



CH-1
INTRODUCTION TO BIG
DATA
BY: PROF. AJAYSINH RATHOD



















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
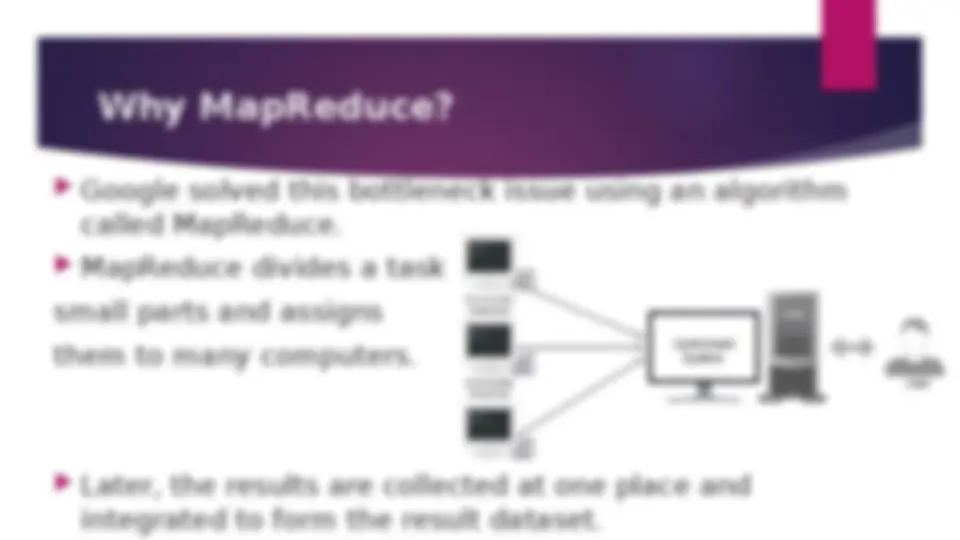
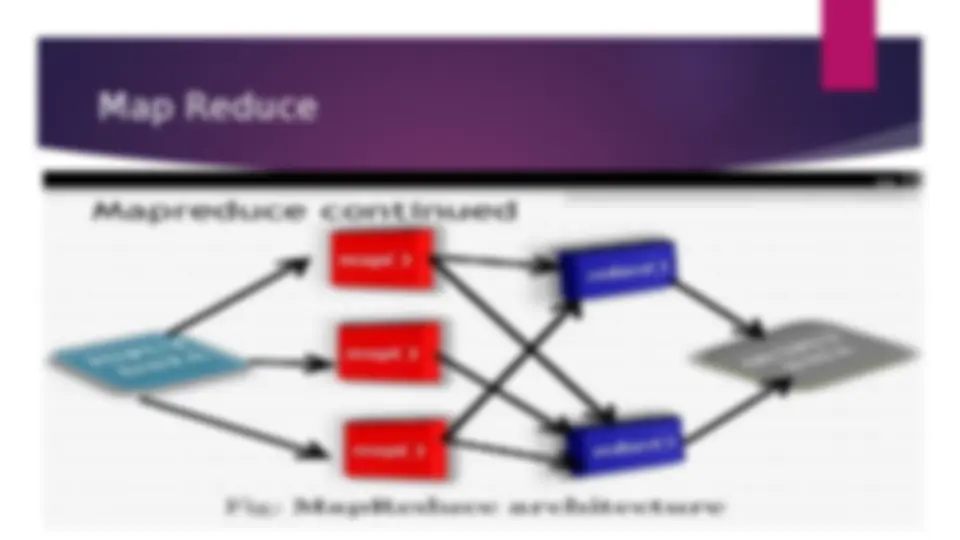
Why MapReduce was developed by Google to address the limitations of traditional enterprise systems in handling large volumes of data. MapReduce is a programming model for processing large datasets distributed on a large cluster using the concept of Divide and Conquer. It consists of two methods: map() and Reduce(). an overview of how MapReduce works, including its architecture, phases, and example use cases.
Typology: Study notes
1 / 32

This page cannot be seen from the preview
Don't miss anything!
