Download Molecular genetic testing and more Lecture notes Remedial Biology in PDF only on Docsity!
The effect of mutations on Drosophila development. Scanning electron micrographs of the eye from ( left ) a wild-type fly, ( middle ) a fly carrying a dominant developmental mutation produced by recombinant DNA methods, and ( right ) a fly carrying a suppresor mutation that partially reverses the effect of the dominant mutation. [Courtesy of Ilaria Rebay, Whitehead Institute, MIT.]
MOLECULAR GENETIC
TECHNIQUES AND GENOMICS
I
n previous chapters, we were introduced to the variety of tasks that proteins perform in biological systems. How some proteins carry out their specific tasks is described in detail in later chapters. In studying a newly discovered protein, cell biologists usually begin by asking what is its function, where is it located, and what is its structure? To an- swer these questions, investigators employ three tools: the gene that encodes the protein, a mutant cell line or organ- ism that lacks the function of the protein, and a source of the purified protein for biochemical studies. In this chapter we consider various aspects of two basic experimental strate- gies for obtaining all three tools (Figure 9-1). The first strategy, often referred to as classical genetics, begins with isolation of a mutant that appears to be defective in some process of interest. Genetic methods then are used to
O U T L I N E
9.1 Genetic Analysis of Mutations to Identify
and Study Genes
9.2 DNA Cloning by Recombinant DNA Methods
9.3 Characterizing and Using Cloned DNA
Fragments
9.4 Genomics: Genome-wide Analysis of Gene
Structure and Expression
9.5 Inactivating the Function of Specific Genes
in Eukaryotes
9.6 Identifying and Locating Human Disease Genes
identify the affected gene, which subsequently is isolated from an appropriate DNA library, a large collection of indi- vidual DNA sequences representing all or part of an organ- ism’s genome. The isolated gene can be manipulated to produce large quantities of the protein for biochemical ex- periments and to design probes for studies of where and when the encoded protein is expressed in an organism. The second strategy follows essentially the same steps as the classical approach but in reverse order , beginning with iso- lation of an interesting protein or its identification based on analysis of an organism’s genomic sequence. Once the corresponding gene has been isolated from a DNA library, the gene can be altered and then reinserted into an organism. By observing the effects of the altered gene on the organism, researchers often can infer the function of the normal protein. An important component in both strategies for studying a protein and its biological function is isolation of the cor- responding gene. Thus we discuss various techniques by which researchers can isolate, sequence, and manipulate spe- cific regions of an organism’s DNA. The extensive collections of DNA sequences that have been amassed in recent years has given birth to a new field of study called genomics, the molecular characterization of whole genomes and overall patterns of gene expression. Several examples of the types of information available from such genome-wide analysis also are presented.
Genetic Analysis of Mutations
to Identify and Study Genes
As described in Chapter 4, the information encoded in the DNA sequence of genes specifies the sequence and therefore
9.
the structure and function of every protein molecule in a cell. The power of genetics as a tool for studying cells and organ- isms lies in the ability of researchers to selectively alter every copy of just one type of protein in a cell by making a change in the gene for that protein. Genetic analyses of mutants de- fective in a particular process can reveal (a) new genes re- quired for the process to occur; (b) the order in which gene products act in the process; and (c) whether the proteins en- coded by different genes interact with one another. Before seeing how genetic studies of this type can provide insights into the mechanism of complicated cellular or developmental process, we first explain some basic genetic terms used throughout our discussion. The different forms, or variants, of a gene are referred to as alleles. Geneticists commonly refer to the numerous naturally occurring genetic variants that exist in populations, particularly human populations, as alleles. The term muta- tion usually is reserved for instances in which an allele is known to have been newly formed, such as after treatment of an experimental organism with a mutagen, an agent that causes a heritable change in the DNA sequence. Strictly speaking, the particular set of alleles for all the genes carried by an individual is its genotype. However, this term also is used in a more restricted sense to denote just the alleles of the particular gene or genes under examination. For experimental organisms, the term wild type often is used to designate a standard genotype for use as a reference in breed- ing experiments. Thus the normal, nonmutant allele will usu- ally be designated as the wild type. Because of the enormous naturally occurring allelic variation that exists in human populations, the term wild type usually denotes an allele that is present at a much higher frequency than any of the other possible alternatives. Geneticists draw an important distinction between the genotype and the phenotype of an organism. The phenotype
352 CHAPTER 9 •^ Molecular Genetic Techniques and Genomics
Protein Localization Biochemical studies Determination of structure
Cloned gene DNA sequencing Sequence comparisons with known proteins Evolutionary relationships
Genetic analysis Screening of DNA library
Expression in cultured cells
Sequencing of protein or database search to identify putative protein Isolation of corresponding gene
Gene inactivation
Mutant organism/cell Comparison of mutant and wild-type function
� FIGURE 9-1^ Overview of two strategies for determining the function, location, and primary structure of proteins. A mutant organism is the starting point for the classical genetic strategy (green arrows). The reverse strategy (orange arrows) begins with biochemical isolation of a protein or identification of a putative protein based on analysis of stored gene and protein sequences. In both strategies, the actual gene is isolated from a DNA library, a large collection of cloned DNA sequences representing an organism’s genome. Once a cloned gene is isolated, it can be used to produce the encoded protein in bacterial or eukaryotic expression systems. Alternatively, a cloned gene can be inactivated by one of various techniques and used to generate mutant cells or organisms.
frame of a gene ( frameshift mutation). Because alterations in the DNA sequence leading to a decrease in protein activity are much more likely than alterations leading to an increase or qualitative change in protein activity, mutagenesis usually produces many more recessive mutations than dominant mutations.
