Download Lecture Slides on Large Cache Innovations | CS 6810 and more Study notes Computer Architecture and Organization in PDF only on Docsity!
Lecture 16: Large Cache Innovations^ •^ Today: Large cache design and other cache innovations^ •^ Midterm scores^ ^ 91-80: 17 students^ ^ 79-75: 14 students^ ^ 74-68: 8 students^ ^ 63-54: 5 students^ •^ Q1 (HM), Q2 (bpred), Q3 (stalls), Q7 (loops) mostly correct^ •^ Q4 (ooo) – 50% correct; many didn’t stall renaming^ •^ Q5 (multi-core) – less than a handful got 8+ points^ •^ Q6 (memdep) – less than a handful got part (b) right and
correctly articulated the effect on power/energy
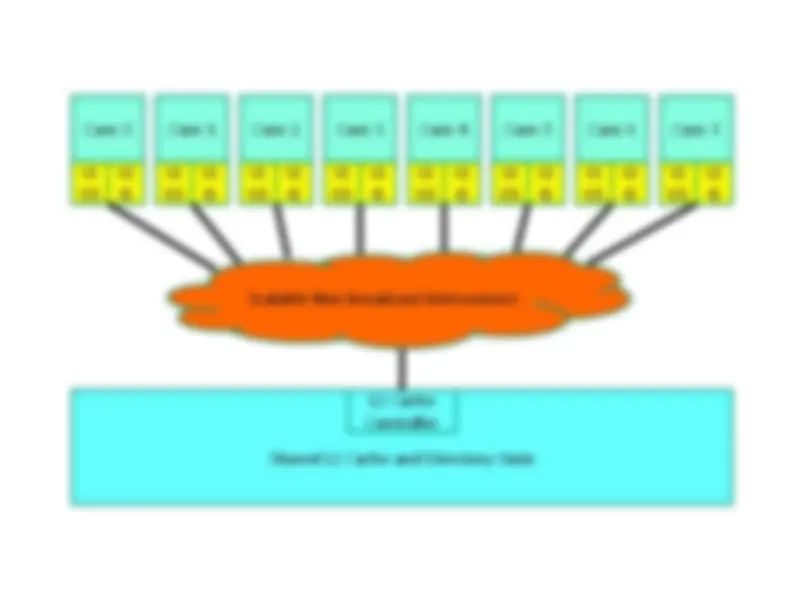
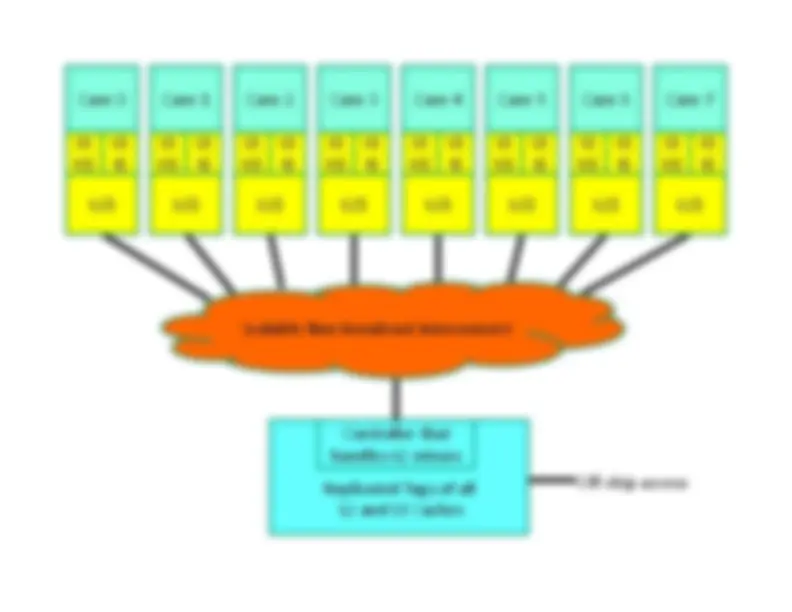
Shared Vs. Private Caches in Multi-Core^ •^ Advantages of a shared cache:^ ^ Space is dynamically allocated among cores^ ^ No wastage of space because of replication^ ^ Potentially faster cache coherence (and easier to^ locate data on a miss)^ •^ Advantages of a private cache:^ ^ small L
Æ^ faster access time
^ private bus to L
Æ^ less contention
Large NUCA
CPU
Issues to be addressed for Non-Uniform Cache Access:^ •^ Mapping^ •^ Migration^ •^ Search^ •^ Replication
Static and Dynamic NUCA^ •^ Static NUCA (S-NUCA)^ ^ The address index bits determine where the block^ is placed^ ^ Page coloring can help here as well to improve locality^ •^ Dynamic NUCA (D-NUCA)^ ^ Blocks are allowed to move between banks^ ^ The block can be anywhere: need some search^ mechanism^ ^ Each core can maintain a partial tag structure so they^ have an idea of where the data might be (complex!)^ ^ Every possible bank is looked up and the search^ propagates (either in series or in parallel) (complex!)
