Download LR Parsing, Table Construction - Lecture Slides | CS 4610 and more Study notes Programming Languages in PDF only on Docsity!
LR Parsing LR Parsing
Table Construction Table Construction
Outline
- (^) Review of bottom-up parsing
- (^) Computing the parsing DFA
- (^) Closures, LR(1) Items, States
- (^) Transitions
- (^) Using parser generators
Bottom-up Parsing (Review)
- (^) A bottom-up parser rewrites the input string
to the start symbol
- (^) The state of the parser is described as
α I γ
- (^) α is a stack of terminals and non-terminals
- (^) γ is the string of terminals not yet examined
- Initially:^ I^ x 1
x
2
... x
n
Shift and Reduce Actions (Review)
- (^) Recall the CFG: E! int | E + (E)
- (^) A bottom-up parser uses two kinds of actions:
- (^) Shift pushes a terminal from input on the stack E + ( I int ) ⇒ E + (int I )
- (^) Reduce pops 0 or more symbols off of the stack (production RHS) and pushes a non-terminal on the stack (production LHS) E + (E + ( E ) I ) ⇒ E +(E I )
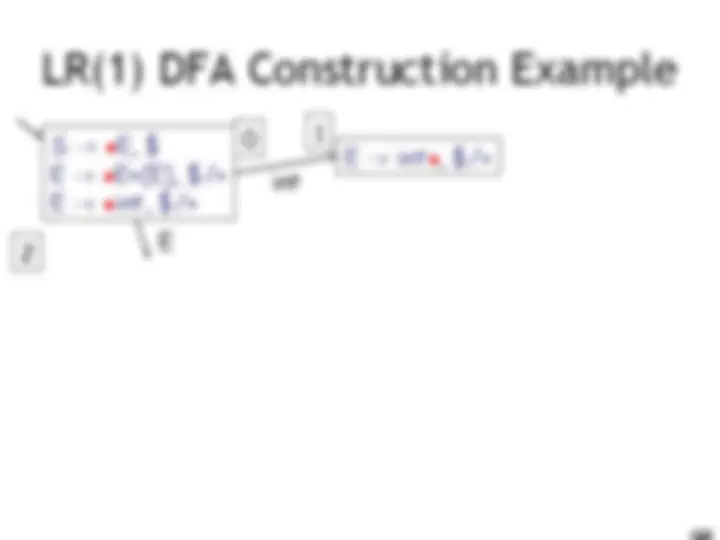
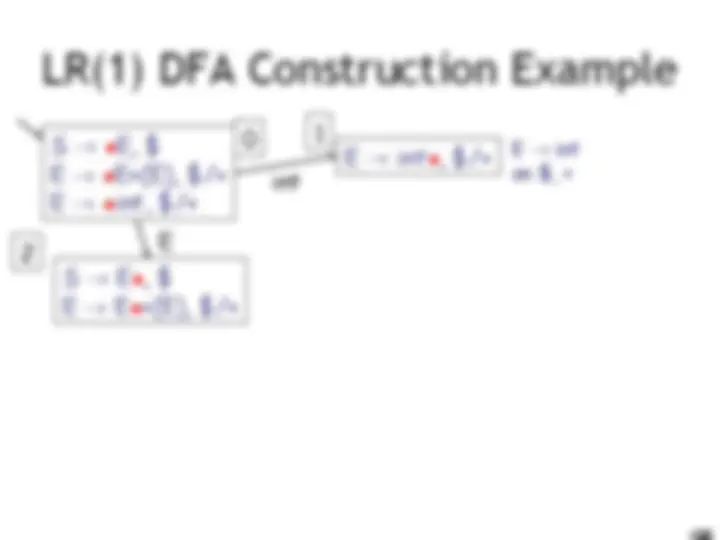
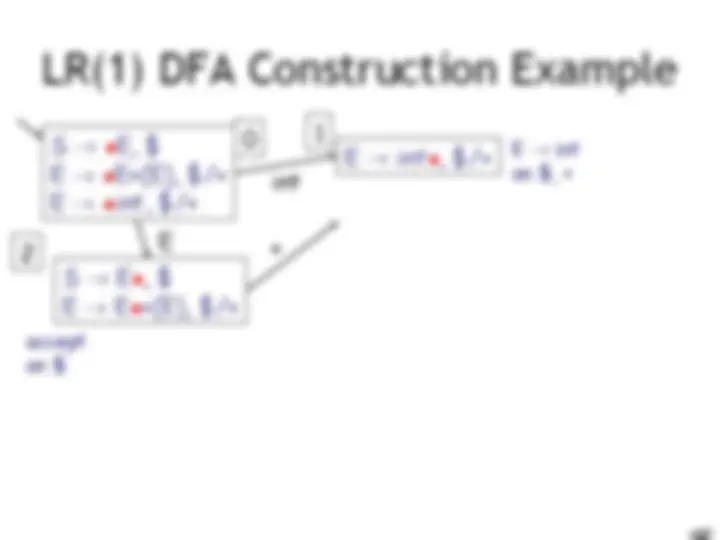
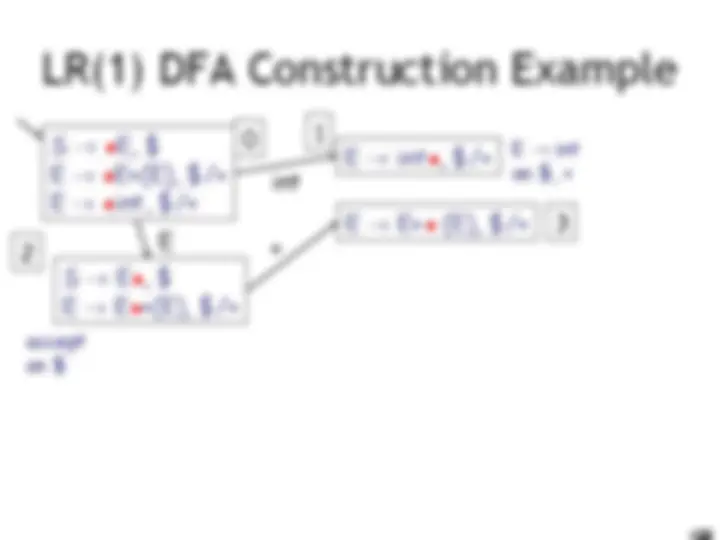
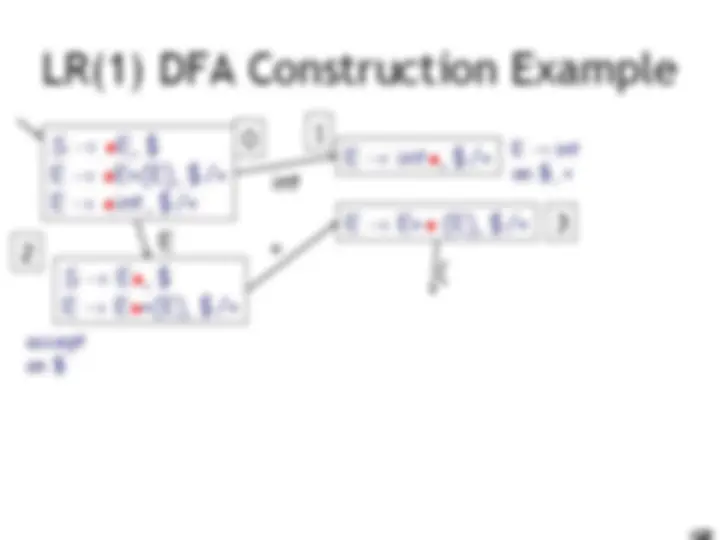
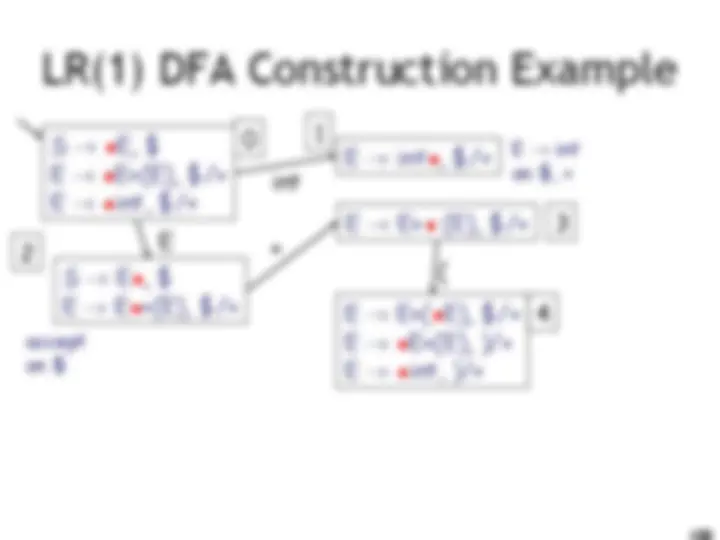
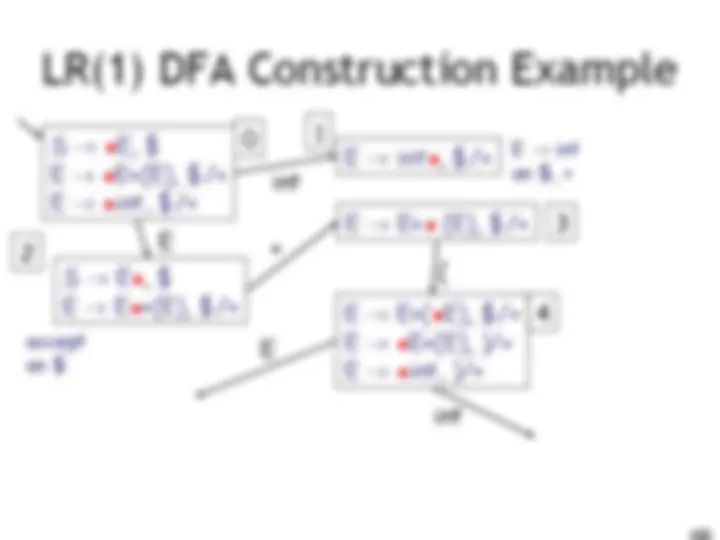
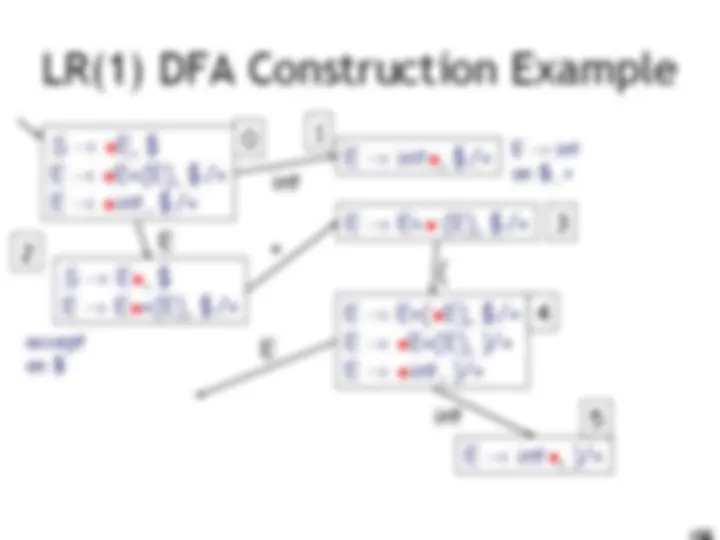
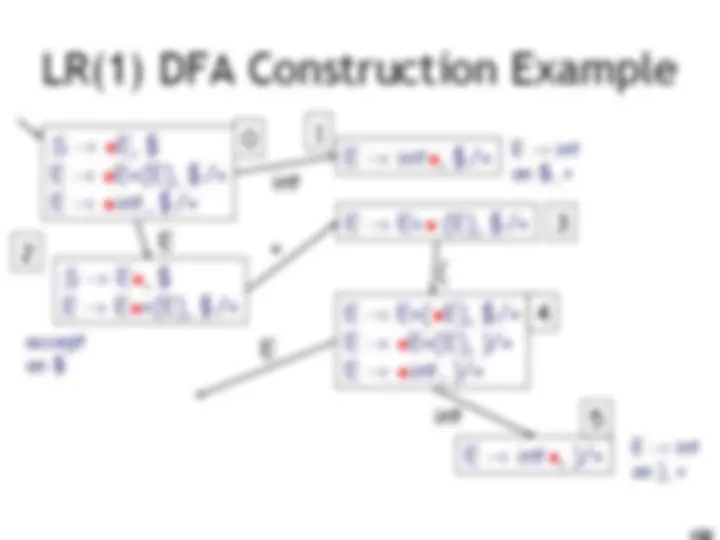
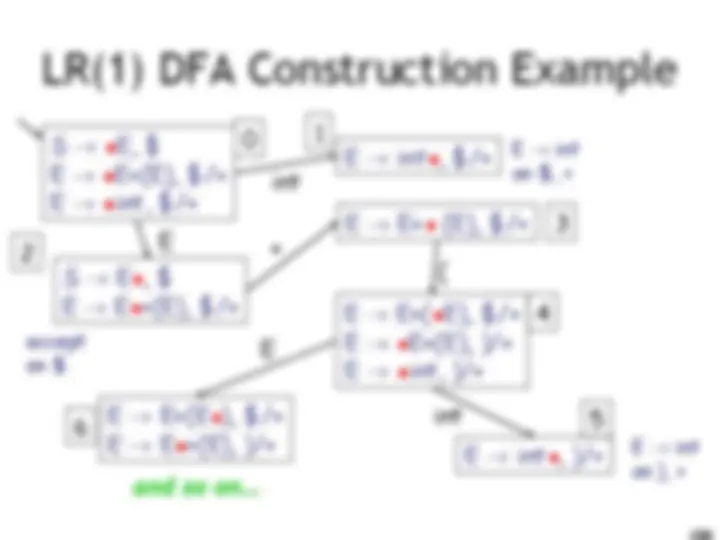
LR(1) Parsing. An Example
int E! int on $, + accept on $ E! int on ), + E! E + (E) on $, + E! E + (E) on ), + (
E int 10 9 11 0 1 2 3 4 6 5 8 7
E
) ( I int + (int) + (int)$ shift int I + (int) + (int)$ E! int E I + (int) + (int)$ shift(x3) E + (int I ) + (int)$ E! int E + (E I ) + (int)$ shift E + (E) I + (int)$ E! E+(E) E I + (int)$ shift (x3) E + (int I )$ E! int E + (E I )$ shift E + (E) I $ E! E+(E) E I $ accept int E )
End of review
LR(1) Table Construction Three hours later, you can finally parse E! E + E | int