Segregation of Mutations in Breeding Experiments Reveals Their Dominance or Recessivity Geneticists exploit the normal life cycle of an organism to test for the dominance or recessivity of alleles. To see how
354 CHAPTER 9 •^ Molecular Genetic Techniques and Genomics
Cell division II
Cell division I
Synapsis of homologs
Sister chromatids
Premeiotic germ cell (2n)
Paternal homolog Maternal homolog
Gametes (1n)
Somatic cell (2n) DNA replication
Cell division
Sister chromatids
Daughter cells (2n)
Mitotic apparatus
MITOTIC CELL DIVISION
MEIOTIC CELL DIVISION
Paternal homolog Maternal homolog
Mitotic apparatus
DNA replication
Homologous chromosomes align
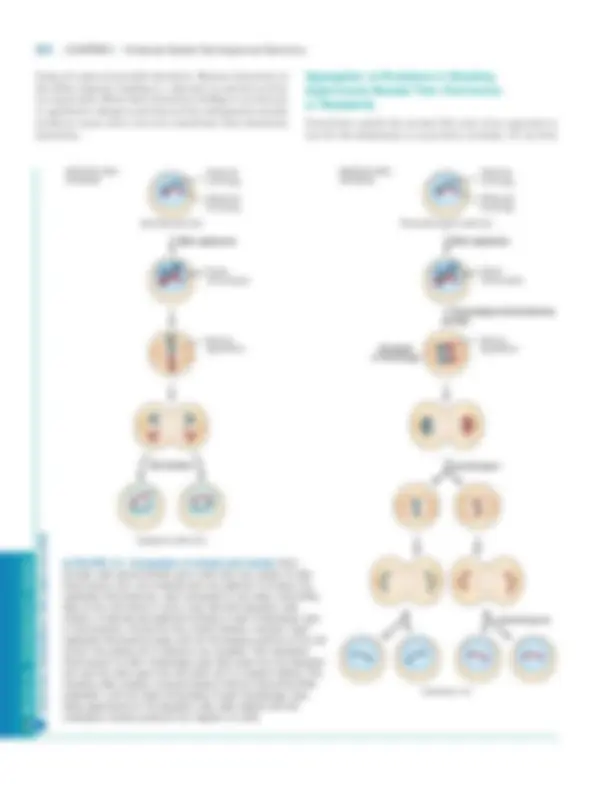
▲ FIGURE 9-3 Comparison of mitosis and meiosis. Both somatic cells and premeiotic germ cells have two copies of each chromosome (2 n ), one maternal and one paternal. In mitosis, the replicated chromosomes, each composed of two sister chromatids, align at the cell center in such a way that both daughter cells receive a maternal and paternal homolog of each morphologic type of chromosome. During the first meiotic division, however, each replicated chromosome pairs with its homologous partner at the cell center; this pairing off is referred to as synapsis. One replicated chromosome of each morphologic type then goes into one daughter cell, and the other goes into the other cell in a random fashion. The resulting cells undergo a second division without intervening DNA replication, with the sister chromatids of each morphologic type being apportioned to the daughter cells. Each diploid cell that undergoes meiosis produces four haploid (1 n ) cells.
M E D I A
C O N N E C T I O N S
Overview Animation: Life Cycle of a Cell
this is done, we need first to review the type of cell division that gives rise to gametes (sperm and egg cells in higher plants and animals). Whereas the body (somatic) cells of most multicellular organisms divide by mitosis, the germ cells that give rise to gametes undergo meiosis. Like somatic cells, premeiotic germ cells are diploid, containing two ho- mologs of each morphologic type of chromosome. The two homologs constituting each pair of homologous chromo- somes are descended from different parents, and thus their genes may exist in different allelic forms. Figure 9-3 depicts the major events in mitotic and meiotic cell division. In mi- tosis DNA replication is always followed by cell division, yielding two diploid daughter cells. In meiosis one round of DNA replication is followed by two separate cell divisions, yielding four haploid (1 n ) cells that contain only one chro- mosome of each homologous pair. The apportionment, or segregation, of the replicated homologous chromosomes to daughter cells during the first meiotic division is random; that is, maternally and paternally derived homologs segre- gate independently, yielding daughter cells with different mixes of paternal and maternal chromosomes. As a way to avoid unwanted complexity, geneticists usu- ally strive to begin breeding experiments with strains that are homozygous for the genes under examination. In such true- breeding strains, every individual will receive the same allele from each parent and therefore the composition of alleles will not change from one generation to the next. When a true-breeding mutant strain is mated to a true-breeding wild- type strain, all the first filial (F 1 ) progeny will be heterozy- gous (Figure 9-4). If the F 1 progeny exhibit the mutant trait, then the mutant allele is dominant; if the F 1 progeny exhibit the wild-type trait, then the mutant is recessive. Further crossing between F 1 individuals will also reveal different pat- terns of inheritance according to whether the mutation is dominant or recessive. When F 1 individuals that are het- erozygous for a dominant allele are crossed among them- selves, three-fourths of the resulting F 2 progeny will exhibit the mutant trait. In contrast, when F 1 individuals that are heterozygous for a recessive allele are crossed among them- selves, only one-fourth of the resulting F 2 progeny will ex- hibit the mutant trait. As noted earlier, the yeast Saccharomyces, an important experimental organism, can exist in either a haploid or a diploid state. In these unicellular eukaryotes, crosses between haploid cells can determine whether a mutant allele is domi- nant or recessive. Haploid yeast cells, which carry one copy of each chromosome, can be of two different mating types known as a and �. Haploid cells of opposite mating type can mate to produce a /� diploids, which carry two copies of each chromosome. If a new mutation with an observable pheno- type is isolated in a haploid strain, the mutant strain can be mated to a wild-type strain of the opposite mating type to produce a /� diploids that are heterozygous for the mutant allele. If these diploids exhibit the mutant trait, then the mutant allele is dominant, but if the diploids appear as wild-type, then the mutant allele is recessive. When a /� diploids are placed under starvation conditions, the cells
9.1 •^ Genetic Analysis of Mutations to Identify and Study Genes 355
First filial generation, F1; no offspring have mutant phenotype
Gametes
Second filial generation, F 2 : (^1) /4 of offspring have mutant phenotype
Gametes
Normal
or or
Mutant
Mutant
Segregation of recessive mutation Wild-type
b B b B
b /B
b/ b b / B B / b B/ B
All b
All B
b/ b B/ B
(b)
▲ FIGURE 9-4 Segregation patterns of dominant and recessive mutations in crosses between true-breeding strains of diploid organisms. All the offspring in the first (F 1 ) generation are heterozygous. If the mutant allele is dominant, the F 1 offspring will exhibit the mutant phenotype, as in part (a). If the mutant allele is recessive, the F 1 offspring will exhibit the wild-type phenotype, as in part (b). Crossing of the F 1 heterozygotes among themselves also produces different segregation ratios for dominant and recessive mutant alleles in the F 2 generation.
First filial generation, F 1 : all offspring have mutant phenotype
Gametes
Second filial generation, F 2 : (^3) /4 of offspring have mutant phenotype
Gametes
Normal
or or
Mutant
Mutant
Segregation of dominant mutation Wild-type
A a A a
A / a
A/ A A / a a^ /^ A^ a^ /^ a
All A
All a
A/ A a / a
(a)
if they carried a mutation affecting general cellular metabo- lism. Rather, at the nonpermissive temperature, the mutants of interest grew normally for part of the cell cycle but then ar- rested at a particular stage of the cell cycle, so that many cells at this stage were seen (Figure 9-6b). Most cdc mutations in yeast are recessive; that is, when haploid cdc strains are mated to wild-type haploids, the resulting heterozygous diploids are neither temperature-sensitive nor defective in cell division.
Recessive Lethal Mutations in Diploids Can Be Identified by Inbreeding and Maintained in Heterozygotes In diploid organisms, phenotypes resulting from recessive mutations can be observed only in individuals homozygous for the mutant alleles. Since mutagenesis in a diploid organ- ism typically changes only one allele of a gene, yielding het- erozygous mutants, genetic screens must include inbreeding steps to generate progeny that are homozygous for the mu- tant alleles. The geneticist H. Muller developed a general and efficient procedure for carrying out such inbreeding experi- ments in the fruit fly Drosophila. Recessive lethal mutations in Drosophila and other diploid organisms can be main- tained in heterozygous individuals and their phenotypic con- sequences analyzed in homozygotes. The Muller approach was used to great effect by C. Nüsslein-Volhard and E. Wieschaus, who systematically screened for recessive lethal mutations affecting embryogen- esis in Drosophila. Dead homozygous embryos carrying re- cessive lethal mutations identified by this screen were examined under the microscope for specific morphological defects in the embryos. Current understanding of the molec- ular mechanisms underlying development of multicellular or- ganisms is based, in large part, on the detailed picture of embryonic development revealed by characterization of these Drosophila mutants. We will discuss some of the fundamen- tal discoveries based on these genetic studies in Chapter 15.
