



Compiler
Compiler
Construction
Construction
Compiler
Compiler
Construction
Construction
Lecture 10


















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
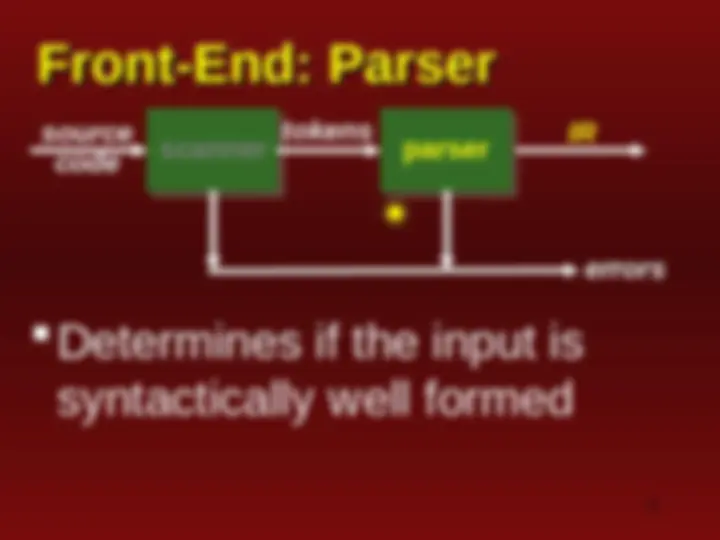
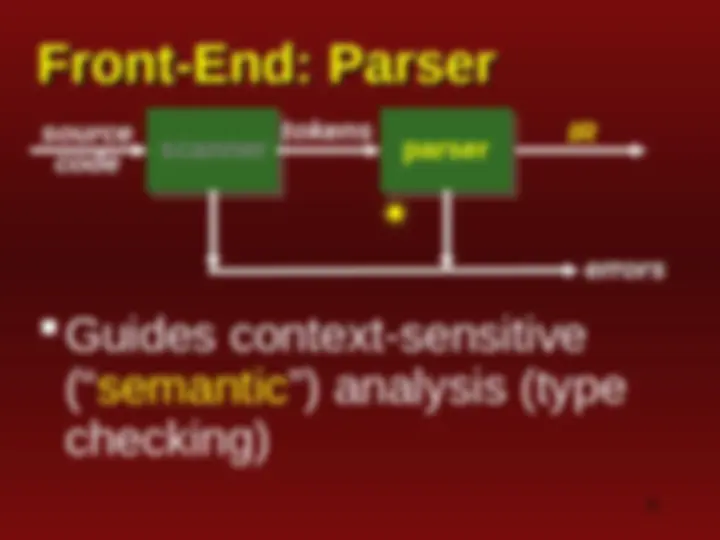
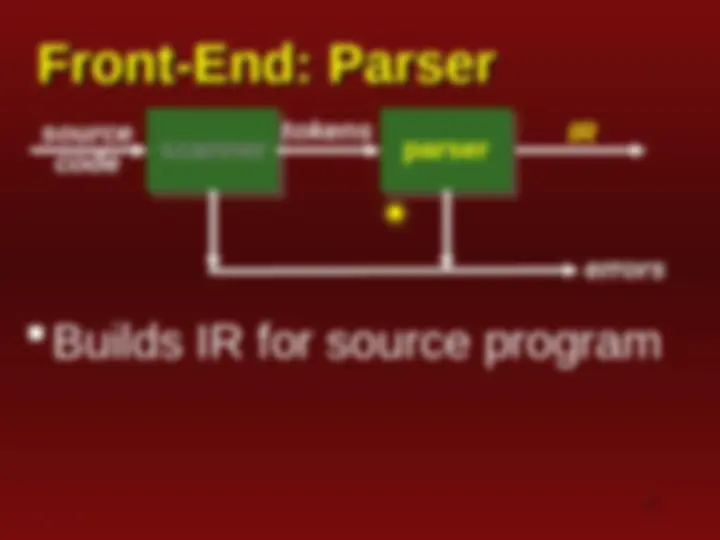
An overview of the Flex lexer and parser for C++. It includes the code for the lexer and parser, as well as explanations of various tokens and their meanings. The document also discusses the role of the lexer and parser in syntactic analysis and the building of Intermediate Representation (IR) for source programs.
Typology: Slides
1 / 33

This page cannot be seen from the preview
Don't miss anything!
