Download Multiprocessors and Thread-Level Parallelism: A Comprehensive Guide and more Cheat Sheet Law in PDF only on Docsity!
Chapter 6: Multiprocessors and
Thread-Level Parallelism
Parallel Architectures
MIMD
In order to take advantage of an MIMD
multiprocessor with n processors, we must have at
least n threads or processes to execute.
Major MIMD Styles
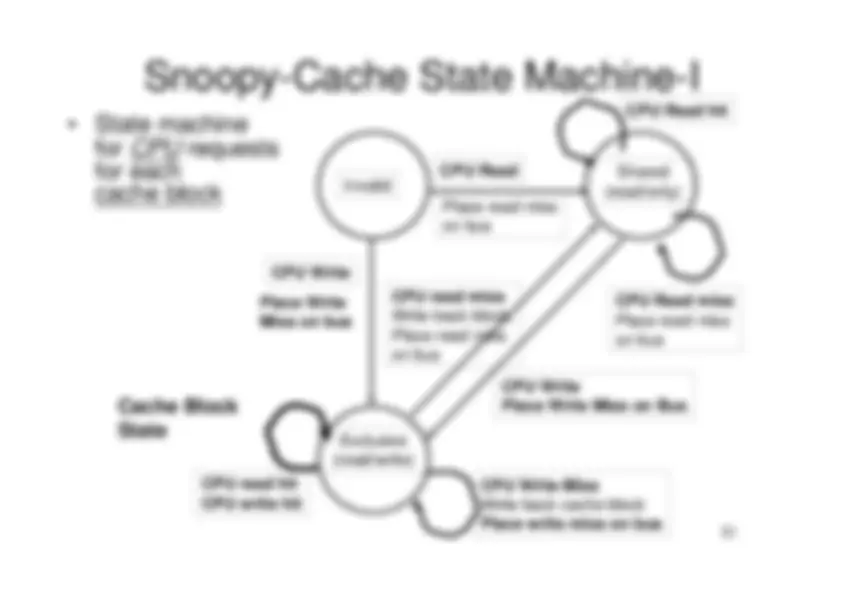
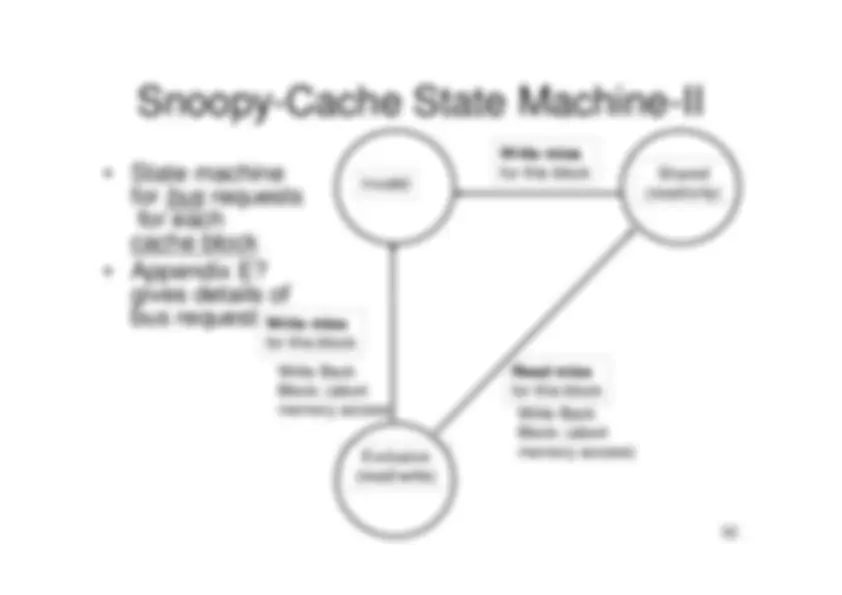
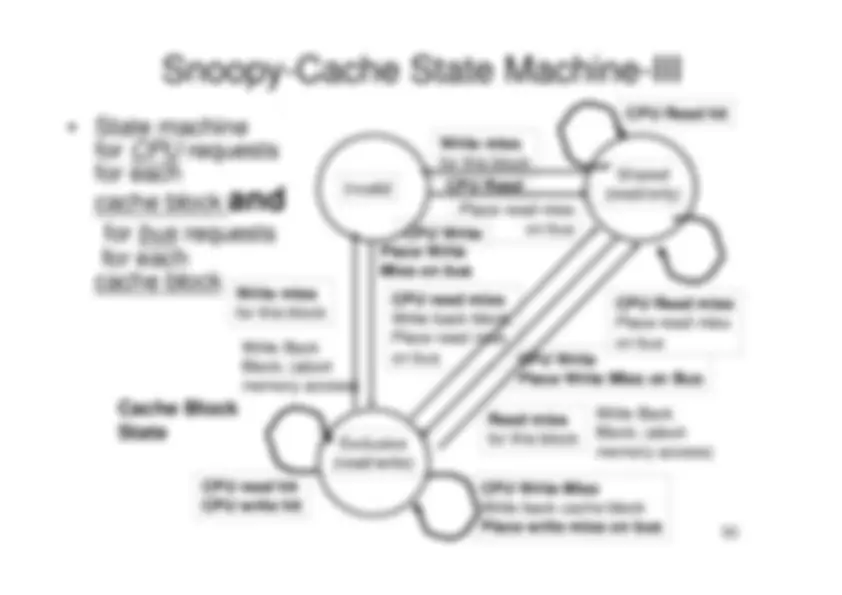
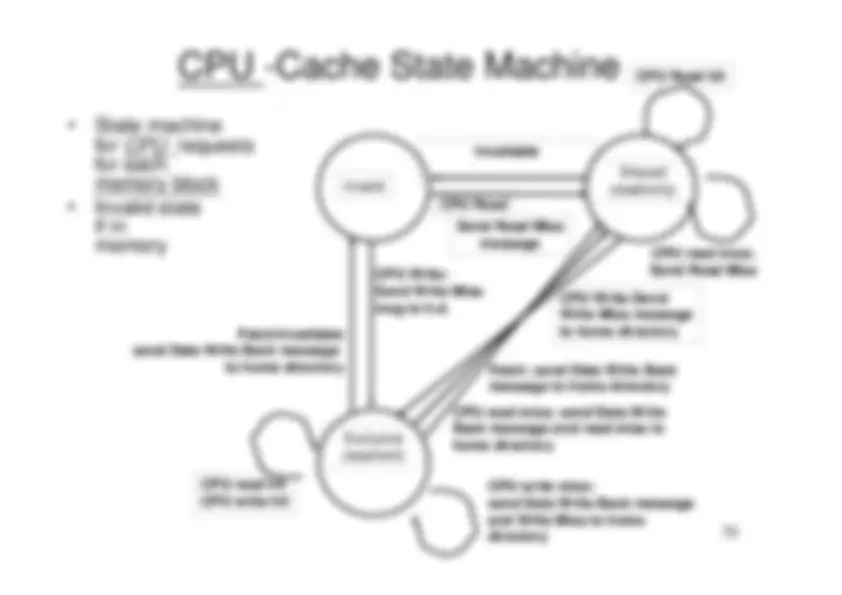
1. Centralized shared memory architectures
("Uniform Memory Access" or "Shared Memory
Processor")
- For multiprocessors with small processor count, it is possible to share a single centralized memory and to interconnect the processors and memory by a bus.
2. Decentralized memory (memory module with CPU)
- get more memory bandwidth, lower memory latency
- Drawback: Longer communication latency
- Drawback: Software model more complex
- Shared memory model
- Message passing model
Natural Extensions of Memory System
P 1 Switch Main memory Pn (Interleaved) (Interleaved) First-level $ P 1 $ Interconnection network $ Pn Mem (^) Mem P 1 $ Interconnection network $ Pn Shared Cache^ Mem^ Mem Centralized Memory Dance Hall, UMA Distributed Memory (NUMA) Scale
Decentralized Memory versions
1. Shared Memory with "Non Uniform Memory
Access" time (NUMA)
2. Message passing "multicomputer" with separate
address space per processor
- Can invoke software with Remote Procedue Call (RPC)
- Often via library, such as MPI: Message Passing Interface
- Also called "Synchronous communication" since communication causes synchronization between 2 processes
Parallel Framework
Layers:
- Programming Model: Multiprogramming : lots of jobs, no communication Shared address space: communicate via memory Message passing: send and receive messages Data Parallel: several agents operate on several data sets simultaneously and then exchange information globally and simultaneously (shared or message passing)