Complementation Tests Determine Whether Different Recessive Mutations Are in the Same Gene In the genetic approach to studying a particular cellular process, researchers often isolate multiple recessive muta- tions that produce the same phenotype. A common test for determining whether these mutations are in the same gene or in different genes exploits the phenomenon of genetic complementation, that is, the restoration of the wild-type phenotype by mating of two different mutants. If two reces- sive mutations, a and b, are in the same gene, then a diploid organism heterozygous for both mutations (i.e., carrying one a allele and one b allele) will exhibit the mutant phenotype because neither allele provides a functional copy of the gene. In contrast, if mutation a and b are in separate genes, then heterozygotes carrying a single copy of each mutant allele
mutant phenotype is observed is called nonpermissive; a per- missive temperature is one at which the mutant phenotype is not observed even though the mutant allele is present. Thus mutant strains can be maintained at a permissive tem- perature and then subcultured at a nonpermissive tempera- ture for analysis of the mutant phenotype. An example of a particularly important screen for tem- perature-sensitive mutants in the yeast Saccharomyces cere- visiae comes from the studies of L. H. Hartwell and colleagues in the late 1960s and early 1970s. They set out to identify genes important in regulation of the cell cycle dur- ing which a cell synthesizes proteins, replicates its DNA, and then undergoes mitotic cell division, with each daughter cell receiving a copy of each chromosome. Exponential growth of a single yeast cell for 20–30 cell divisions forms a visible yeast colony on solid agar medium. Since mutants with a complete block in the cell cycle would not be able to form a colony, conditional mutants were required to study muta- tions that affect this basic cell process. To screen for such mutants, the researchers first identified mutagenized yeast cells that could grow normally at 23 �C but that could not form a colony when placed at 36 �C (Figure 9-6a). Once temperature-sensitive mutants were isolated, further analysis revealed that they indeed were defective in cell divi- sion. In S. cerevisiae, cell division occurs through a budding process, and the size of the bud, which is easily visualized by light microscopy, indicates a cell’s position in the cell cycle. Each of the mutants that could not grow at 36 �C was exam- ined by microscopy after several hours at the nonpermissive temperature. Examination of many different temperature- sensitive mutants revealed that about 1 percent exhibited a distinct block in the cell cycle. These mutants were therefore designated cdc ( c ell- d ivision c ycle) mutants. Importantly, these yeast mutants did not simply fail to grow, as they might
9.1 •^ Genetic Analysis of Mutations to Identify and Study Genes 357
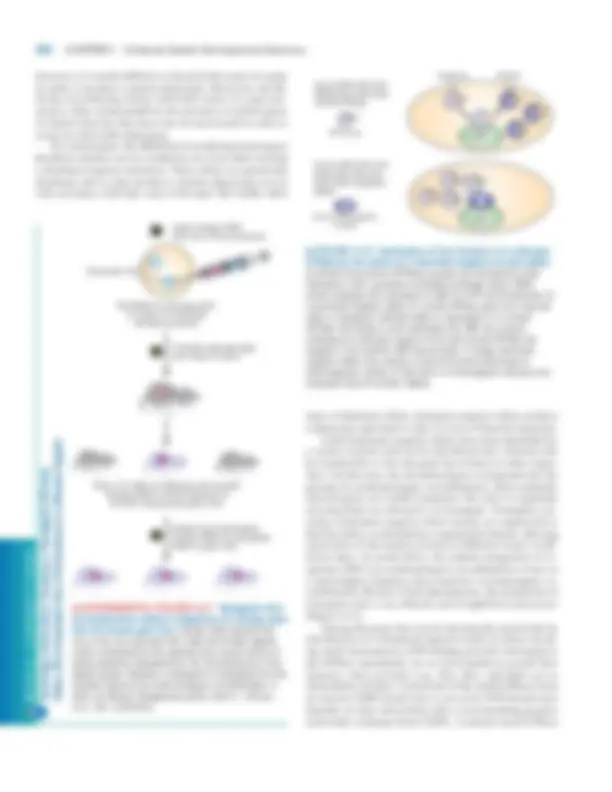
� EXPERIMENTAL FIGURE 9-6^ Haploid yeasts carrying temperature-sensitive lethal mutations are maintained at permissive temperature and analyzed at nonpermissive temperature. (a) Genetic screen for temperature-sensitive cell-division cycle ( cdc ) mutants in yeast. Yeasts that grow and form colonies at 23 �C (permissive temperature) but not at 36 �C (nonpermissive temperature) may carry a lethal mutation that blocks cell division. (b) Assay of temperature-sensitive colonies for blocks at specific stages in the cell cycle. Shown here are micrographs of wild-type yeast and two different temperature- sensitive mutants after incubation at the nonpermissive temperature for 6 h. Wild-type cells, which continue to grow, can be seen with all different sizes of buds, reflecting different stages of the cell cycle. In contrast, cells in the lower two micrographs exhibit a block at a specific stage in the cell cycle. The cdc mutants arrest at a point before emergence of a new bud and therefore appear as unbudded cells. The cdc7 mutants, which arrest just before separation of the mother cell and bud (emerging daughter cell), appear as cells with large buds. [Part (a) see L. H. Hartwell, 1967, J. Bacteriol. 93 :1662; part (b) from L. M. Hereford and L. H. Hartwell, 1974, J. Mol. Biol. 84 :445.]
will not exhibit the mutant phenotype because a wild-type allele of each gene will also be present. In this case, the mu- tations are said to complement each other. Complementation analysis of a set of mutants exhibit- ing the same phenotype can distinguish the individual genes in a set of functionally related genes, all of which must function to produce a given phenotypic trait. For example, the screen for cdc mutations in Saccharomyces described above yielded many recessive temperature-sensitive mu- tants that appeared arrested at the same cell-cycle stage. To determine how many genes were affected by these muta- tions, Hartwell and his colleagues performed complemen- tation tests on all of the pair-wise combinations of cdc mutants following the general protocol outlined in Figure 9-7. These tests identified more than 20 different CDC genes. The subsequent molecular characterization of the CDC genes and their encoded proteins, as described in de- tail in Chapter 21, has provided a framework for under- standing how cell division is regulated in organisms ranging from yeast to humans.
