



High Performance Computing
Lecture 9
Docsity.com








Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Some concept of High Performance Computing are Addressing Modes, Program Execution, Basic Computer Organization, Control Hazard Solutions, Least Recently Used, Memory Hierarchy Progression. Main points of this lecture are: Mips, Function, Main Memory, Program, Instructions, Statically Allocated, Stack Allocated, Heap Allocated, Conditional Branch Instructions, Floating Point
Typology: Slides
1 / 16

This page cannot be seen from the preview
Don't miss anything!
2
void A() { … B(5); … } void B (int x) { int a, b; … return(); } ADDI R1, R0, 5 ADDI R29, R29, 4 SW 0(R29), R JAL B ADDI R29, R29, 4 SW 0(R29), R B : … 5 (int x) Return address Local int a Local int b ADDI R29, R29, 8 … SUBI R29, R29, 16 LW R31, 8(R29) JR R Function Call/Return Stack
4
5
What about a condition like R1 >= R You could use the BGEZ instruction Idea: Rewrite the condition as (R1 – R2) >= 0 SUB R3, R1, R2 / R3 R1 - R BGEZ R3, target / if R3 >= 0 goto target Problem: Possibility of overflow If R2 < 0, PC PC + 4 - 16 BEQ, BNE, BLTZ R2, - 16 BGEZ, BLEZ, BLTZ, BGTZ Conditional Branch Mnemonics Example Meaning
7
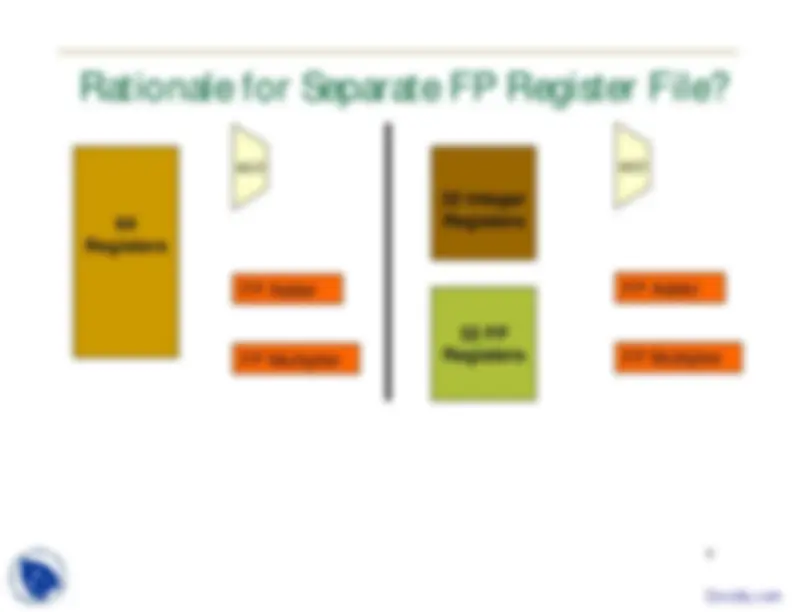
32 32b floating point registers F0-F A double (64b floating point value) occupies 2 registers Even-odd pair, such as F0,F Addressed as F
Loads: LF (load float), LD (load double) Arithmetic: ADDF (add float), ADDD (add double)
8
ALU FP Adder FP Multiplier 64 Registers 32 Integer Registers 32 FP Registers ALU FP Adder FP Multiplier
10
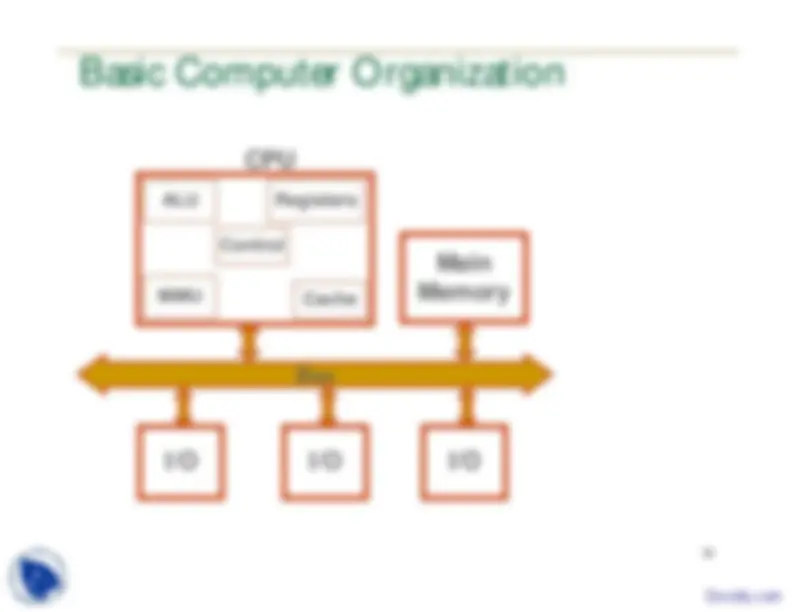
Cache Main Memory I/O Bus I/O I/O MMU ALU Registers CPU Control
11
13
PC to memory Instruction in IR PC++; Decode Op1 address calculation Op1 fetched Op2 address calculation Op2 fetched Op done Write result Processor/Memory Speed disparity ~2 orders of magnitude
14
PC to memory Instruction in IR PC++; Decode Op1 address calculation Op1 fetched Op2 fetched Op done Write result
16