


Intro to Linear Methods
Reading: DH&S, Ch 5.{1-4,8}
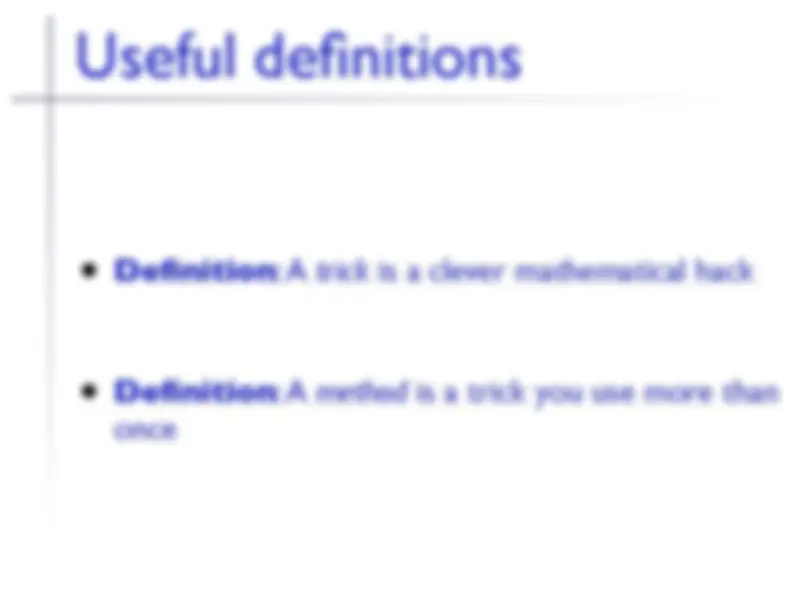
hip to be hyperplanar...









Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Linear regression, a method used to find the best linear function that fits a given dataset. The assumptions behind linear regression, the math involved, and the process of minimizing the squared error loss function. It also covers useful definitions and linear algebra identities.
Typology: Study notes
1 / 17

This page cannot be seen from the preview
Don't miss anything!
Reading: DH&S, Ch 5.{1-4,8}
hip to be hyperplanar...
classifiers & Bayes error
g(x) = w 0 + w 1 x 1 + w 2 x 2 + · · · + wd xd
wi
wi != ω (^) i
double-u omega
little curly squiggle...
g(x) = w 0 + w 1 x 1 + w 2 x 2 + · · · + wd xd
squared error : Js (w 0 ,... , wd ) =
∑^ n
i=
g(x (^) i ) − f̂ (x (^) i )
∑^ n
i=
b (^) i −
w 0 +
∑^ d
j=
wj xji
Loss function 2
w 0 + w 1 x 1 + · · · + wd xd
x 0 = 1
x = [x 1 , x 2 ,... , xd ]^ T
y = [1, x 1 , x 2 ,... , xd ]^ T
y = [1, x 1 , x 2 ,... , xd ]^ T a = [w 0 , w 1 , w 2 ,... , wd ]^ T f̂ (x) = a T^ y
Js (a) =
∑^ n
i=
b (^) i − a T^ y
solve:
l(w) = aw 2 + bw + c
∂w l(w) = 2aw^ +^ b = 0 ⇒ wmin = −
b 2 a
(AB)−^1 = B −^1 A −^1 (for invertible square matrices)
weight vector, a , in the loss function:
∂x x^
∂x x^
Js (a) = (b − Y T^ a)^ T^ (b − Y T^ a)
∂x x^
T (^) Ax = x T (^) (A + A T (^) )
positive semidefinite and symmetric
Y
of Matlab code