



Matrix differential calculus
10-725 Optimization
Geoff Gordon
Ryan Tibshirani





























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
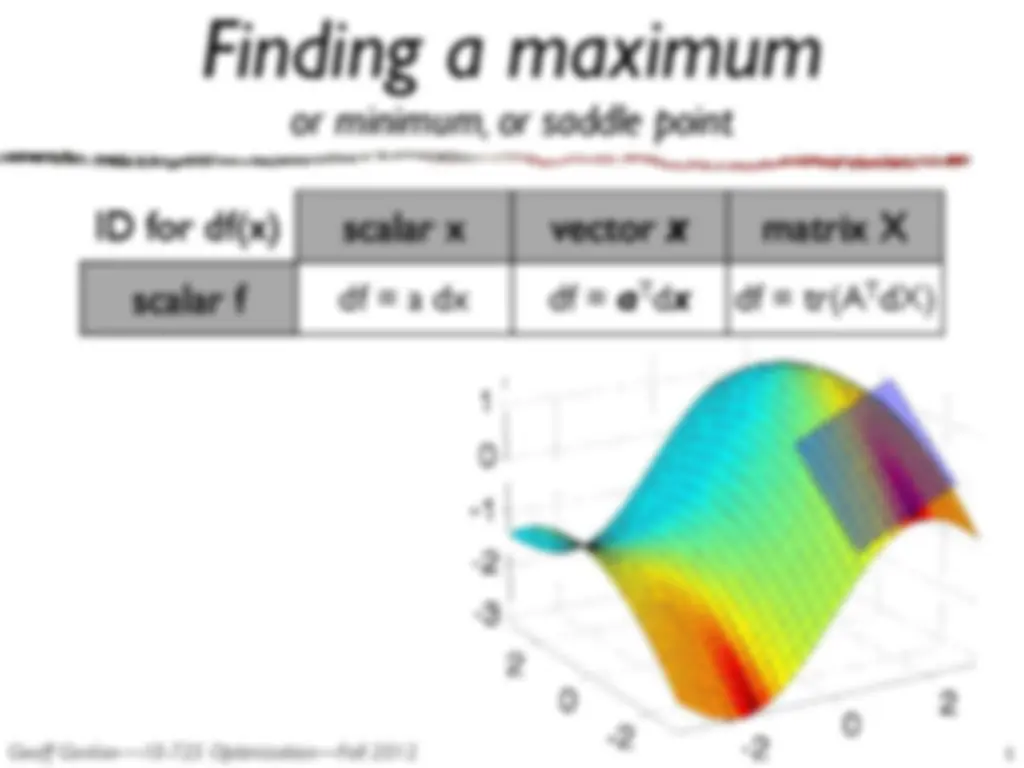
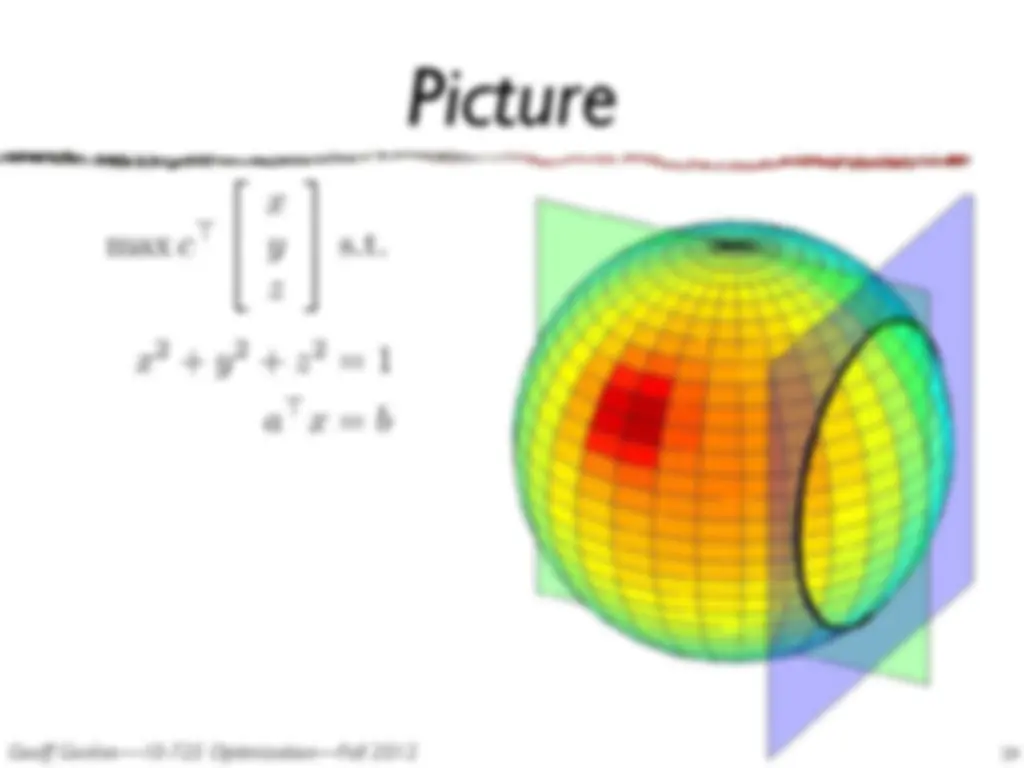
These notes cover matrix differential calculus, including matrix differentials, chain rule, product rule, and identities. The document also discusses finding a maximum or minimum of a scalar function or matrix function using the coefficient of dX being set to zero. Examples are provided for Infomax Independent Component Analysis (ICA) and Newton's method.
Typology: Exams
1 / 40

This page cannot be seen from the preview
Don't miss anything!
ï 3 ï 2 ï 1 0 1 2 3 ï 1 ï0. 0
1
2
T
T
T
T
Ex: Infomax ICA
ï 10 ï 5 0 5 10 ï 10 ï 5
Wxi 0 .2 0 .4 0. 6 0. 8
yi ï 10 ï 5 0 5 10 ï 10 ï 5
xi
i
-T
T
-T
T
d
d
d
0 1 2 ï 1 ï0. 0
1