Download Multithreading and Out-of-Order Execution: A Deep Dive into Concurrent Processing and more Slides Computer Architecture and Organization in PDF only on Docsity!
Multithreading
Outline
- Multithreading
- Thread scheduling policies
- Grain multithreading
- Design choices
- Multi threading architecture
- Out-of-order superscalar processor
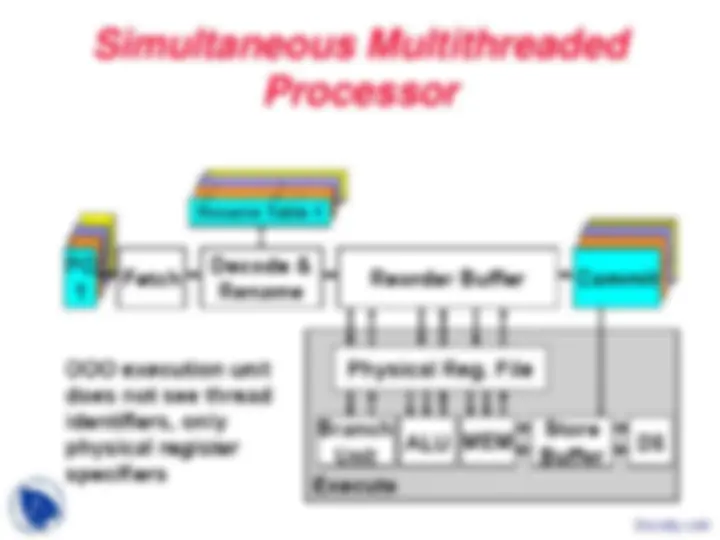
- Simultaneous multithreading
- From superscalar to SMT
- SMT design issues
Multithreading
- How can we guarantee no dependencies between instructions in a pipeline? - One way is to interleave execution of instructions from different program threads on same pipeline Interleave 4 threads, T1-T4, on non-bypassed 5-stage pipe
T1: LW r1, 0(r2) T2: ADD r7, r1, r T3: XORI r5, r4, # T4: SW 0(r7), r T1: LW r5, 12(r1)
CDC 6600 Peripheral Processors (Cray,
- First multithreaded hardware
- 10 “virtual” I/O processors
- fixed interleave on simple pipeline
- pipeline has 100ns cycle time
- each processor executes one
instruction every 1000ns
- accumulator-based instruction set to
reduce processor state
Multithreading Costs
- Appears to software (including OS) as multiple slower CPUs
- Each thread requires its own user state
- Also, needs own OS control state
- virtual memory page table base register
- exception handling registers
- Other costs?
Thread Scheduling Policies
- Fixed interleave (CDC 6600 PPUs, 1965)
- each of N threads executes one instruction every N cycles
- if thread not ready to go in its slot, insert pipeline bubble
- Software-controlled interleave (TI ASC PPUs, 1971)
- OS allocates S pipeline slots amongst N threads
- hardware performs fixed interleave over S slots, executing whichever thread is in that slot
- Hardware-controlled thread scheduling (HEP, 1982)
- hardware keeps track of which threads are ready to go
- picks next thread to execute based on hardware priority scheme
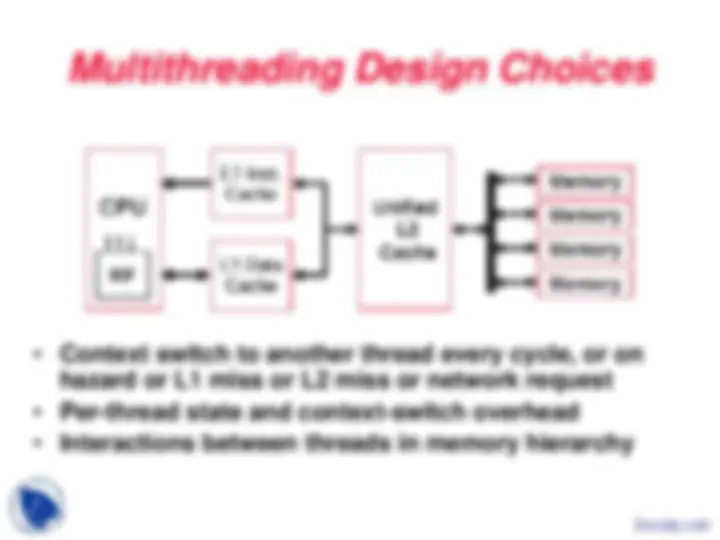
Multithreading Design Choices
- Context switch to another thread every cycle, or on hazard or L1 miss or L2 miss or network request
- Per-thread state and context-switch overhead
