Download Enhancing CPU Performance: Reducing CPI with Parallelism and Pipeline Extensions and more Slides Computer Science in PDF only on Docsity!
How to improve (decrease) CPI
- Recall: CPI = Ideal CPI + CPI contributed by
stalls
- Ideal CPI =1 for single issue machine even with
multiple execution units
- Ideal CPI will be less than 1 if we have several
execution units and we can issue (and
“commit”) multiple instructions in the same
cycle, i.e., we take advantage of Instruction
Level Parallelism (ILP)
Extending the simple pipeline
- Have multiple functional units for the EXE stage
- Increase the depth of the pipeline
- Required because of clock speed
- Increase the width of the pipeline
- Several instructions are fetched and decoded in the front-end of the pipe
- Several instructions are issued to the functional units in the back-end
- If m is the maximum number of instructions that can be issued in one cycle, we say that the processor is m- wide.
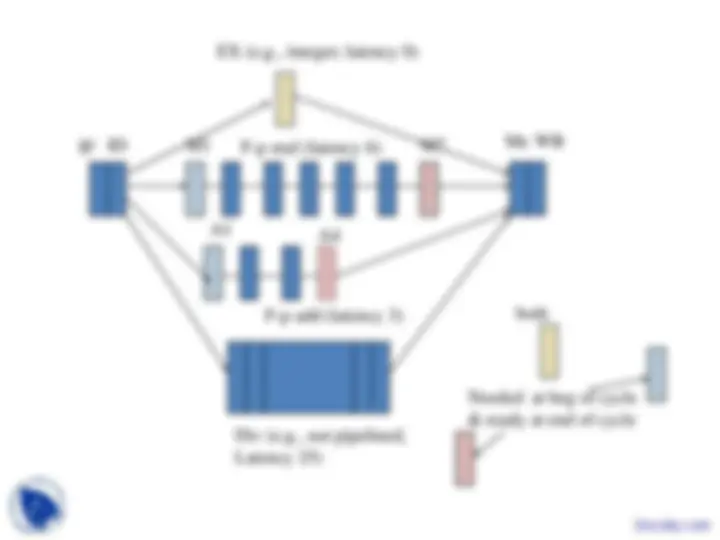
Extending simple pipeline to multiple
pipes
- Single issue: in ID stage direct to one of several EX stages
- Common WB stage
- EX of various pipelines might take more than one cycle
- Latency of an EX unit = Number of cycles before its result can be forwarded = Number of stages –
- Not all EX need be pipelined
- IF EX is pipelined
- A new instruction can be assigned to it every cycle (if no data dependency) or, maybe only after x cycles, with x depending on the function to be performed
IF ID
EX (e.g., integer; latency 0)
M1 M
A1 (^) A
Div (e.g., not pipelined, Latency 25)
Me
Needed at beg of cycle & ready at end of cycle
both
WB
F-p add (latency 3)
F-p mul (latency 6)
RAW:Example from the book (pg A-51)
F4 <- M IF ID EX Me WB F0 <- F4 * F6 IF ID st M1 M2 M3 M4 M5 M6 M7 Me WB F2 <- F0 + F8 IF st ID st st st st st st A1 A2 A3 A4 Me WB M <- F2 IF st st st st st st ID EX st st st Me WB
In blue data dependencies hazard In red structural hazard In green stall cycles Note both the data dependency and structural hazard for the 4 th^ instruction
Conflict in using the WB stage
- Several instructions might want to use the WB stage at the same time - E.g.,A Multd issued at time t and an addd issued at time t + 3
- Solution 1: reserve the WB stage at ID stage (scheme already used in CRAY-1 built in 1976) - Keep track of WB stage usage in shift register - Reserve the right slot. If busy, stall for a cycle and repeat - Shift every clock cycle
- Solution 2: Stall before entering either Me or WB
- Pro: easier detection than solution 1
- Con: need to be able to trickle the stalls “backwards”.
WAW Hazards
- Instruction i writes f-p register Fx at time t Instruction i + k writes f-p register Fx at time t - m
- But no instruction i + 1, i +2, i+k uses (reads) Fx (otherwise there would be a stall in in-order issue processors)
- Only requirement is that i + k ´s result be stored
- Note: this situation should be rare (useless instruction i )
- Solutions:
- Squash i : difficult to know where it is in the pipe
- At ID stage check that result register is not a result register in all subsequent stages of other units. If it is, stall appropriate number of cycles.
Out-of-order completion
- Instruction i finishes at time t
Instruction i + k finishes at time t - m
- No hazard etc. (see previous example on integer completing before multd )
- What happens if instruction i causes an exception
at a time
in [ t-m,t ] and instruction i + k writes in one of its
own source operands (i.e., is not restartable)?
- We’ll take care of that in OOO processors
Exploitation of Instruction Level
Parallelism (ILP)
- Will increase throughput and decrease CPU
execution time
- Will increase structural hazards
- Cannot issue simultaneously 2 instructions to the same functional unit
- Makes reduction in other stalls even more
important
- A stall costs more than the loss of a single instruction issue
- Will make the design more complex mostly in
OOO processors where: Docsity.com
Where can we optimize
exploitation of ILP?
- Speculative execution
- Branch prediction (we have seen that already)
- Bypassing Loads (memory reference speculation)
- Predication (we’ll see this technique with statically scheduled VLIW machines)
- Hardware (run-time) techniques
- Forwarding (RAW; we have seen that)
- Register renaming (WAW, WAR)
Name dependence
- Anti dependence
- Si: …<- R1+ R2; ….; Sj: R1 <- …
- At the instruction level, this is WAR hazard if instruction j finishes first
- Output dependence
- Si: R1 <- …; ….; Sj: R1 <- …
- At the instruction level, this is a WAW hazard if instruction j finishes first
- In both cases, not really a dependence but a
“naming” problem
- Register renaming (compiler by register allocation,
O j ∩ Ii ≠ ∅
O i ∩ Oj ≠ ∅
Static vs. dynamic scheduling
- Assumptions (for now):
- 1 instruction issue / cycle ( Same techniques will be used when we look at multiple issue)
- Several pipelines with a common IF and ID
- Ideal CPI still 1, but real CPI won’t be 1 but will be closer to 1 than before
- Static scheduling (optimized by compiler)
- When there is a stall (hazard) no further issue of instructions
- Of course, the stall has to be enforced by the hardware
- Dynamic scheduling (enforced by hardware)Docsity.com
Issue and Dispatch
- Split the ID stage into:
- Issue : decode instructions; check for structural hazards and maybe more hazards such as WAW depending on implementations. Stall if there are any. Instructions pass in this stage in order
- Dispatch : wait until no data hazards then read operands. At the next cycle a functional unit, i.e. EX of a pipe, can start executing
- Example revisited.
R1 = R2/ R3 (long latency; in execution) R2 = R1 + R5 (issue but no dispatch because
Implementations of dynamic
scheduling
- In order to compute correct results, need to
keep track of :
- execution unit (free or busy)
- register usage for read and write
- completion etc.
- Two major techniques
- Scoreboard (invented by Seymour Cray for the CDC 6600 in 1964)
- Tomasulo’s algorithm (used in the IBM 360/91 in