Examples: Frequency of Accesses
Dark^ Æ^ more^ accesses ÅOLTP (on-line^ transaction^ processing)^ Ocean
Æ
(scientific code)
Core^0 Core L1^ L1 D$^ I$
1 Core^2 L1 L1^ L1^ L1 D$^ I$^ D$^ I$
Core^3 Core L1^ L1 D$^ I$
4 Core^5 L1 L1^ L1^ L1 D$^ I$^ D$^ I$
Core^6 Core L1^ L1 D$^ I$
7 L1 L1 D$^ I$
Shared^ L2^ Cache
and^ Directory
State L2^ Cache Controller Scalable^ Non
‐broadcast^ Interconnect
Core^0 L1^ L1 D$^ I$^ L2^ $
Core^1 L1^ L1 D$^ I$^ L2^ $
Core^2 L1^ L1 D$^ I$^ L2^ $
Core^3 L1^ L1 D$^ I$^ L2^ $
Core^4 L1^ L1 D$^ I$^ L2^ $
Core^5 L1^ L1 D$^ I$^ L2^ $
Core^6 L1^ L1 D$^ I$^ L2^ $
Core^7 L1^ L1 D$^ I$^ L2^ $
Memory^ Controller
for^ off‐chip^ access
A^ single^ tile^ composed of^ a^ core,^ L1^ caches,
and a^ bank^ (slice)
of^ the shared L2 cache The^ cache^ controller forwards^ address
requests to^ the^ appropriate
L2^ bank and^ handles^
coherence operations
Bottom^ die^ with^ cores and^ L1^ caches
L2^ $^ Core^0 L1^ L1 D$^ I$
L2^ $^ Core^1 L1^ L1 D$^ I$
L2^ $^ Core^2 L1^ L1 D$^ I$
L2^ $^ Core^3 L1^ L1 D$^ I$
Memory^ controller
for^ off‐chip^ access^
Top^ die^ with L2^ cache^ banks Each^ core^ has low‐latency^ access to^ one^ L2^ bank
Prefetching^ •^ Hardware prefetching can be employed for any of the^ cache levels^ •^ It can introduce cache pollution – prefetched data is^ often placed in a separate prefetch buffer to avoid^ pollution – this buffer must be looked up in parallel^ with the cache access^ •^ Aggressive prefetching increases “coverage”, but leads^ to a reduction in “accuracy”
Æ^ wasted memory bandwidth
•^ Prefetches must be timely: they must be issued sufficiently^ in advance to hide the latency, but not too early (to avoid^ pollution and eviction before use)
Stream Buffers^ •^ Simplest form of prefetch: on every miss, bring in^ multiple cache lines^ •^ When you read the top of the queue, bring in the next line
L^
Stream buffer
Sequential lines
Compiler Optimizations^ •^ Loop interchange: loops can be re-ordered to exploit^ spatial locality^ for (j=0; j<100; j++)^ for (i=0; i<5000; i++)
x[i][j] = 2 * x[i][j]; is converted to… for (i=0; i<5000; i++) for (j=0; j<100; j++) x[i][j] = 2 * x[i][j];
Exercise^ for (i=0;i<N;i++)^ for (j=0;j<N;j++) {^ r=0;^ for (k=0;k<N;k++)
r = r + y[i][k] * z[k][j]; x[i][j] = r; }
for (jj=0; jj<N; jj+= B) for (kk=0; kk<N; kk+= B) for (i=0;i<N;i++)^ for (j=jj; j< min(jj+B,N); j++) {^ r=0;^ for (k=kk; k< min(kk+B,N); k++)^ r = r + y[i][k] * z[k][j];^ x[i][j] = x[i][j] + r;^ } y^ z
y^ z x
•^ Re-organize data accesses so that a piece of data is^ used a number of times before moving on… in other^ words, artificially create temporal locality^ x
Exercise^ •^ Original code could have 2N
3 2 + Nmemory accesses,
while the new version has 2N
32 /B + N
for (i=0;i<N;i++)^ for (j=0;j<N;j++) {^ r=0;^ for (k=0;k<N;k++)^ r = r + y[i][k] * z[k][j];^ x[i][j] = r;^ }
for (jj=0; jj<N; jj+= B) for (kk=0; kk<N; kk+= B) for (i=0;i<N;i++)^ for (j=jj; j< min(jj+B,N); j++) {^ r=0;^ for (k=kk; k< min(kk+B,N); k++)^ r = r + y[i][k] * z[k][j];^ x[i][j] = x[i][j] + r;^ } y^ z
y^ z x
x
Title^ •^ Bullet