Download Machine learning Worksheet and more Study Guides, Projects, Research Machine Learning in PDF only on Docsity!
EXPERIMENT -
AIM: Decision Tree
A Decision Tree is a Flow Chart, and can help you make decisions based
on previous experience.
Decision tree learning is a method commonly used in data mining. The
goal is to create a model that predicts the value of a target variable
based on several input variables. A decision tree is a simple
representation for classifying examples.
OBJECTIVES:
A decision tree is a flowchart-like structure in which each internal node
represents a test on a feature (e.g. whether a coin flip comes up heads
or tails) , each leaf node represents a class label (decision taken after
computing all features) and branches represent conjunctions of
features that lead to those class.
CODE:
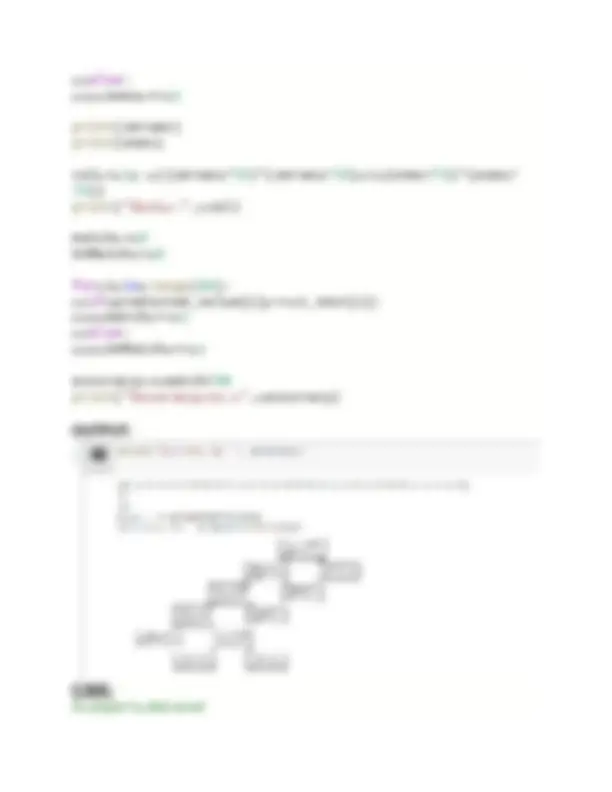
import pandas as pd from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import classification_report from sklearn import tree as t import matplotlib.pyplot as plt %matplotlib inline iris=load_iris() dir(iris) df=pd.DataFrame(iris.data, columns=iris.feature_names) df["target"]=iris.target x=df.drop(["target"], axis="columns") y=df.target x_train, x_test, y_train, y_test=train_test_split(x,y,t est_size=0.20) model=DecisionTreeClassifier(max_depth= 2 ) model.fit(x_train,y_train) #training the model #model.score(x_test,y_test) ypred=model.predict(x_test) #print(classification_report(ypred,y_test)) plt.figure(figsize=( 15 , 10 )) t.plot_tree(model, filled=True) plt.show()
OUTPUT
else: ones += 1 print(zeroes) print(ones) val = 1 - ((zeroes/ 70 )(zeroes/ 70 ) + (ones/ 70 )(ones/ 70 )) print("Gini :", val) match = 0 UnMatch = 0 for i in range( 30 ): if predicted_value[i] == t_test[i]: match += 1 else: UnMatch += 1 accuracy = match/ 30 print("Accuracy is: ", accuracy)
OUTPUT:
CODE:
import dataset
dataset = pd.read_csv('Data.csv')
alternatively open up .csv file to read data
dataset = np.array( [['Asset Flip', 100 , 1000 ], ['Text Based', 500 , 3000 ], ['Visual Novel', 1500 , 5000 ], ['2D Pixel Art', 3500 , 8000 ], ['2D Vector Art', 5000 , 6500 ], ['Strategy', 6000 , 7000 ], ['First Person Shooter', 8000 , 15000 ], ['Simulator', 9500 , 20000 ], ['Racing', 12000 , 21000 ], ['RPG', 14000 , 25000 ], ['Sandbox', 15500 , 27000 ], ['Open-World', 16500 , 30000 ], ['MMOFPS', 25000 , 52000 ], ['MMORPG', 30000 , 80000 ] ])
print the dataset
print(dataset)
OUTPUT:
CODE:
arange for creating a range of values
from min value of X to max value of X
with a difference of 0.01 between two
consecutive values
X_grid = np.arange(min(X), max(X), 0.01)
reshape for reshaping the data into
a len(X_grid)*1 array, i.e. to make
a column out of the X_grid values
X_grid = X_grid.reshape((len(X_grid), 1 ))
scatter plot for original data
plt.scatter(X, y, color = 'red')
plot predicted data
plt.plot(X_grid, regressor.predict(X_grid), color = 'bl ue')
specify title
plt.title('Profit to Production Cost (Decision Tree Reg ression)')
specify X axis label
plt.xlabel('Production Cost')
specify Y axis label
plt.ylabel('Profit')
show the plot
plt.show()
OUTPUT: