Download Introduction to Deep Learning and more Lecture notes Architecture in PDF only on Docsity!
Introduction to Deep Learning
Jes´us Fern´andez-Villaverde^1 and Galo Nu˜no^2 September 1, 2022 (^1) University of Pennsylvania
(^2) Banco de Espa˜na
The problem
- We want to approximate (“learn”) an unknown function:
y = f (x)
where y is a scalar and x = {x 0 = 1, x 1 , x 2 , ..., xN } a vector (including a constant).
- We care about the case when N is large (possibly in the thousands!).
- Easy to extend to the case where y is a vector (e.g., a probability distribution), but notation becomes cumbersome.
- In economics, f (x) can be a value function, a policy function, a pricing kernel, a conditional expectation, a classifier, ...
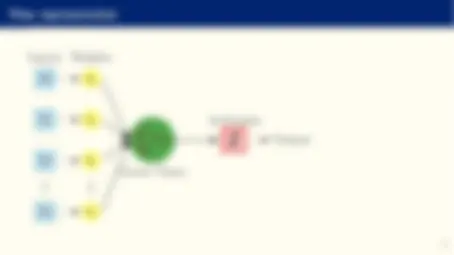
Flow representation
Inputs Weights
x 0 θ 0
x 1 θ 1
x 2 θ 2
xn θn
X^ n
i=
θi xi
Linear Trans.
Activation
Output
Intuition
- Intuition 1: A biological interpretation, but I do not find it too useful. Closer to econometrics (e.g., NOLS, semiparametric regression, and sieves) and differential geometry.
- Intuition 2: We look for representations of the features of the data that are informationally efficient.
- Intuition 3 (more advanced): We look for translations and rotations of the data that deliver a more convenient geometry by moving from a parent space to a simpler one.
Comparison with other approximations
- Compare: f (x) ∼= g NN^ (x; θ) = θ 0 +
X^ M
m=
θmϕ
X^ N
n=
θn,mxn
with a standard projection:
f (x) ∼= g CP^ (x; θ) = θ 0 +
X^ M
m=
θmϕm (x)
where ϕm is, for example, a Chebyshev polynomial.
- We exchange the rich parameterization of coefficients for the parsimony of basis functions.
- How we determine the coefficients will also be different, but this is somewhat less important.
Why do neural networks “work”?
- Neural networks consist entirely of chains of tensor operations: we take x, we perform affine transformations, and apply an activation function.
- Thus, these tensor operations are geometric transformations of x. In fact, a better name for neural networks could be chained geometric transformations.
- In other words: a neural network is a complex geometric transformation in a high-dimensional space.
- Deep neural networks look for convenient geometrical representations of high-dimensional manifolds.
- The success of any functional approximation problem is to search for the right geometric space in which to perform it, not to search for a “better” basis function.
Deep learning, I
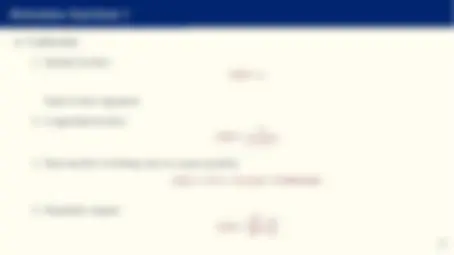
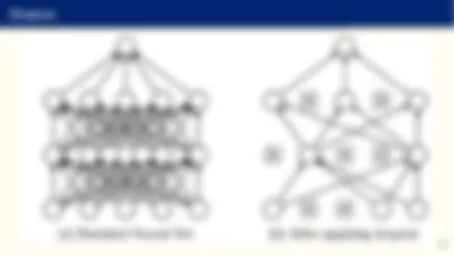
- A deep learning network is an acyclic multilayer composition of J > 1 neural networks:
z m^0 = θ 00 ,m +
X^ N
n=
θ^0 n,mxn
and z m^1 = θ^10 ,m +
M X(1)
m=
θ m^1 ϕ^1
z m^0
y ∼= g DL(x; θ) = θJ 0 +
M X(J)
m=
θJmϕJ^
z mJ−^1
where the M(1), M(2), ... and ϕ^1 (·), ϕ^2 (·), ... are possibly different across each layer of the network.
- A deep network creates new features by composing older features.
x 0
x 1
x 2
Input Values
Input Layer
Hidden Layer 1
Hidden Layer 2
Output Layer
Why do deep neural networks “work” better?
- Why do we want to introduce hidden layers?
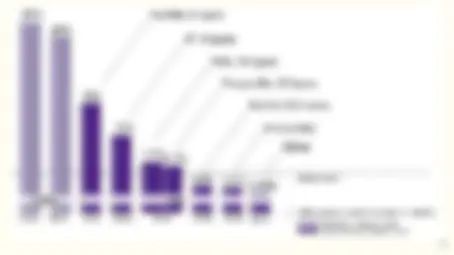
- It works! Evolution of ImageNet winners.
- The number of representations increases exponentially with the number of hidden layers while computational cost grows linearly.
- Intuition: hidden layers induce highly nonlinear behavior in the joint creation of representations without the need to have domain knowledge (used, in other algorithms, in some form of greedy pre-processing).
Further advantages
- Neural networks and deep learning often require less “inside knowledge” by experts on the area.
- While results can be highly counter-intuitive, deep neural networks deliver excellent performance.
- Outstanding open source libraries (Tensorflow, Keras, Pytorch, Flux) that integrate well with easy scripting languages (Python).
- Newer algorithms: batch normalization, residual connections, and depthwise separable convolutions.
- More recently, development of dedicated hardware (TPUs, AI accelerators, FPGAs) are likely to maintain a hedge for the area.
- The richness of an ecosystem is key for its long-run success.
References