- Communication Abstraction: Shared address space: e.g., load, store, atomic swap Message passing: e.g., send, receive library calls Debate over this topic (ease of programming, scaling) => many hardware designs 1:1 programming model
Shared address space model
Message passing model
Message Passing Model
Whole computers (CPU, memory, I/O devices) communicate as explicit I/O operations
- Essentially NUMA but integrated at I/O devices vs. memory system Send specifies local buffer + receiving process on remote computer Receive specifies sending process on remote computer + local buffer to place data
- Usually send includes process tag and receive has rule on tag: match 1, match any
- Sync: when send completes, when buffer free, when request accepted, receive wait for send Send+receive => memory-memory copy, where each supplies local address, AND does pairwise sychronization!
Data parallel model
Data Parallel Model
Operations can be performed in parallel on each element of a large regular data structure, such as an array 1 Control Processor broadcast to many PEs When computers were large, could amortize the control portion of many replicated PEs Condition flag per PE so that can skip Data distributed in each memory Early 1980s VLSI => SIMD rebirth: 32 1-bit PEs + memory on a chip was the PE Data parallel programming languages lay out data to processor
Comparing models of parallelism
20
Advantages shared-memory
communication model
Compatibility with SMP hardware
Ease of programming when communication
patterns are complex or vary dynamically during
execution
Ability to develop apps using familiar SMP
model, attention only on performance critical
accesses
Lower communication overhead, better use of
BW for small items, due to implicit
communication and memory mapping to
implement protection in hardware, rather than
through I/O system
HW-controlled caching to reduce remote comm.
by caching of all data, both shared and private.