Double Mutants Are Useful in Assessing the Order in Which Proteins Function Based on careful analysis of mutant phenotypes associated with a particular cellular process, researchers often can de- duce the order in which a set of genes and their protein prod- ucts function. Two general types of processes are amenable to such analysis: (a) biosynthetic pathways in which a pre- cursor material is converted via one or more intermediates to a final product and (b) signaling pathways that regulate other processes and involve the flow of information rather than chemical intermediates.
Ordering of Biosynthetic Pathways A simple example of
the first type of process is the biosynthesis of a metabolite such as the amino acid tryptophan in bacteria. In this case, each of the enzymes required for synthesis of tryptophan cat- alyzes the conversion of one of the intermediates in the path- way to the next. In E. coli, the genes encoding these enzymes lie adjacent to one another in the genome, constituting the
358 CHAPTER 9 •^ Molecular Genetic Techniques and Genomics
cdcX/cdcY (type a /α)
cdcX
23 °C 23 °C
cdcY
Mutant (type a )
Mutant (type α) cdcX cdcZ
Mutant (type a )
Mutant (type α)
Plate and incubate at permissive temperature
Replica-plate and incubate at nonpermissive temperature
36 °C 36 °C
cdcX/cdcZ (type a /α)
Growth indicates that mutationscdcX andcdcY are in different genes
Mate haploids of opposite mating types and carrying different recessive temperature- sensitivecdc mutations
Test resulting diploids for a temperature- sensitivecdc phenotype
INTERPRETATION:
cdcX/ cdcY
cdcX/ PHENOTYPE: cdcZ
Wild type Mutant
Growth No growth
X Y
Absence of growth indicates that mutations cdcX andcdcZ are in the same gene
Respective wild-type alleles Both alleles nonfunctional provide normal function
X Z
� EXPERIMENTAL FIGURE 9-
Complementation analysis determines whether recessive mutations are in the same or different genes. Complementation tests in yeast are performed by mating haploid a and � cells carrying different recessive mutations to produce diploid cells. In the analysis of cdc mutations, pairs of different haploid temperature-sensitive cdc strains were systematically mated and the resulting diploids tested for growth at the permissive and nonpermissive temperatures. In this hypothetical example, the cdcX and cdcY mutants complement each other and thus have mutations in different genes, whereas the cdcX and cdcZ mutants have mutations in the same gene.
alleles would be normal, whereas strains carrying only one or the other mutant allele would have a mutant phenotype (Figure 9-9a). The observation of genetic suppression in yeast strains carrying a mutant actin allele ( act1-1 ) and a second mu- tation ( sac6 ) in another gene provided early evidence for a direct interaction in vivo between the proteins encoded by the two genes. Later biochemical studies showed that these two proteins—Act1 and Sac6—do indeed interact in the construction of functional actin structures within the cell.
Synthetic Lethal Mutations Another phenomenon, called
synthetic lethality, produces a phenotypic effect opposite to that of suppression. In this case, the deleterious effect of one mutation is greatly exacerbated (rather than suppressed) by a second mutation in the same or a related gene. One situa- tion in which such synthetic lethal mutations can occur is illustrated in Figure 9-9b. In this example, a heterodimeric protein is partially, but not completely, inactivated by muta- tions in either one of the nonidentical subunits. However, in double mutants carrying specific mutations in the genes encoding both subunits, little interaction between subunits occurs, resulting in severe phenotypic effects. Synthetic lethal mutations also can reveal nonessential genes whose encoded proteins function in redundant path- ways for producing an essential cell component. As depicted in Figure 9-9c, if either pathway alone is inactivated by a mu- tation, the other pathway will be able to supply the needed product. However, if both pathways are inactivated at the same time, the essential product cannot be synthesized, and the double mutants will be nonviable.
KEY CONCEPTS OF SECTION 9.
Genetic Analysis of Mutations to Identify and Study
Genes
■ Diploid organisms carry two copies (alleles) of each gene, whereas haploid organisms carry only one copy. ■ Recessive mutations lead to a loss of function, which is masked if a normal allele of the gene is present. For the mutant phenotype to occur, both alleles must carry the mutation. ■ Dominant mutations lead to a mutant phenotype in the presence of a normal allele of the gene. The phenotypes associated with dominant mutations often represent a gain of function but in the case of some genes result from a loss of function. ■ In meiosis, a diploid cell undergoes one DNA replica- tion and two cell divisions, yielding four haploid cells in which maternal and paternal alleles are randomly assorted (see Figure 9-3). ■ Dominant and recessive mutations exhibit characteristic segregation patterns in genetic crosses (see Figure 9-4). ■ In haploid yeast, temperature-sensitive mutations are particularly useful for identifying and studying genes es- sential to survival. ■ The number of functionally related genes involved in a process can be defined by complementation analysis (see Figure 9-7). ■ The order in which genes function in either a biosyn- thetic or a signaling pathway can be deduced from the phe- notype of double mutants defective in two steps in the af- fected process.
360 CHAPTER 9 •^ Molecular Genetic Techniques and Genomics
Genotype Phenotype
INTERPRETATION
INTERPRETATION
INTERPRETATION
Wild type Mutant Mutant Suppressed mutant
AB aB Ab ab
(a) Suppression
Wild type (^) Partial defect
Partial defect
Severe defect
AB aB Ab ab
(b) Synthetic lethality 1
Wild type Wild type Wild type Mutant
AB aB Ab ab
(c) Synthetic lethality 2
Precursor A b
Precursor a b
Precursor A B Product
Precursor a B
Genotype Phenotype
Genotype Phenotype
A B
A B
▲ EXPERIMENTAL FIGURE 9-9 Mutations that result in genetic suppression or synthetic lethality reveal interacting or redundant proteins. (a) Observation that double mutants with two defective proteins (A and B) have a wild-type phenotype but that single mutants give a mutant phenotype indicates that the function of each protein depends on interaction with the other. (b) Observation that double mutants have a more severe phenotypic defect than single mutants also is evidence that two proteins (e.g., subunits of a heterodimer) must interact to function normally. (c) Observation that a double mutant is nonviable but that the corresponding single mutants have the wild-type phenotype indicates that two proteins function in redundant pathways to produce an essential product.
■ Functionally significant interactions between proteins can be deduced from the phenotypic effects of allele-specific suppressor mutations or synthetic lethal mutations.
DNA Cloning by Recombinant
DNA Methods
Detailed studies of the structure and function of a gene at the molecular level require large quantities of the individual gene in pure form. A variety of techniques, often referred to as re- combinant DNA technology, are used in DNA cloning, which permits researchers to prepare large numbers of identical DNA molecules. Recombinant DNA is simply any DNA mol- ecule composed of sequences derived from different sources. The key to cloning a DNA fragment of interest is to link it to a vector DNA molecule, which can replicate within a host cell. After a single recombinant DNA molecule, com- posed of a vector plus an inserted DNA fragment, is intro- duced into a host cell, the inserted DNA is replicated along with the vector, generating a large number of identical DNA molecules. The basic scheme can be summarized as follows:
Vector � DNA fragment ↓ Recombinant DNA ↓ Replication of recombinant DNA within host cells ↓ Isolation, sequencing, and manipulation of purified DNA fragment
Although investigators have devised numerous experimen- tal variations, this flow diagram indicates the essential steps in DNA cloning. In this section, we cover the steps in this basic scheme, focusing on the two types of vectors most com- monly used in E. coli host cells: plasmid vectors, which repli- cate along with their host cells, and bacteriophage � vectors, which replicate as lytic viruses, killing the host cell and packaging their DNA into virions. We discuss the charac- terization and various uses of cloned DNA fragments in sub- sequent sections.
