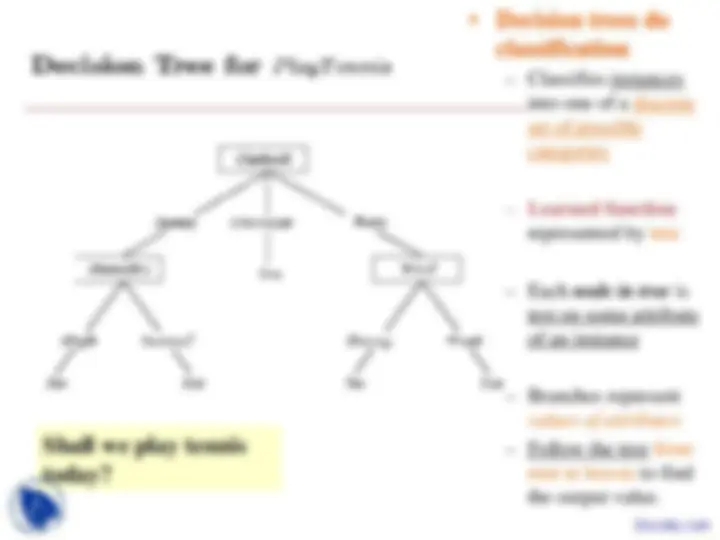
Shall we play tennis today? (Tennis 1)
Attribute, variable,
Object, sample, property example
decision Docsity.com
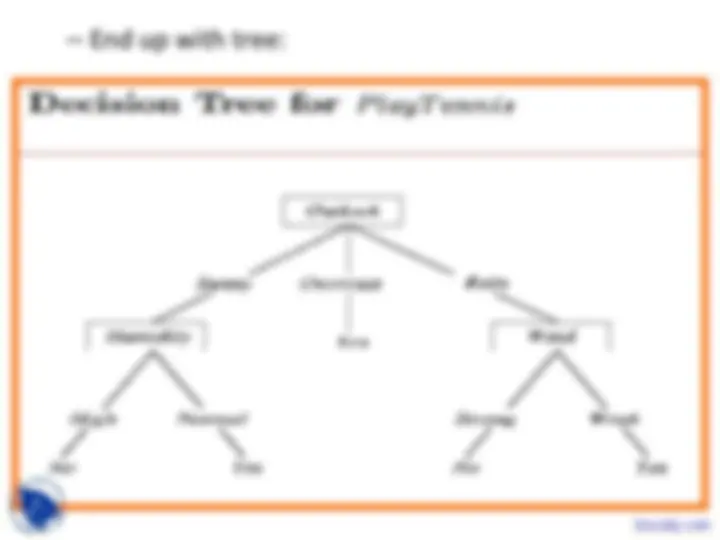
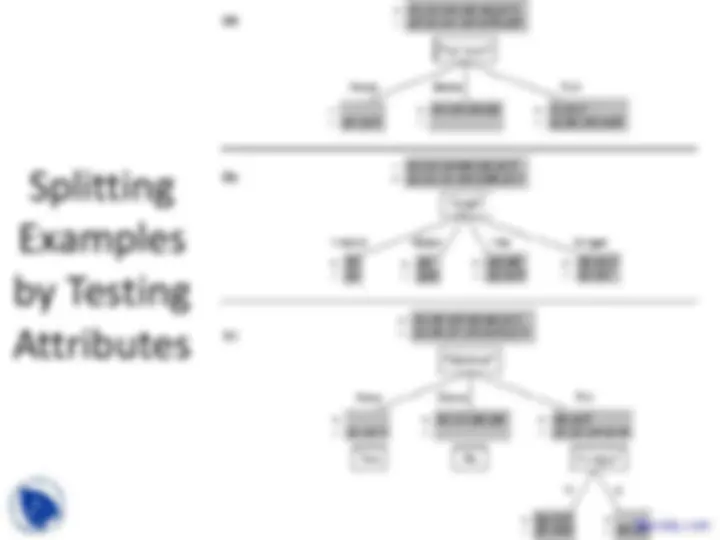
- The tree itself forms hypothesis
- Disjunction (OR’s) of conjunctions (AND’s)
- Each path from root to leaf forms conjunction of constraints on attributes
- Separate branches are disjunctions
- Example from PlayTennis decision tree:
(Outlook=Sunny ∧ Humidity=Normal) ∨ (Outlook=Overcast) ∨ (Outlook=Rain ∧ Wind=Weak)
- Types of problems decision tree learning is
good for:
- Instances represented by attribute-value pairs
- For algorithm in book, attributes take on a small number of discrete values
- Can be extended to real-valued attributes
- Target function has discrete output values
- Algorithm in book assumes Boolean functions
- Can be extended to multiple output values
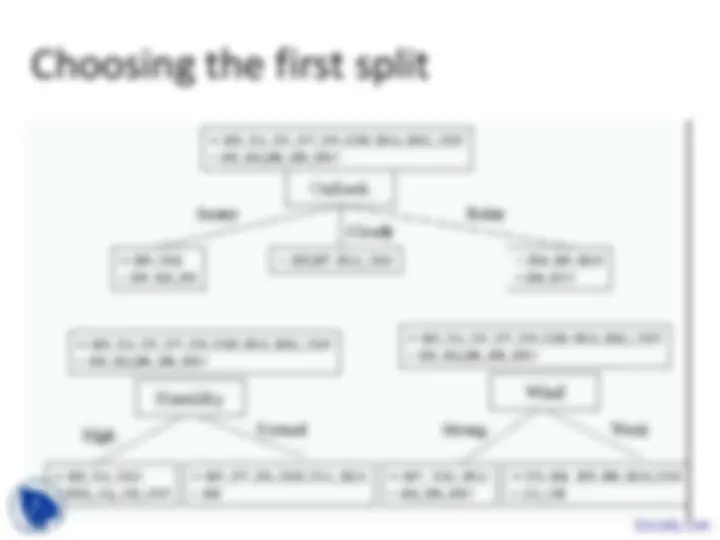
- ID3 Algorithm
- Top-down, greedy search through space of
possible decision trees
- Remember, decision trees represent hypotheses,
so this is a search through hypothesis space.
