Download MapReduce: A Simplified Approach to Data Processing on Large Clusters - Prof. Anton W. Boh and more Exams Computer Science in PDF only on Docsity!
MapReduce
Source: MapReduce: Simplified Data Processing on Large ClustersJeffrey Dean and Sanjay Ghemawat, Google inc. (wim bohm, cs.colostate.edu) Except as otherwise noted, the content of this presentation is licensed under the Creative Commons Attribution 2.5 license.
MapReduce Concept �^
Simple implicitly // programming model^ �
Based on Lisp’s Map and Reduce higher order functions �^
Lisp
Map(fM,L) = fM(first(L)) ^ Map(fM, rest(L))
�^
Lisp: Reduce(fR,L) = fR(first(L), Reduce(fR, rest(L))) �^
Lisp MapReduce(fM,fR,L) =Reduce(fR,Map(fm,L)) �^
Lisp: Lots of Irritating Superfluous Parentheses �^
(left base cases out)
�^
Very savvy implementation^ �
Hi throughput, hi performance, rack aware �^
Functional: RTS takes care of FT, restart, Distribution (//ism)
Map and Reduce^ �
Map: take a
set of (key,value) pairs and
generate a set of intermediate (key,value)pairs by applying some function
f
to all these
pairspairs
�^
Reduce: merge all pairs with same keyapplying a reduction function
R
on the values
�^
f and R are user defined
�^
All implemented in a non functional languagesuch as java, C++, python
Wordcount
Map(String key, String
value)
// key: doc name, value doc contentsfor each word w in value
EmitIntermediate
(w, “1”);
EmitIntermediate
(w, “1”);
Reduce(String key, Iterator values) // key: word, values: list of countsint sum = 0;for each v in values sum += ParseInt(v);Emit((String) sum);
Example: Pi-Estimator
�^
Idea: generate random points in a square �^
Count how many are inside circle, how many in thesquare (producing area estimates)
Square area
As = 4 * r
2
(^2) r = As / 4
Square area
As = 4 * r
2
(^2) r = As / 4
Circle area
Ac = pi * r
2
pi = Ac / r
2
pi =
4*Ac / As
Example of Monte Carlo method: simulating a physicalphenomenon using many random samples
r
Worker /
Multi-threading
view
�^
Master:get input params (nWorkers, nPoints)for(i=0; i< nWorkers; i++)
thrCreate(i, nPoints);
for(i=0; i< nWorkers; i++)
join;
As = 0; Ac = 0;As = 0; Ac = 0; for(i=0; i<nWorkers; i++) {As += nPoints; Ac+=ncPoints[i];}piEst = =
4*Ac / As;
�^
Slave
:i cPoints[i]=0;for(i=0; i<nPoints;i++) {
create 2 random pts x,y in (-. ..
.5);
if (sqrt(xx+yy)<.5) cPoints[i]++; }
We want MapReduce to be parallel!^ �
Just like in multithreading, we need somekind of spawn(id,func,data) construct � In Lisp the spawn is taken care of by higher^ order function mechanismorder function mechanism
reduce(rFun,map(mFun,inList))
�^
In MapReduce we use method
override
to
define our specific versions of
map
and
reduce
, and we have a
Driver
that creates a
Job Configuration
to provide parallelism.
We
need to communicate results
�^
Somehow the map processes need input(key1,val1) pairs and need to produceintermediate (key2,val2) pairs, that the reduce process can pick up.reduce process can pick up.
�^
But we are in a distributed environment…What provides a shared name space?
the file system! functional HDFS allows for parallelism
Parallel writes vs multithreading^ �
Parallel writes are like multiple threadsappending to a mutex-lock protected list. � The list is just a collection of unordered^ records.records. � The reducer has to be aware of this:
�^
Either it can impose an order �^
Or it can make sure the reduction function is associative andcommutative �^
Take // grep: if you want outcomes sorted by line #, makeline# part of the key, and sort
MapReduce for PiEstimator � MapReduce is integrated into Eclipse
�^
We need to have the MapReduce plugins to create aMapReduce Eclipse perspective. �^
MapReduce projects contain three classes:^ 1. A
Driver
(like the master in the multithreading case)
- A
Driver
(like the master in the multithreading case)
Creating a configuaration, defining #mappers, #reducers,starting the app, dealing with the final result gathering.
- A
mapper
(inherited class implementing mapper interface)
Getting data from files in a
directory
specified by driver.
- A
reducer
(inherited class implementing reducer interface)
Getting data from files in a
directory
specified by driver,
produced by mappers.
Mypi2 on Laptop
MultipleMultiple SequentialMappers donot bring theperformancedown
Mypi2 on Hadoop cluster
Twenty parallelMappers: five foldfive fold speedupTwelve seemsbetter
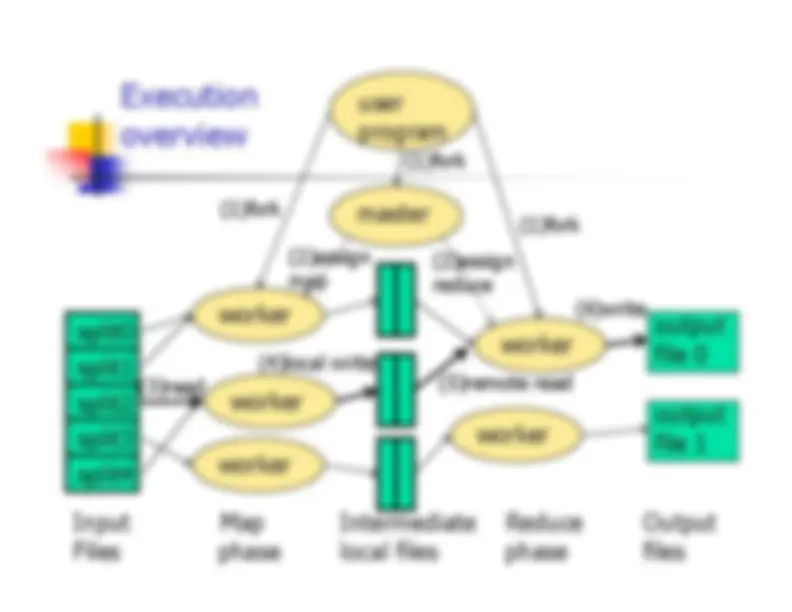
MapReduce Google implementation
�^
Large clusters of commodity PCs connected withswitched Ethernet. Luiz A.Barrosso, Jeffrey Dean, and Urs Hılzle. Web search for a planet: the Google cluster architecture. IEEE Micro, 23(2):
the Google cluster architecture. IEEE Micro, 23(2):
�^
Nodes: dual-processor x86, Linux,2-4GB of memory
�^
Storage: local disks on individual nodes
�^
GFS (Google’s original file system, used by HDFS)
�^
Jobs (sets of tasks) submitted to scheduler,IMPLICITLY mapped to set of available nodes
worker
(6)write
userprogram master
(1)fork
(1)fork
(1)fork
(2)assignmap
(2)assignreduce
Executionoverview
split0 split1 split2 split3 split
worker^ worker worker
(3)read
Input
Map
Intermediate
Reduce
Output
Files
phase
local files
phase
files
(4)local write
worker worker (5)remote read
outputfile 0 outputfile 1
(6)write