Restriction Enzymes and DNA Ligases Allow
Insertion of DNA Fragments into Cloning Vectors
A major objective of DNA cloning is to obtain discrete, small regions of an organism’s DNA that constitute specific genes. In addition, only relatively small DNA molecules can be cloned in any of the available vectors. For these reasons, the very long DNA molecules that compose an organism’s genome must be cleaved into fragments that can be inserted into the vector DNA. Two types of enzymes— restriction enzymes and DNA ligases —facilitate production of such re- combinant DNA molecules.
9.
Cutting DNA Molecules into Small Fragments Restriction
enzymes are endonucleases produced by bacteria that typi- cally recognize specific 4- to 8-bp sequences, called restric- tion sites, and then cleave both DNA strands at this site. Restriction sites commonly are short palindromic sequences; that is, the restriction-site sequence is the same on each DNA strand when read in the 5� → 3 � direction (Figure 9-10). For each restriction enzyme, bacteria also produce a modification enzyme, which protects a bacterium’s own DNA from cleavage by modifying it at or near each poten- tial cleavage site. The modification enzyme adds a methyl group to one or two bases, usually within the restriction site. When a methyl group is present there, the restriction endonuclease is prevented from cutting the DNA. Together with the restriction endonuclease, the methylating enzyme forms a restriction-modification system that protects the host DNA while it destroys incoming foreign DNA (e.g., bacteriophage DNA or DNA taken up during transforma- tion) by cleaving it at all the restriction sites in the DNA. Many restriction enzymes make staggered cuts in the two DNA strands at their recognition site, generating fragments that have a single-stranded “tail” at both ends (see Figure 9-10). The tails on the fragments generated at a given re- striction site are complementary to those on all other frag- ments generated by the same restriction enzyme. At room temperature, these single-stranded regions, often called “sticky ends,” can transiently base-pair with those on other DNA fragments generated with the same restriction enzyme. A few restriction enzymes, such as Alu I and Sma I, cleave both DNA strands at the same point within the restriction site, generating fragments with “blunt” (flush) ends in which all the nucleotides at the fragment ends are base-paired to nucleotides in the complementary strand. The DNA isolated from an individual organism has a spe- cific sequence, which purely by chance will contain a specific
9.2 •^ DNA Cloning by Recombinant DNA Methods 361
Cleavage
5 � 3 �
3 � 5 �
G C
A T
A T
T A
T A
C G
Sticky ends
5 � 3 �
3 � C G 5 �
G A A T T C T T A A
EcoRI
EcoRI
▲ FIGURE 9-10 Cleavage of DNA by the restriction enzyme Eco RI. This restriction enzyme from E. coli makes staggered cuts at the specific 6-bp inverted repeat (palindromic) sequence shown, yielding fragments with single-stranded, complementary “sticky” ends. Many other restriction enzymes also produce fragments with sticky ends.
blunt DNA ends. However, blunt-end ligation is inherently inefficient and requires a higher concentration of both DNA and DNA ligase than for ligation of sticky ends.
E. coli Plasmid Vectors Are Suitable for Cloning
Isolated DNA Fragments
Plasmids are circular, double-stranded DNA (dsDNA) mol- ecules that are separate from a cell’s chromosomal DNA. These extrachromosomal DNAs, which occur naturally in bacteria and in lower eukaryotic cells (e.g., yeast), exist in a parasitic or symbiotic relationship with their host cell. Like the host-cell chromosomal DNA, plasmid DNA is duplicated before every cell division. During cell division, copies of the plasmid DNA segregate to each daughter cell, assuring con-
tinued propagation of the plasmid through successive gener- ations of the host cell. The plasmids most commonly used in recombinant DNA technology are those that replicate in E. coli. Investigators have engineered these plasmids to optimize their use as vec- tors in DNA cloning. For instance, removal of unneeded por- tions from naturally occurring E. coli plasmids yields plasmid vectors, ≈1.2–3 kb in circumferential length, that contain three regions essential for DNA cloning: a replica- tion origin; a marker that permits selection, usually a drug- resistance gene; and a region in which exogenous DNA fragments can be inserted (Figure 9-12). Host-cell enzymes replicate a plasmid beginning at the replication origin (ORI), a specific DNA sequence of 50–100 base pairs. Once DNA replication is initiated at the ORI, it continues around the cir- cular plasmid regardless of its nucleotide sequence. Thus any DNA sequence inserted into such a plasmid is replicated along with the rest of the plasmid DNA. Figure 9-13 outlines the general procedure for cloning a DNA fragment using E. coli plasmid vectors. When E. coli cells are mixed with recombinant vector DNA under certain conditions, a small fraction of the cells will take up the plas- mid DNA, a process known as transformation. Typically, 1 cell in about 10,000 incorporates a single plasmid DNA molecule and thus becomes transformed. After plasmid vec- tors are incubated with E. coli, those cells that take up the plasmid can be easily selected from the much larger number of cells. For instance, if the plasmid carries a gene that con- fers resistance to the antibiotic ampicillin, transformed cells
9.2 •^ DNA Cloning by Recombinant DNA Methods 363
(a � )
(a)
(b)
(c)
5 �
33 �
Complementary ends base-pair
Unpaired genomic fragments (b) and (c)
3 �
3 �
5 �
HO
3 �
P
5 �
5 �
2 ATP
T4 DNA ligase
2 AMP + 2 PP (^) i
Vector DNA
Genomic DNA fragments
OH
P A A T T OH
P A G C T HO
T T A A P
(a � ) 5 �
(a)
5 �
OH
P HO
P C G
3 � (^) T T A A
A A T T 3 �
(a � ) 5 �
(a)
3 � (^) T T A A 5 �
A A T T 3 �
▲ FIGURE 9-11 Ligation of restriction fragments with complementary sticky ends. In this example, vector DNA cut with Eco RI is mixed with a sample containing restriction fragments produced by cleaving genomic DNA with several different restriction enzymes. The short base sequences composing the sticky ends of each fragment type are shown. The sticky end on the cut vector DNA (a�) base-pairs only with the complementary sticky ends on the Eco RI fragment (a) in the genomic sample. The adjacent 3�-hydroxyl and 5�-phosphate groups (red) on the base-paired fragments then are covalently joined (ligated) by T4 DNA ligase.