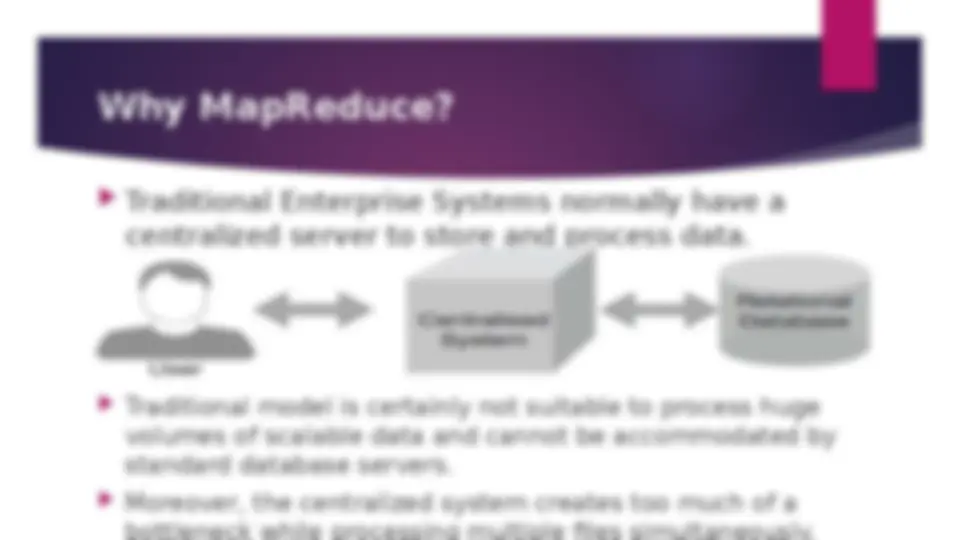
Why MapReduce?
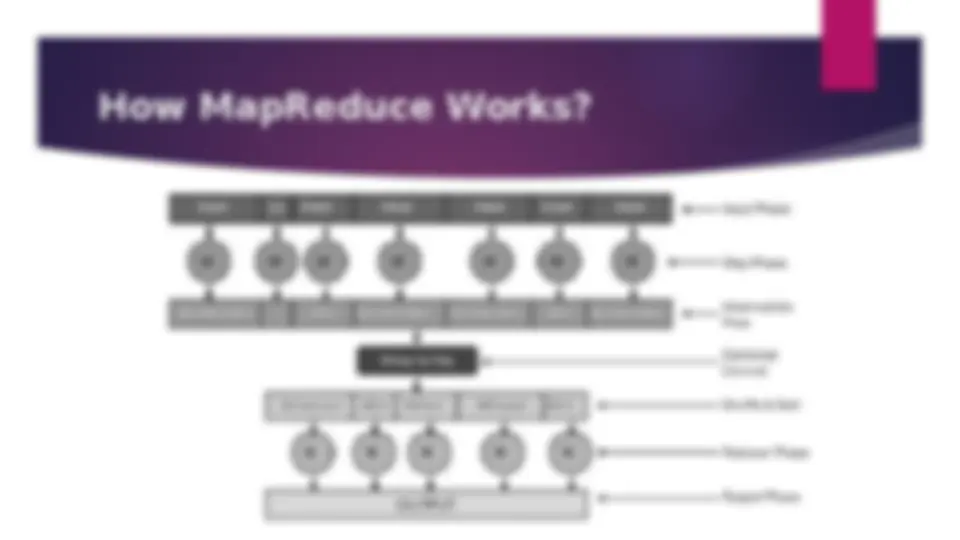
How MapReduce Works? (^) The MapReduce algorithm contains two important tasks, namely Map and Reduce. (^) sorting and filtering. The Map task takes a set of data and converts it into another set of data, (^) where individual elements are broken down into tuples (key- value pairs). (^) sorting and filtering. The Reduce task takes the output from the Map as an input and combines (^) those data tuples (key-value pairs) into a smaller set of tuples. (^) The reduce task is always performed after the map job.
Map Reduce
Map Reduce algorithms
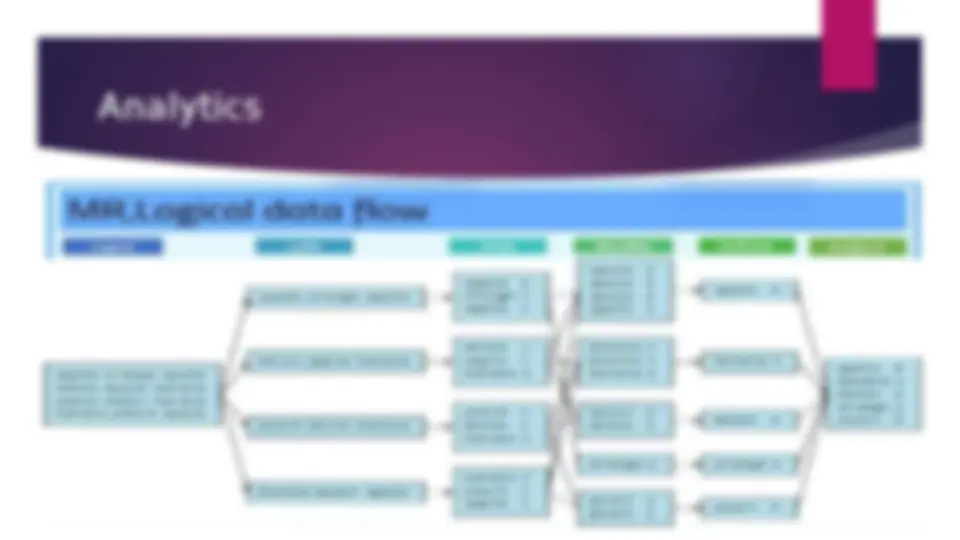
Big Data and Its Sources
Mapper function maps the split files and provide input to reducer. Mapper ( filename , file –contents): for each word in file-contents: emit (word , 1).
