Download Learning - Artificial Neural Network - Lecture Slides and more Slides Computer Networks in PDF only on Docsity!
Introduction to Neural Networks
and Machine Learning
Lecture 3: Learning in multi-layer networks
Preprocessing the input vectors
- Instead of trying to predict the answer directly from the raw inputs we could start by extracting a layer of “features”. - Sensible if we already know that certain combinations of input values would be useful (e.g. edges or corners in an image).
- Instead of learning the features we could design them by hand. - The hand-coded features are equivalent to a layer of non- linear neurons that do not need to be learned. - So far as the learning algorithm is concerned, the activities of the hand-coded features are the input vector.
Is preprocessing cheating?
- It seems like cheating if the aim to show how
powerful learning is. The really hard bit is
done by the preprocessing.
- Its not cheating if we learn the non-linear
preprocessing.
- This makes learning much more difficult and much
more interesting..
- Its not cheating if we use a very big set of non-
linear features that is task-independent.
- Support Vector Machines make it possible to use a
huge number of features without requiring much
computation or data.
What can perceptrons do?
- They can only solve tasks if the hand-
coded features convert the original task into a linearly separable one. How difficult is this?
- The N-bit parity task :
- Requires N features of the form: Are at least m bits on?
- Each feature must look at all the components of the input.
- The 2-D connectedness task
- requires an exponential number of features!
The 7-bit parity task 1011010 0 0111000 1 1010111 1
Learning with hidden units
- Networks without hidden units are very limited in the input-
output mappings they can model.
- More layers of linear units do not help. Its still linear.
- Fixed output non-linearities are not enough
- We need multiple layers of adaptive non-linear hidden units.
This gives us a universal approximator. But how can we train such nets?
- We need an efficient way of adapting all the weights, not just the last layer. This is hard. Learning the weights going into hidden units is equivalent to learning features.
- Nobody is telling us directly what hidden units should do. (That’s why they are called hidden units).
Learning by perturbing weights
- Randomly perturb one weight and see if it improves performance. If so, save the change. - Very inefficient. We need to do multiple forward passes on a representative set of training data just to change one weight. - Towards the end of learning, large weight perturbations will nearly always make things worse.
- We could randomly perturb all the weights in parallel and correlate the performance gain with the weight changes. - Not any better because we need lots of trials to “see” the effect of changing one weight through the noise created by all the others.
Learning the hidden to output weights is easy. Learning the
input to hidden weights is hard.
hidden units
output units
input units
A change of notation
- For simple networks we use the
notation x for activities of input units y for activities of output units z for the summed input to an output unit
- For networks with multiple hidden
layers: y is used for the output of a unit in any layer x is the summed input to a unit in any layer The index indicates which layer a unit is in.
i
j
j
i
j
j
y
x
y
x
z
y
Non-linear neurons with smooth derivatives
- For backpropagation, we need
neurons that have well-behaved derivatives.
- Typically they use the logistic function
- The output is a smooth function of the inputs and the weights.
This image cannot currently be displayed.
j j j
j
ij i
j i ij
j
j
j
ij i
j j i
y y
dx
dy
w
y
x
y
w
x
x
e
y
x b y w
0
0
1
x j
y j
Its odd to express it in terms of y.
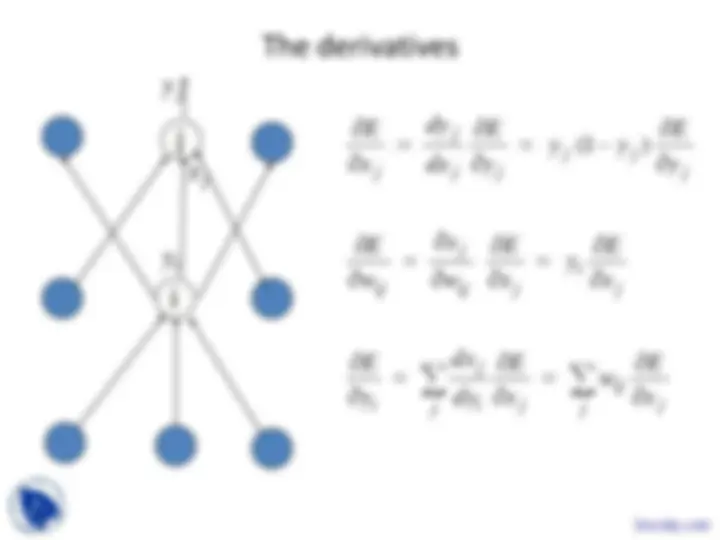
The derivatives
i
j
j
y
x
y
∑ ∑
j j
ij j i j
j
i
j
i ij j
j
ij
j
j j j j
j
j
x
E
w
x
E
dy
dx
y
E
x
E
y
x
E
w
x
w
E
y
E
y y
y
E
dx
dy
x
E
j ( 1 )
i
Ways to use weight derivatives
- How often to update
- after each training case?
- after a full sweep through the training data?
- after a “mini-batch” of training cases?
- How much to update
- Use a fixed learning rate?
- Adapt the learning rate?
- Add momentum?
- Don’t use steepest descent?
A simple example of overfitting
- Which model do you believe?
- The complicated model fits the data better.
- But it is not economical
- A model is convincing when it fits a lot of data surprisingly well. - It is not surprising that a complicated model can fit a small amount of data.