Plasmid cloning vector
Region into which exogenous DNA BamHI can be inserted
EcoRI
HindIII
KpnI
PstI
SacI
SalI
SmaI
SphI
XbaI
Polylinker
amp
r
ORI
▲ FIGURE 9-12 Basic components of a plasmid cloning vector that can replicate within an E. coli cell. Plasmid vectors contain a selectable gene such as amp r^ , which encodes the enzyme �-lactamase and confers resistance to ampicillin. Exogenous DNA can be inserted into the bracketed region without disturbing the ability of the plasmid to replicate or express the amp r^ gene. Plasmid vectors also contain a replication origin (ORI) sequence where DNA replication is initiated by host- cell enzymes. Inclusion of a synthetic polylinker containing the recognition sequences for several different restriction enzymes increases the versatility of a plasmid vector. The vector is designed so that each site in the polylinker is unique on the plasmid.
can be selected by growing them in an ampicillin-containing medium. DNA fragments from a few base pairs up to ≈20 kb com- monly are inserted into plasmid vectors. If special precautions are taken to avoid manipulations that might mechanically break DNA, even longer DNA fragments can be inserted into a plasmid vector. When a recombinant plasmid with an inserted DNA fragment transforms an E. coli cell, all the antibiotic-resistant progeny cells that arise from the initial transformed cell will contain plasmids with the same inserted DNA. The inserted DNA is replicated along with the rest of the plasmid DNA and segregates to daughter cells as the colony grows. In this way, the initial fragment of DNA is replicated in the colony of cells into a large number of iden- tical copies. Since all the cells in a colony arise from a single transformed parental cell, they constitute a clone of cells, and the initial fragment of DNA inserted into the parental plasmid is referred to as cloned DNA or a DNA clone. The versatility of an E. coli plasmid vector is increased by incorporating into it a polylinker, a synthetically generated sequence containing one copy of several different restriction sites that are not present elsewhere in the plasmid sequence (see Figure 9-12). When such a vector is treated with a re- striction enzyme that recognizes a restriction site in the polylinker, the vector is cut only once within the polylinker. Subsequently any DNA fragment of appropriate length pro- duced with the same restriction enzyme can be inserted into the cut plasmid with DNA ligase. Plasmids containing a polylinker permit a researcher to clone DNA fragments gen- erated with different restriction enzymes using the same plas- mid vector, which simplifies experimental procedures.
Bacteriophage � Vectors Permit Efficient Construction of Large DNA Libraries Vectors constructed from bacteriophage � are about a thou- sand times more efficient than plasmid vectors in cloning large numbers of DNA fragments. For this reason, phage � vectors have been widely used to generate DNA libraries, comprehensive collections of DNA fragments representing the genome or expressed mRNAs of an organism. Two fac- tors account for the greater efficiency of phage � as a cloning vector: infection of E. coli host cells by � virions occurs at about a thousandfold greater frequency than transformation by plasmids, and many more � clones than transformed colonies can be grown and detected on a single culture plate. When a � virion infects an E. coli cell, it can undergo a cycle of lytic growth during which the phage DNA is repli- cated and assembled into more than 100 complete progeny phage, which are released when the infected cell lyses (see Fig- ure 4-40). If a sample of � phage is placed on a lawn of E. coli growing on a petri plate, each virion will infect a single cell. The ensuing rounds of phage growth will give rise to a visi- ble cleared region, called a plaque, where the cells have been lysed and phage particles released (see Figure 4-39).
364 CHAPTER 9 •^ Molecular Genetic Techniques and Genomics
Enzymatically insert DNA into plasmid vector
E. coli chromosome
Transformed cell survives
DNA fragment to be cloned
Cells that do not take up plasmid die on ampicillin plates Plasmid replication
Cell multiplication
Colony of cells, each containing copies of the same recombinant plasmid
MixE. coli with plasmids in presence of CaCl 2 ; heat pulse Culture on nutrient agar plates containing ampicillin
Plasmid vector
Recombinant plasmid
am p r
am pr
▲ EXPERIMENTAL FIGURE 9-13 DNA cloning in a plasmid vector permits amplification of a DNA fragment. A fragment of DNA to be cloned is first inserted into a plasmid vector containing an ampicillin-resistance gene ( amp r^ ), such as that shown in Figure 9-12. Only the few cells transformed by incorporation of a plasmid molecule will survive on ampicillin-containing medium. In transformed cells, the plasmid DNA replicates and segregates into daughter cells, resulting in formation of an ampicillin- resistant colony.
M E D I A
C O N N E C T I O N S
Technique Animation: Plasmid Cloning
mRNA 5� A A A ....An 3 � 3 � poly(A) tail Hybridize mRNA with oligo-dT primer
Transcribe RNA into cDNA
Single-stranded cDNA
Double-stranded cDNA
A A A A 3� T T T T 5�
A A A A T T T T 5�
Remove RNA with alkali Add poly(dG) tail
T T T T 5� Hybridize with oligo-dC primer
T T T T 5� Synthesize complementary strand
A A A A 3� T T T T 5�
5 � C C C C 3 � G G G G
5 � C C C C 3 � G G G G
3 � G G G G
Ligate cDNA to restriction site linkers
C C C C G G G G
C C C C G G G G
T T T T
G A A T T C A A A A
A A T T C
C T T A A G
Cleave withEcoRI
G T T T T C T T A A
A A A A G
G A A T T C C T T A A G
Ligate to λ arms Sticky end
G A A T T C C T T A A G
EcoRI linker
T T T T 5�
Oligo-dT primer
C T T A A
A A T T C
Package in vitro
InfectE. coli
G
G
1 2 3 4 5 6 7
8a
9
10
11
8b
Protect cDNA by methylation at EcoRI sites
A A A A 3� T T T T 5�
5 � C C C C 3 � G G G G
CH 3
CH 3
λ vector arms with sticky ends
Recombinant λ virions
Replaceable region
Bacteriophage λ DNA
Cut withEcoRI Remove replaceable region
Individual λ clones
cDNA contains an oligo-dC � oligo-dG double-stranded re- gion at one end and an oligo-dT�oligo-dA double-stranded region at the other end. Methylation of the cDNA protects it from subsequent restriction enzyme cleavage (step 6 ). To prepare double-stranded cDNAs for cloning, short double-stranded DNA molecules containing the recognition site for a particular restriction enzyme are ligated to both ends of the cDNAs using DNA ligase from bacteriophage T (Figure 9-15, step 7 ). As noted earlier, this ligase can join “blunt-ended” double-stranded DNA molecules lacking sticky ends. The resulting molecules are then treated with the restriction enzyme specific for the attached linker, generating cDNA molecules with sticky ends at each end (step 8a ). In a separate procedure, � DNA first is treated with the same restriction enzyme to produce fragments called � vector arms, which have sticky ends and together contain all the genes necessary for lytic growth (step 8b ). The � arms and the collection of cDNAs, all containing complementary sticky ends, then are mixed and joined co- valently by DNA ligase (Figure 9-15, step 9 ). Each of the resulting recombinant DNA molecules contains a cDNA lo- cated between the two arms of the � vector DNA. Virions containing the ligated recombinant DNAs then are assem- bled in vitro as described above (step 10 ). Only DNA mol- ecules of the correct size can be packaged to produce fully infectious recombinant � phage. Finally, the recombinant � phages are plated on a lawn of E. coli cells to generate a large number of individual plaques (step 11 ).