- Interactions between threads in memory hierarchy
Denelcor HEP
(Burton Smith, 1982)
- First commercial machine to use
hardware threading in main CPU
- 120 threads per processor
- 10 MHz clock rate
- Up to 8 processors
- precursor to Tera MTA (Multithreaded
Architecture)
MTA Instruction Format
- Three operations packed into 64-bit instruction word (short VLIW)
- One memory operation, one arithmetic operation, plus one arithmetic or branch operation
- Memory operations incur ~150 cycles of latency
- Explicit 3-bit “lookahead” field in instruction gives number of subsequent instructions (0-7) that are independent of this one - c.f. Instruction grouping in VLIW - allows fewer threads to fill machine pipeline - used for variable- sized branch delay slots
- Thread creation and termination instructions
MTA Multithreading
- Each processor supports 128 active hardware threads - 128 SSWs, 1024 target registers, 4096 general-purpose registers
- Every cycle, one instruction from one active thread is launched into pipeline
- Instruction pipeline is 21 cycles long
- At best, a single thread can issue one instruction every 21 cycles - Clock rate is 260MHz, effective single thread issue rate is 260/21 = 12.4MHz
Coarse-Grain Multithreading
- Tera MTA designed for supercomputing applications with large data sets and low locality - No data cache - Many parallel threads needed to hide large memory latency
- Other applications are more cache friendly
- Few pipeline bubbles when cache getting hits
- Just add a few threads to hide occasional cache miss latencies
- Swap threads on cache misses
MIT Alewife
• Modified SPARC chips
- register windows hold different thread
contexts
• Up to four threads per node
• Thread switch on local cache miss
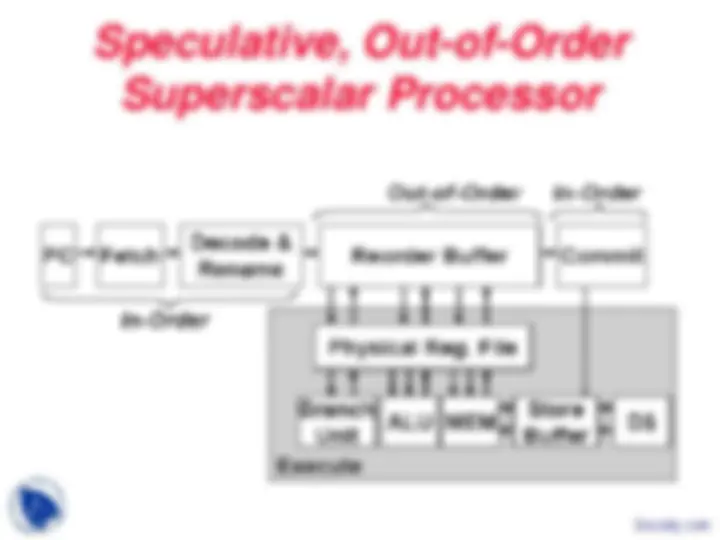
Speculative, Out-of-Order
Superscalar Processor
Out-Of-Order Execution
- Why Out-Of-Order Execution?
- In-order Processors Stalls
Pipeline may not be full because of the frequent stalls
Allow In the Out-Of-Order Processors
**- No dependency Move the Instruction for execution
- Means the Instructions that are Ready**