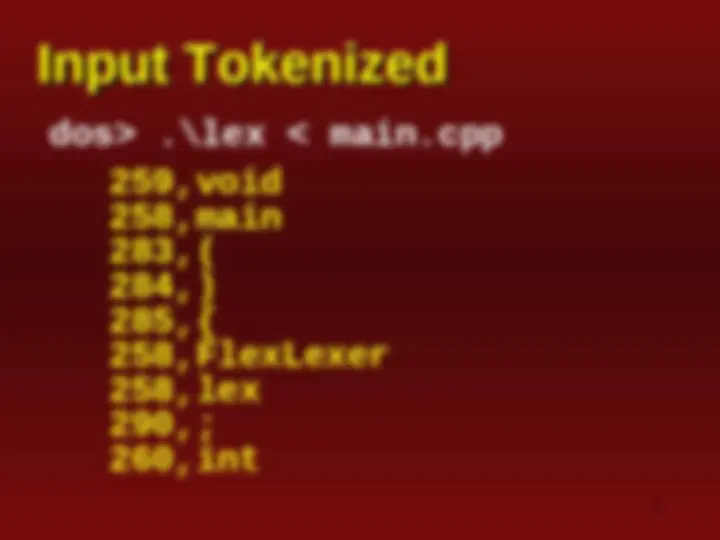
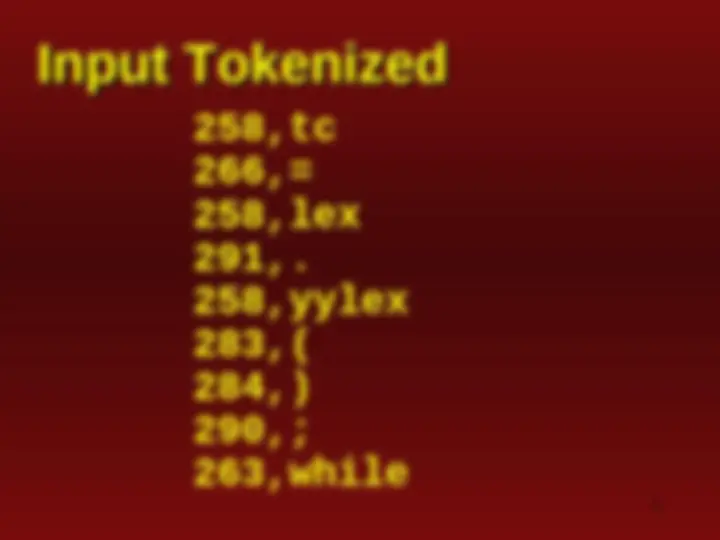
258,endl 290,; 258,tc 266,= 258,lex 291,. 258,yylex 283,( 284,) 290,; 286,}
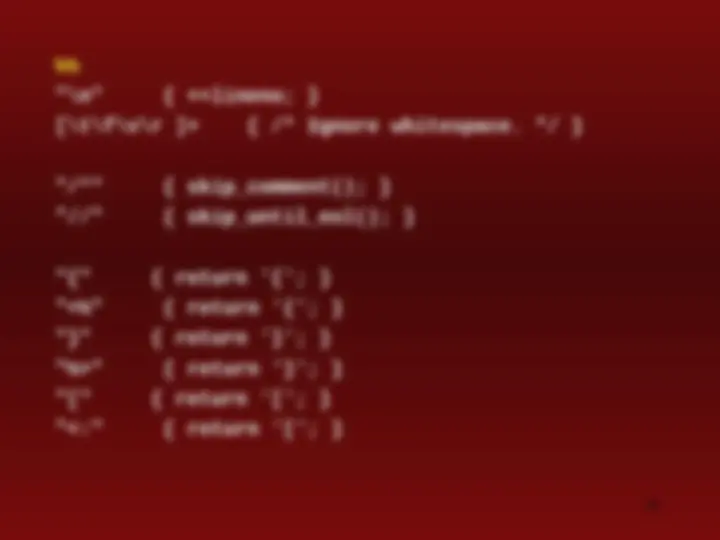
"\n" { ++lineno; } [\t\f\v\r ]+ { /* Ignore whitespace. / } "/" { skip_comment(); } "//" { skip_until_eol(); } "{" { return '{'; } "<%" { return '{'; } "}" { return '}'; } "%>" { return '}'; } "[" { return '['; } "<:" { return '['; }
"]" { return ']'; } ":>" { return ']'; } "(" { return '('; } ")" { return ')'; } ";" { return ';'; } ":" { return ':'; } "..." { return ELLIPSIS; } "?" { return '?'; } "::" { return COLONCOLON; } "." { return '.'; } "." { return DOTSTAR; } "+" { return '+'; } "-" { return '-'; } "" { return '*'; } "/" { return '/'; } "%" { return '%'; } "^" { return '^'; } "xor" { return '^'; } "&" { return '&'; } "bitand" { return '&'; }
"<<" { return SL; } ">>" { return SR; } "<<=" { return SLEQ; } ">>=" { return SREQ; } "==" { return EQ; } "!=" { return NOTEQ; } "not_eq" { return NOTEQ; } "<=" { return LTEQ; } ">=" { return GTEQ; } "&&" { return ANDAND; } "and" { return ANDAND; } "||" { return OROR; } "or" { return OROR; } "++" { return PLUSPLUS; } "--" { return MINUSMINUS; } "," { return ','; } "->*" { return ARROWSTAR; } "->" { return ARROW; }
"asm" { return ASM; } "auto" { return AUTO; } "bool" { return BOOL; } "break" { return BREAK; } "case" { return CASE; } "catch" { return CATCH; } "char" { return CHAR; } "class" { return CLASS; } "const" { return CONST; } "const_cast" { return