- What is top-down?
- How to start tree?
- What attribute should represent the root?
- As you proceed down tree, choose attribute for
each successive node.
- No backtracking :
- So, algorithm proceeds from top to bottom
The ID3 algorithm is used to build a decision tree, given a set of non-categorical attributes C1, C2, .., Cn, the categorical attribute C, and a training set T of records.
function ID3 (R: a set of non-categorical attributes, C: the categorical attribute, S: a training set) returns a decision tree; begin If S is empty, return a single node with value Failure; If every example in S has the same value for categorical attribute, return single node with that value; If R is empty, then return a single node with most frequent of the values of the categorical attribute found in examples S; [note: there will be errors, i.e., improperly classified records]; Let D be attribute with largest Gain(D,S) among R’s attributes; Let {dj| j=1,2, .., m} be the values of attribute D; Let {Sj| j=1,2, .., m} be the subsets of S consisting respectively of records with value dj for attribute D; Return a tree with root labeled D and arcs labeled d1, d2, .., dm going respectively to the trees ID3(R-{D},C,S1), ID3(R-{D},C,S2) ,.., ID3(R-{D},C,Sm); end ID3;
Information Theory Background
- If there are n equally probable possible messages, then the probability p of each is 1/n
- Information conveyed by a message is -log(p) = log(n)
- Eg, if there are 16 messages, then log(16) = 4 and we need 4 bits to identify/send each message.
- In general, if we are given a probability distribution P = (p1, p2, .., pn)
- the information conveyed by distribution (aka Entropy of P) is: I(P) = -(p1log(p1) + p2log(p2) + .. + pn*log(pn))
Question?
How do you determine which
attribute best classifies data?
Answer: Entropy!
- Information gain :
- Statistical quantity measuring how well an
attribute classifies the data.
- Calculate the information gain for each attribute.
- Choose attribute with greatest information gain.
Entropy
Largest entropy
Boolean functions with the same number of ones and zeros have largest entropy Docsity.com
- But how do you measure information?
- Claude Shannon in 1948 at Bell Labs established the field of information theory.
- Mathematical function, Entropy , measures information content of random process : - Takes on largest value when events are equiprobable. - Takes on smallest value when only one event has non-zero probability.
- For two states:
- Positive examples and Negative examples from set S:
H(S) = - p+log 2 (p+) - p- log 2 (p- )
Entropy = Measure of order in set S Docsity.com
- If an event conveys information, that means it’s a
surprise.
- If an event always occurs, P(Ai)=1, then it carries no
information. -log 2 (1) = 0
- If an event rarely occurs (e.g. P(A (^) i)=0.001), it carries a lot
of info. -log 2 (0.001) = 9.
- The less likely the event, the more the information it
carries since, for 0 ≤ P(Ai) ≤ 1,
-log 2 (P(Ai)) increases as P(Ai) goes from 1 to 0.
- (Note: ignore events with P(A (^) i)=0 since they never occur.)
- What about entropy?
- Is it a good measure of the information carried by an ensemble of events?
- If the events are equally probable, the entropy is maximum.
1) For N events, each occurring with probability 1/N.
H = - ∑ (1/N)log 2 (1/N) = -log 2 (1/N)
This is the maximum value. (e.g. For N=256 (ascii characters) -log 2 (1/256) = 8 number of bits needed for characters. Base 2 logs measure information in bits.)
This is a good thing since an ensemble of equally probable events is as uncertain as it gets.
(Remember, information corresponds to surprise - uncertainty .) Docsity.com
- Choice of base 2 log corresponds to
choosing units of information. (BIT’s)
- Another remarkable thing:
- This is the same definition of entropy used in
statistical mechanics for the measure of
disorder.
- Corresponds to macroscopic thermodynamic
quantity of Second Law of Thermodynamics.
- The concept of a quantitative measure for information content plays an important role in many areas:
- For example,
- Data communications (channel capacity)
- Data compression (limits on error-free encoding)
- Entropy in a message corresponds to minimum number of bits needed to encode that message.
- In our case, for a set of training data, the entropy measures the number of bits needed to encode classification for an instance. - Use probabilities found from entire set of training data. - Prob(Class=Pos) = Num. of positive cases / Total case - Prob(Class=Neg) = Num. of negative cases / Total cases