Download Learning Features - Artificial Neural Network - Lecture Slides and more Slides Computer Networks in PDF only on Docsity!
Neural Networks
Lecture 22
Learning features one layer at a time
Learning multilayer networks
- We want to learn models with multiple layers of non-linear features.
- Perceptrons: Use a layer of hand-coded, non-adaptive features followed by a layer of adaptive decision units. - Needs supervision signal for each training case. - Only one layer of adaptive weights.
- Back-propagation: Use multiple layers of adaptive features and train by backpropagating error derivatives - Needs supervision signal for each training case. - Learning time scales poorly for deep networks.
- Support Vector Machines: Use a very large set of fixed features - Needs supervision signal for each training case. - Does not learn multiple layers of features
Recursive Restricted Boltzmann Machines
- First learn a layer of hidden features.
- Then treat the feature activations as data and learn a second layer of hidden features.
- And so on for as many hidden layers as we want.
data
first layer of features
data is activities of first layer of features
second layer of features
RBM
RBM
Recursive Restricted Boltzmann Machines
- Is learning a model of the hidden activities just a hack?
- It does not seem as if we are learning a proper multilayer model because the lower weights do not depend on the higher ones.
- Can we treat the hidden layers of the whole stack of RBM’s as part of one big generative model rather than a model plus a model of a model etc.? - If it is one big model, it definitely is not a Boltzmann machine. The first hidden layer has two sets of weights (above and below) which would make the hidden activities very different from the activities of those units in either of the RBM’s.
The generative model
- To generate data:
- Get an equilibrium sample from the top-level RBM by performing alternating Gibbs sampling for a long time.
- Perform a single top-down pass to get states for all the other layers. The lower-level, bottom-up connections are not part of the generative model. They are there to do fast approximate inference.
h 2
data
h 1
h 3
W 2
W 3
W 1
W^ T
2
W^ T
1
Why does stacking RBM’s produce this kind of generative model?
- It is not at all obvious that stacking RBM’s
produces a model in which the top two layers of features form an RBM, but the layers beneath that are not at all like a Boltzmann Machine.
- To understand why this happens we need to
ask how an RBM defines a probability distribution over visible vectors.
Why does layer-by-layer learning
work?
h h
p ( v ) p ( v , h ) p ( h ) p ( v | h )
The weights, W, in the bottom level RBM define p(v|h) and they also, indirectly, define p(h).
So we can express the RBM model as
If we leave p(v|h) alone and build a better model of p(h), we will improve p(v). We need a better model of the posterior hidden vectors produced by applying W to the data.
index over all hidden vectors
joint probability
conditional probability
An analogy
- In a mixture model, we define the probability of a datavector to be
- The learning rule for the mixing proportions is to make them match the posterior probability of using each Gaussian.
- The weights of an RBM implicitly define a mixing proportion for each possible hidden vector. - To fit the data better, we can leave p(v|h) the same and make the mixing proportion of each hidden vector more like the posterior over hidden vectors.
h
p ( v ) p ( h ) p ( v | h )
mixing proportion of Gaussian
index over all Gaussians
probability of v given Gaussian h
Back-fitting
- After we have learned all the layers greedily,
the weights in the lower layers will no longer be optimal.
- The weights in the lower layers can be fine-
tuned in several ways.
- For the generative model that comes next, the
fine-tuning involves a complicated and slow
stochastic learning procedure.
- If our ultimate goal is discrimination, we can use
backpropagation for the fine-tuning.
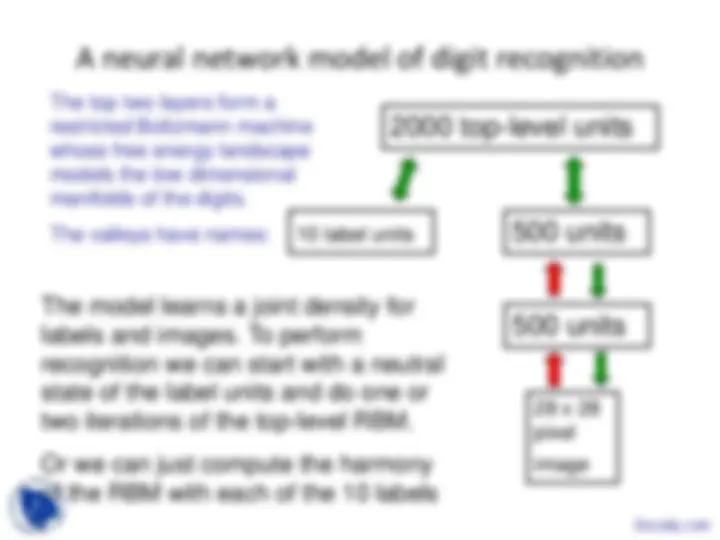
A neural network model of digit recognition
2000 top-level units
500 units
500 units
28 x 28 pixel image
10 label units
The model learns a joint density for labels and images. To perform recognition we can start with a neutral state of the label units and do one or two iterations of the top-level RBM.
Or we can just compute the harmony of the RBM with each of the 10 labels
The top two layers form a restricted Boltzmann machine whose free energy landscape models the low dimensional manifolds of the digits. The valleys have names:
Samples generated by running the top-level RBM with
one label clamped. There are 1000 iterations of
alternating Gibbs sampling between samples.
Examples of correctly recognized MNIST test digits (the 49
closest calls)
All 125 errors
The receptive fields of the first hidden layer