366 CHAPTER 9 •^ Molecular Genetic Techniques and Genomics
▲ EXPERIMENTAL FIGURE 9-15 A cDNA library can be constructed using a bacteriophage � vector. A mixture of mRNAs is the starting point for preparing recombinant � virions each containing a cDNA. To maximize the size of the exogenous DNA that can be inserted into the � genome, the nonessential regions of the � genome (diagonal lines in Figure 9-14) usually are deleted. Plating of the recombinant phage on a lawn of E. coli generates a set of cDNA clones representing all the cellular mRNAs. See the text for a step- by-step discussion.
Since each plaque arises from a single recombinant phage, all the progeny � phages that develop are genetically identical and constitute a clone carrying a cDNA derived from a single mRNA; collectively they constitute a � cDNA library. One feature of cDNA libraries arises because differ- ent genes are transcribed at very different rates. As a result, cDNA clones corresponding to rapidly transcribed genes will be represented many times in a cDNA library, whereas cDNAs corresponding to slowly transcribed genes will be ex- tremely rare or not present at all. This property is advanta- geous if an investigator is interested in a gene that is transcribed at a high rate in a particular cell type. In this case, a cDNA library prepared from mRNAs expressed in that cell type will be enriched in the cDNA of interest, facil- itating screening of the library for � clones carrying that cDNA. However, to have a reasonable chance of including clones corresponding to slowly transcribed genes, mam- malian cDNA libraries must contain 10 6 –10 7 individual re- combinant � phage clones.
DNA Libraries Can Be Screened by Hybridization
to an Oligonucleotide Probe
Both genomic and cDNA libraries of various organisms contain hundreds of thousands to upwards of a million in- dividual clones in the case of higher eukaryotes. Two gen- eral approaches are available for screening libraries to identify clones carrying a gene or other DNA region of in- terest: (1) detection with oligonucleotide probes that bind to the clone of interest and (2) detection based on expres- sion of the encoded protein. Here we describe the first method; an example of the second method is presented in the next section. The basis for screening with oligonucleotide probes is hy- bridization, the ability of complementary single-stranded DNA or RNA molecules to associate (hybridize) specifically with each other via base pairing. As discussed in Chapter 4, double-stranded (duplex) DNA can be denatured (melted) into single strands by heating in a dilute salt solution. If the temperature then is lowered and the ion concentration raised, complementary single strands will reassociate (hy- bridize) into duplexes. In a mixture of nucleic acids, only complementary single strands (or strands containing com- plementary regions) will reassociate; moreover, the extent of their reassociation is virtually unaffected by the presence of noncomplementary strands. In the membrane-hybridization assay outlined in Figure 9-16, a single-stranded nucleic acid probe is used to detect those DNA fragments in a mixture that are complementary to the probe. The DNA sample first is denatured and the sin- gle strands attached to a solid support, commonly a nitro- cellulose filter or treated nylon membrane. The membrane is then incubated in a solution containing a radioactively la- beled probe. Under hybridization conditions (near neutral pH, 40–65 �C, 0.3–0.6 M NaCl), this labeled probe hy- bridizes to any complementary nucleic acid strands bound to
the membrane. Any excess probe that does not hybridize is washed away, and the labeled hybrids are detected by auto- radiography of the filter. Application of this procedure for screening a � cDNA li- brary is depicted in Figure 9-17. In this case, a replica of the petri dish containing a large number of individual � clones initially is reproduced on the surface of a nitrocellulose mem- brane. The membrane is then assayed using a radiolabeled probe specific for the recombinant DNA containing the frag- ment of interest. Membrane hybridization with radiolabeled oligonucleotides is most commonly used to screen � cDNA libraries. Once a cDNA clone encoding a particular protein is obtained, the full-length cDNA can be radiolabeled and used to probe a genomic library for clones containing frag- ments of the corresponding gene.
9.2 •^ DNA Cloning by Recombinant DNA Methods 367
Double- stranded DNA
Melt and place DNA on filter
Perform autoradiography
Incubate with labeled DNA ( )
Hybridized complementary DNAs
Wash away labeled DNA that does not hybridize to DNA bound to filter
Filter
Bound single- stranded DNA
▲ EXPERIMENTAL FIGURE 9-16 Membrane-hybridization assay detects nucleic acids complementary to an oligonucleotide probe. This assay can be used to detect both DNA and RNA, and the radiolabeled complementary probe can be either DNA or RNA.
cause a specific 20-nucleotide sequence occurs once in every 4 20 (≈ 10 12 ) nucleotides. Since all genomes are much smaller (≈ 3 � 10 9 nucleotides for humans), a specific 20-nucleotide sequence in a genome usually occurs only once. Oligonu- cleotides of this length with a specific sequence can be syn- thesized chemically and then radiolabeled by using polynucleotide kinase to transfer a 32 P-labeled phosphate group from ATP to the 5� end of each oligonucleotide. How might an investigator design an oligonucleotide probe to identify a cDNA clone encoding a particular pro- tein? If all or a portion of the amino acid sequence of the pro- tein is known, then a DNA probe corresponding to a small region of the gene can be designed based on the genetic code. However, because the genetic code is degenerate (i.e., many amino acids are encoded by more than one codon), a probe based on an amino acid sequence must include all the possi- ble oligonucleotides that could theoretically encode that pep- tide sequence. Within this mixture of oligonucleotides will be one that hybridizes perfectly to the clone of interest. In recent years, this approach has been simplified by the availability of the complete genomic sequences for humans and some important model organisms such as the mouse, Drosophila, and the roundworm Caenorhabditis elegans. Using an appropriate computer program, a researcher can search the genomic sequence database for the coding se- quence that corresponds to a specific portion of the amino acid sequence of the protein under study. If a match is found, then a single, unique DNA probe based on this known ge- nomic sequence will hybridize perfectly with the clone en- coding the protein under study. Chemical synthesis of single-stranded DNA probes of de- fined sequence can be accomplished by the series of reactions shown in Figure 9-18. With automated instruments now available, researchers can program the synthesis of oligonu- cleotides of specific sequence up to about 100 nucleotides long. Alternatively, these probes can be prepared by the poly- merase chain reaction (PCR), a widely used technique for amplifying specific DNA sequences that is described later.