CONST_CAST; } "continue" { return CONTINUE; } "default" { return DEFAULT; } "delete" { return DELETE; } "do" { return DO; } "double" { return DOUBLE; } "dynamic_cast" { return DYNAMIC_CAST; } "else" { return ELSE; } "enum" { return ENUM; } "explicit" { return EXPLICIT; } "export" { return EXPORT; }
"short" { return SHORT; } "signed" { return SIGNED; } "sizeof" { return SIZEOF; } "static" { return STATIC; } "static_cast" { return STATIC_CAST; } "struct" { return STRUCT; } "switch" { return SWITCH; } "template" { return TEMPLATE; } "this" { return THIS; } "throw" { return THROW; } "true" { return TRUE; } "try" { return TRY; } "typedef" { return TYPEDEF; } "typeid" { return TYPEID; } "typename" { return TYPENAME; } "union" { return UNION; } "unsigned" { return UNSIGNED; } "using" { return USING; } "virtual" { return VIRTUAL; } "void" { return VOID; }
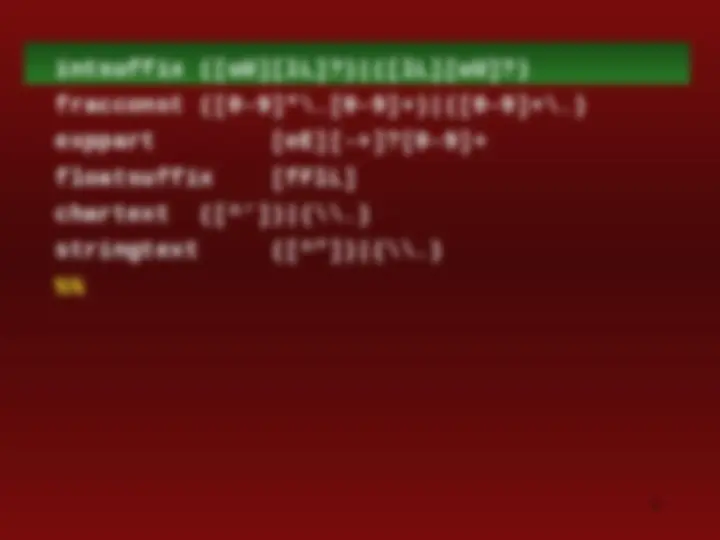
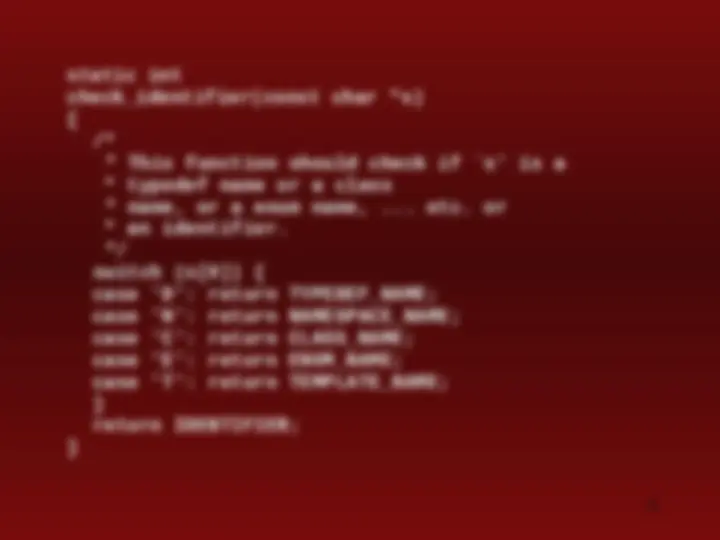
"volatile" { return VOLATILE; } "wchar_t" { return WCHAR_T; } "while" { return WHILE; } [a-zA-Z_][a-zA-Z_0-9]* { return check_identifier(yytext); } "0"[xX][0-9a-fA-F]+{intsuffix}? { return INTEGER; } "0"[0-7]+{intsuffix}? { return INTEGER; } [0-9]+{intsuffix}? { return INTEGER; }
. { fprintf(stderr, "%d: unexpected character `%c'\n", lineno, yytext[0]); } %% static int yywrap(void) { return 1; }
static void skip_comment(void) { int c1, c2; c1 = input(); c2 = input(); while(c2 != EOF && !(c1 == '*' && c2 == '/')) { if (c1 == '\n') ++lineno; c1 = c2; c2 = input(); } }