


Copyright Josep Torrellas 1999, 2001, 2002 1
Chapter 4
Multiprocessors and
Thread-Level Parallelism
Instructor: Josep Torrellas
CS433































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Material Type: Notes; Professor: Torrellas; Class: Computer System Organization; Subject: Computer Science; University: University of Illinois - Urbana-Champaign; Term: Fall 2008;
Typology: Study notes
1 / 39

This page cannot be seen from the preview
Don't miss anything!
Copyright Josep Torrellas 1999, 2001, 2002
Copyright Josep Torrellas 1999, 2001, 2002
complex
multicores
parallel processing
Copyright Josep Torrellas 1999, 2001, 2002
Multiple I streams, single D stream (MISD) : nocommercial machine
-^
Multiple I streams, multiple D streams (MIMD)– each processor fetches its own instructions and operates
on its own data
μ
processors
multiprogrammed
μ
processors
Copyright Josep Torrellas 1999, 2001, 2002
and complex
communication:1. Distributed shared memory (DSM) or scalable
shared memory
Copyright Josep Torrellas 1999, 2001, 2002
DSMs :•^
memories addressed as one shared address space: processorP1 writes address X, processor P2 reads address X
-^
Shared memory means that some address in 2 processorsrefers to same mem location; not that mem is centralized
-^
also called NUMA (Non Uniform Memory Access)
-^
processors communicate implicitly via loads and stores Multicomputers:•^
each processor has its own address space , disjoint to otherprocessors , cannot be addressed by other processors
Copyright Josep Torrellas 1999, 2001, 2002
processors are notified of the arrival of a msg
polling →
interrupt
standard message passing libraries: message passinginterface (MPI)
Copyright Josep Torrellas 1999, 2001, 2002
Shared memory communication (DSM)+ Compatibility w/well understood mechanisms in centralized
mps
communication patterns
better use of bandwidth when using small communications
of data
Copyright Josep Torrellas 1999, 2001, 2002
Amdahl’s law:fparallel
fparallel
Speedup = 2) Large latency of remote accesses (50-1,000 clock cycles)
(1- f
enh)
enh S
penh
( 1- f
parallel
fparallel^100
Example : 0.5 ns machine has a round
trip latency of 200 ns. 0.2% ofinstructions cause a cache miss (processor stall).
Base CPI without
misses is 0.5. Whats new CPI?
CPI = 0.5 + 0.2% * 200/0.5 = 1.
Copyright Josep Torrellas 1999, 2001, 2002
Caches are critical to modern high-speed processors
-^
Multiple copies of a block can easily get inconsistent–
processor writes. I/O writes,..
Cache
Cache
A = 5
A = 5
3
A = 7
Memory
A = 5
Copyright Josep Torrellas 1999, 2001, 2002
A distributed cache coherence scheme based on the notionof a snoop that watches all activity on a global bus, or isinformed about such activity by some global broadcastmechanism.
-^
Most commonly used method in commercialmultiprocessors
Copyright Josep Torrellas 1999, 2001, 2002
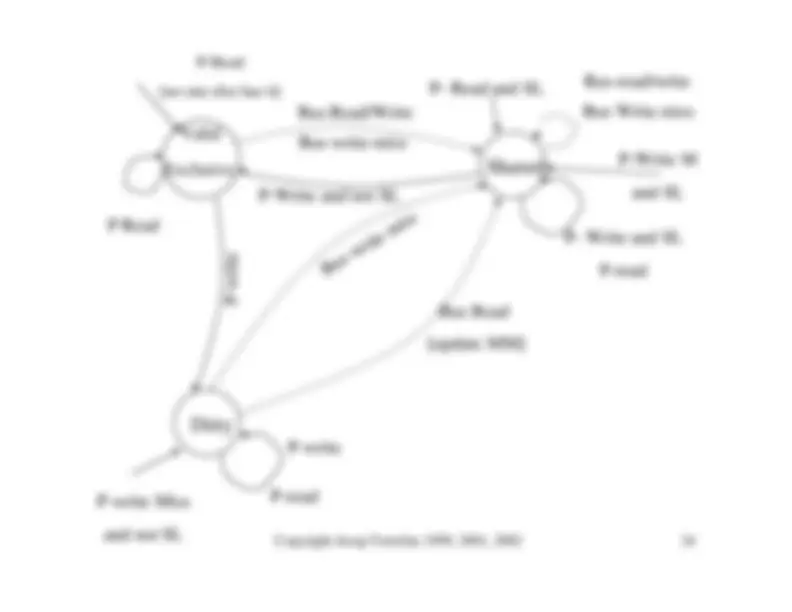
Dirty
Shared
Invalid
Bus Write MissBus invalidateP-read
Bus-readP- Read
P-read P-write
Bus Write Miss
Bus-read
P-write
P-write
P- Read
P-write
Copyright Josep Torrellas 1999, 2001, 2002
When a single cache has ownership of a block, processorwrites do not result in bus writes thus conservingbandwidth.
-^
Most bus-based multiprocessors nowadays use suchschemes.
-^
Many variants of ownership-based protocols exist:– Goodman’s write -once scheme– Berkley ownership scheme– Firefly update protocol– …
-^
We will discuss a few of these
Copyright Josep Torrellas 1999, 2001, 2002
Invalidation is bad when :–
single producer and many consumers of data.
-^
Update is bad when :–
multiple writes by one PE before data is read by another PE.– Junk data accumulates in large caches (e.g. process migration).
-^
Overall, invalidation schemes are more popular as the default