Yeast Genomic Libraries Can Be Constructed with Shuttle Vectors and Screened by Functional Complementation In some cases a DNA library can be screened for the ability to express a functional protein that complements a recessive mu- tation. Such a screening strategy would be an efficient way to isolate a cloned gene that corresponds to an interesting re- cessive mutation identified in an experimental organism. To illustrate this method, referred to as functional complementa- tion, we describe how yeast genes cloned in special E. coli
9.2 •^ DNA Cloning by Recombinant DNA Methods 369
ORI
amp r
CEN
ARS
URA
Polylinker
Shuttle vector
(a)
(b)
Cut withBamHI
Yeast genomic DNA Shuttle vector Partially digest withSau3A
Ligate
TransformE. coli Screen for ampicillin resistance
Assay yeast genomic library by functional complementation
Isolate and pool recombinant plasmids from 10^5 transformed E. coli colonies
� EXPERIMENTAL FIGURE 9-19^ Yeast genomic library can be constructed in a plasmid shuttle vector that can replicate in yeast and E. coli****. (a) Components of a typical plasmid shuttle vector for cloning Saccharomyces genes. The presence of a yeast origin of DNA replication (ARS) and a yeast centromere (CEN) allows, stable replication and segregation in yeast. Also included is a yeast selectable marker such as URA3 , which allows a ura3� mutant to grow on medium lacking uracil. Finally, the vector contains sequences for replication and selection in E. coli (ORI and ampr ) and a polylinker for easy insertion of yeast DNA fragments. (b) Typical protocol for constructing a yeast genomic library. Partial digestion of total yeast genomic DNA with Sau 3A is adjusted to generate fragments with an average size of about 10 kb. The vector is prepared to accept the genomic fragments by digestion with Bam HI, which produces the same sticky ends as Sau 3A. Each transformed clone of E. coli that grows after selection for ampicillin resistance contains a single type of yeast DNA fragment.
plasmids can be introduced into mutant yeast cells to iden- tify the wild-type gene that is defective in the mutant strain. Libraries constructed for the purpose of screening among yeast gene sequences usually are constructed from genomic DNA rather than cDNA. Because Saccharomyces genes do not contain multiple introns, they are sufficiently compact so that the entire sequence of a gene can be included in a ge- nomic DNA fragment inserted into a plasmid vector. To con- struct a plasmid genomic library that is to be screened by functional complementation in yeast cells, the plasmid vector must be capable of replication in both E. coli cells and yeast cells. This type of vector, capable of propagation in two dif- ferent hosts, is called a shuttle vector. The structure of a typ- ical yeast shuttle vector is shown in Figure 9-19a (see page 369). This vector contains the basic elements that permit cloning of DNA fragments in E. coli. In addition, the shuttle vector contains an autonomously replicating sequence (ARS), which functions as an origin for DNA replication in yeast; a yeast centromere (called CEN), which allows faithful segre- gation of the plasmid during yeast cell division; and a yeast gene encoding an enzyme for uracil synthesis ( URA3 ), which serves as a selectable marker in an appropriate yeast mutant. To increase the probability that all regions of the yeast genome are successfully cloned and represented in the plas- mid library, the genomic DNA usually is only partially di- gested to yield overlapping restriction fragments of ≈10 kb. These fragments are then ligated into the shuttle vector in
which the polylinker has been cleaved with a restriction en- zyme that produces sticky ends complementary to those on the yeast DNA fragments (Figure 9-19b). Because the 10-kb restriction fragments of yeast DNA are incorporated into the shuttle vectors randomly, at least 10 5 E. coli colonies, each containing a particular recombinant shuttle vector, are nec- essary to assure that each region of yeast DNA has a high probability of being represented in the library at least once. Figure 9-20 outlines how such a yeast genomic library can be screened to isolate the wild-type gene corresponding to one of the temperature-sensitive cdc mutations mentioned earlier in this chapter. The starting yeast strain is a double mutant that requires uracil for growth due to a ura mutation and is temperature-sensitive due to a cdc28 muta- tion identified by its phenotype (see Figure 9-6). Recombi- nant plasmids isolated from the yeast genomic library are mixed with yeast cells under conditions that promote trans- formation of the cells with foreign DNA. Since transformed yeast cells carry a plasmid-borne copy of the wild-type URA3 gene, they can be selected by their ability to grow in the absence of uracil. Typically, about 20 petri dishes, each containing about 500 yeast transformants, are sufficient to represent the entire yeast genome. This collection of yeast transformants can be maintained at 23 �C, a temperature permissive for growth of the cdc28 mutant. The entire collection on 20 plates is then transferred to replica plates, which are placed at 36 �C, a nonpermissive temperature for
370 CHAPTER 9 •^ Molecular Genetic Techniques and Genomics
Temperature-sensitive cdc-mutant yeast; ura3 −^ (requires uracil)
Library of yeast genomic DNA carryingURA3 selective marker
Transform yeast by treatment with LiOAC, PEG, and heat shock
23 °C
23 °C
36 °C
Only colonies carrying a wild-type CDC gene are able to grow
Plate and incubate at permissive temperature on medium lacking uracil
Replica-plate and incubate at nonpermissive temperature
Only colonies carrying a URA3 marker are able to grow
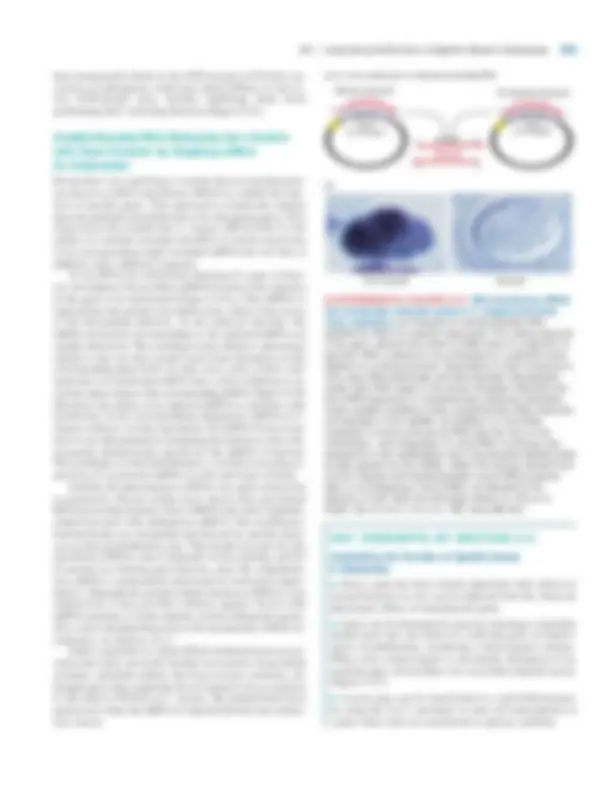
▲ EXPERIMENTAL FIGURE 9-20 Screening of a yeast genomic library by functional complementation can identify clones carrying the normal form of mutant yeast gene. In this example, a wild-type CDC gene is isolated by complementation of a cdc yeast mutant. The Saccharomyces strain used for screening the yeast library carries ura3 and a temperature-sensitive cdc mutation. This mutant strain is grown and maintained at a permissive temperature (23 �C). Pooled recombinant plasmids prepared as shown in Figure 9-
are incubated with the mutant yeast cells under conditions that promote transformation. The relatively few transformed yeast cells, which contain recombinant plasmid DNA, can grow in the absence of uracil at 23 �C. When transformed yeast colonies are replica-plated and placed at 36 �C (a nonpermissive temperature), only clones carrying a library plasmid that contains the wild-type copy of the CDC gene will survive. LiOAC lithium acetate; PEG polyethylene glycol.