Parsing Contexts
- (^) Consider the state:
- (^) The stack is E + ( I int ) + ( int )
- (^) Context:
- (^) We are looking for an E! E + ( ² E )
- (^) Have have seen E + ( from the right-hand side
- (^) We are also looking for E! ² int or E! ² E + ( E )
- (^) Have seen nothing from the right-hand side
- (^) One DFA state describes several contexts E int + ( int ) + ( int ) Red dot = where we are.
Note
- (^) The symbol I was used before to separate the
stack from the rest of input
- (^) α I γ, where α is the stack and γ is the remaining string of terminals
- (^) In LR(1) items ² is used to mark a prefix of a
production rhs:
X! α²β , a
- (^) Here β might contain non-terminals as well
- (^) In both case the stack is on the left
Convention
- (^) We add to our grammar a fresh new start
symbol S and a production S! E
- (^) Where E is the old start symbol
- (^) No need to do this if E had only one production
- (^) The initial parsing context contains:
S! ² E, $
- (^) Trying to find an S as a string derived from E$
- (^) The stack is empty
LR(1) Items (Cont.)
- (^) Consider a context with the item
E! E + ( ² E ) , +
- (^) We expect next a string derived from E ) +
- (^) There are two productions for E E! int and E! E + ( E)
- (^) We describe this by extending the context
with two more items:
E! ² int, )
E! ² E + ( E ) , )
The Closure Operation
- (^) The operation of extending the context with
items is called the closure operation
Closure(Items) = repeat for each [X! α² Y β , a] in Items for each production Y! γ for each b 2 First( β a) add [Y! ²γ , b] to Items until Items is unchanged
Constructing the Parsing DFA (2)
- (^) An LR(1) DFA state is a closed set of LR(1)
items
- (^) This means that we performed Closure
- (^) The start state contains [S! ² E, $]
- (^) A state that contains [X! α² , b] is labeled
with “ reduce with X! α on b ”
- (^) And now the transitions …