Download Introduction to Machine Learning: Concepts and Applications and more Lecture notes Introduction to Machine Learning in PDF only on Docsity!
Introduction to Machine Learning
Tough concepts made intuitive
Agenda
Intro to ML (Machine Learning):
– Supervised Learning Use Cases (Regression,
Classification)
– Unsupervised Learning Use Cases (Clustering &
Retrieval, Recommendation, Image recognition with
Neural Networks…)
– Formalizing an ML Problem
– Data Exploration & Preparation: data issues
What is Machine Learning?
ML is a set of AI techniques
where “intelligence” is built
from examples
A set of Algorithms that can
improve as they are exposed to
more data
Vocabulary
Input (explanatory variables) &
Output (dependent variable or
target): data point
Model
Training Data (or Learn)
Features (I.e: size, number of
rooms, location…)
Predict or Score
Defining the right ML problem
Which type of e-mail is this? Spam or Not =>
Classification (with Confidence X%)
How much is this house worth? => Regression
ML is used by many companies to get more
customers or serve customers better:
Amazon (optimize price), Gmail (spam filtering),
Zillow (realestate price)….
Data exploration
Significant proportion of an analytical project
(90% of the project time)
Might be selected from multiple sources
Very important to understand (Correlations,
General trends, Outliers ...) before blindly
throwing algorithms at it
May include producing statistics (mean,
median, ...) and visualizations
Exploring Data
we notice a few things.
- There seems to be an outlier with around 800 shares and a little over 5000 likes. This might be an interesting post to investigate.
- most of our data are between 0 - 200 shares and 0 - 2000 likes, quite densely actually
Cleaning Data
some of data might not exist. In this case, we have to decide what we should do. There are many valid options:
- forget/remove the nonexistent data,
- replace it with a default value,
- interpolate (for time-series data), etc. In our case, we're just substituting a reasonable value (zero).
Use Case1: Predictive Analytics
Regression Model
To predict the price of your house: plot recent
sales of similar houses in your neighborhood
Fit a line through the data
Y= f
w
(x)=w
0
+w
1
x
x: feature, y: observation or response
w (w 0 , w 1 ) parameters of model
Find the best line by minimizing
RSS=Sum ([$house-Y]^2 )
Classification Main Concepts
Decision Trees
Confusion Matrix
Confusion Matrix
“Precision”: Fraction of positive
predictions that are actually
positive
What fraction of positive were
missed out?
“Recall”: Proportion of positive
objects that were indeed detected
as positive by the model
Precision = TP/ (TP+FP)
Recall= TP/(TP+FN)
Negatives are empty, positives are full
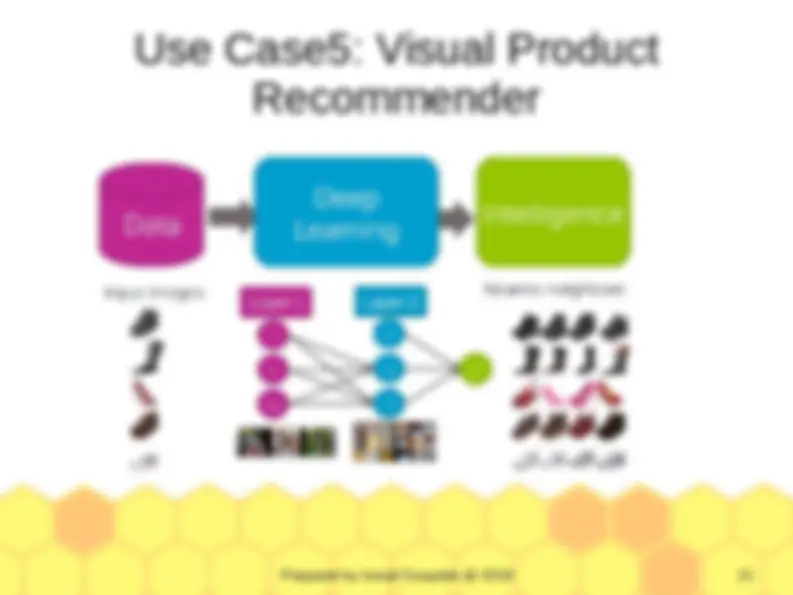
Use Case3: Document Retrieval
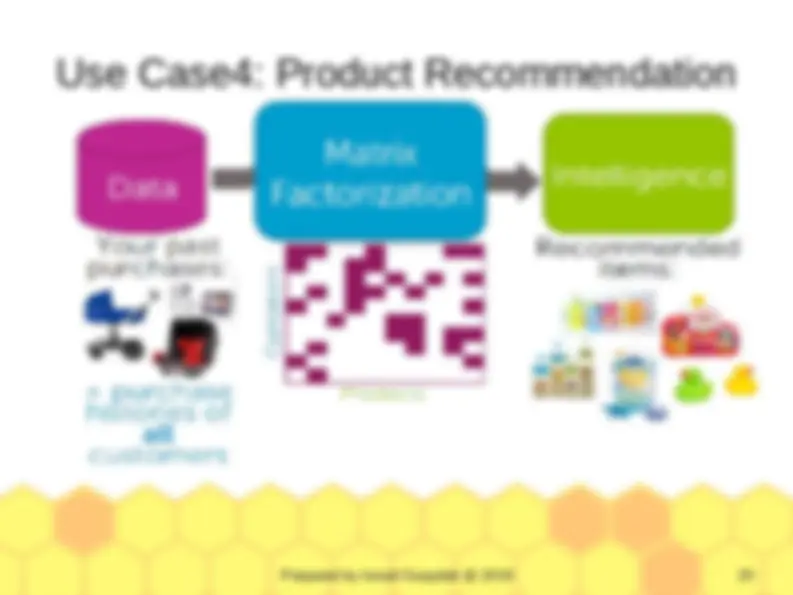
Use Case4: Product Recommendation