Reducer function clubs the input provided by mapper and produce output Reducer ( word , values): sum=0; for each value in values: sum=sum + value emit(word , sum).
How MapReduce Works? The MapReduce algorithm contains two important tasks, namely Map and Reduce.
another set of data, where individual elements are broken down into tuples (key-value pairs).
input and combinesthose data tuples (key-value pairs) into a smaller set of tuples. The reduce task is always performed after the map job.
How MapReduce Works?
How MapReduce Works? (^) Shuffle and Sort − The Reducer task starts with the Shuffle and Sort step. It downloads the grouped key-value pairs onto the local machine, where the Reducer is running. The individual key-value pairs are sorted by key into a larger data list. The data list groups the equivalent keys together so that their values can be iterated easily in the Reducer task. (^) Reducer − The Reducer takes the grouped key-value paired data as input and runs a Reducer function on each one of them. Here, the data can be aggregated, filtered, and combined in a number of ways, and it requires a wide range of processing. Once the execution is over, it gives zero or more key-value pairs to the final step. (^) Output Phase − In the output phase, we have an output formatter that translates the final key-value pairs from the Reducer function and writes them onto a file using a record writer.
How MapReduce Works? (^) Shuffle and Sort − The Reducer task starts with the Shuffle and Sort step. It downloads the grouped key-value pairs onto the local machine, where the Reducer is running. The individual key-value pairs are sorted by key into a larger data list. The data list groups the equivalent keys together so that their values can be iterated easily in the Reducer task. (^) Reducer − The Reducer takes the grouped key-value paired data as input and runs a Reducer function on each one of them. Here, the data can be aggregated, filtered, and combined in a number of ways, and it requires a wide range of processing. Once the execution is over, it gives zero or more key-value pairs to the final step. (^) Output Phase − In the output phase, we have an output formatter that translates the final key-value pairs from the Reducer function and writes them onto a file using a record writer.
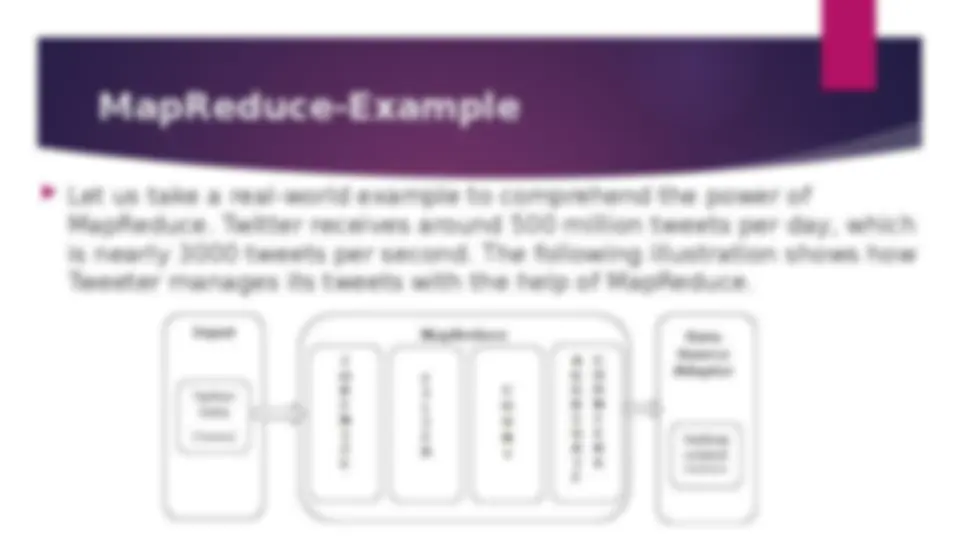
How MapReduce Works? (^) As shown in the illustration, the MapReduce algorithm performs the following actions − (^) Tokenize − Tokenizes the tweets into maps of tokens and writes them as key-value pairs. (^) Filter − Filters unwanted words from the maps of tokens and writes the filtered maps as key-value pairs. (^) Count − Generates a token counter per word. Aggregate Counters − Prepares an aggregate of similar counter values into small manageable units.