



CS 162 Computer Architecture
Lecture 10: Multithreading
Docsity.com


















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
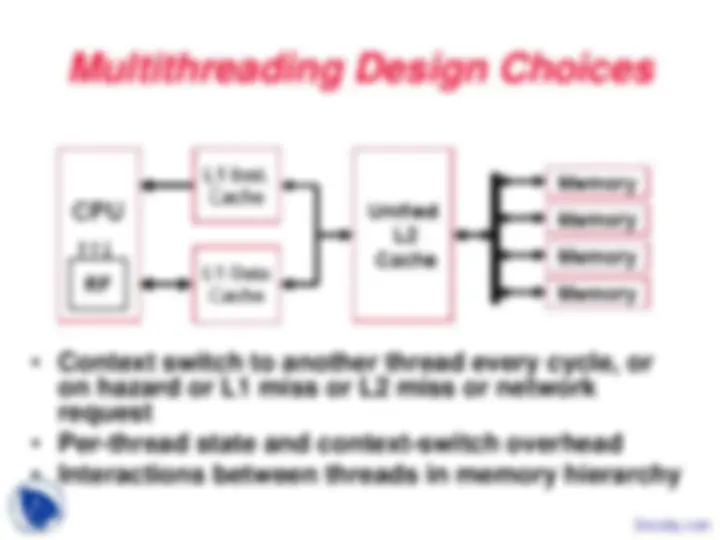
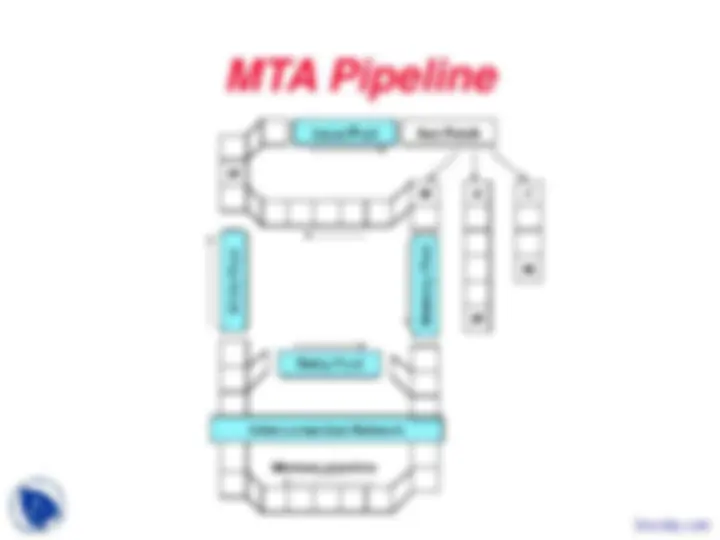
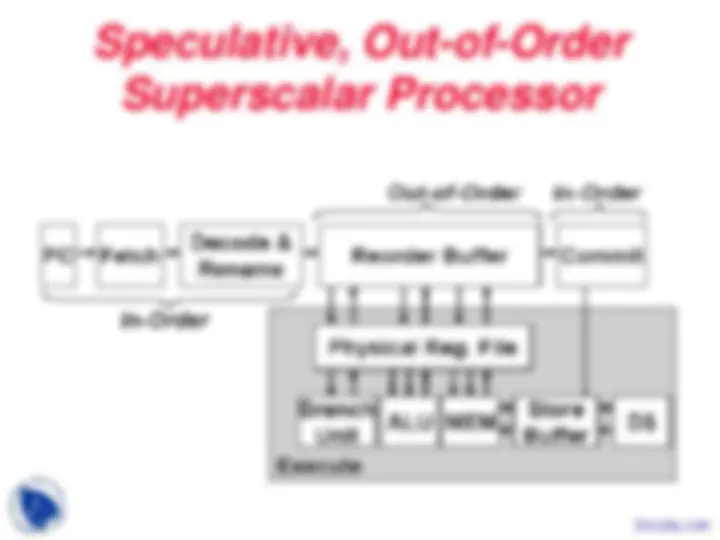
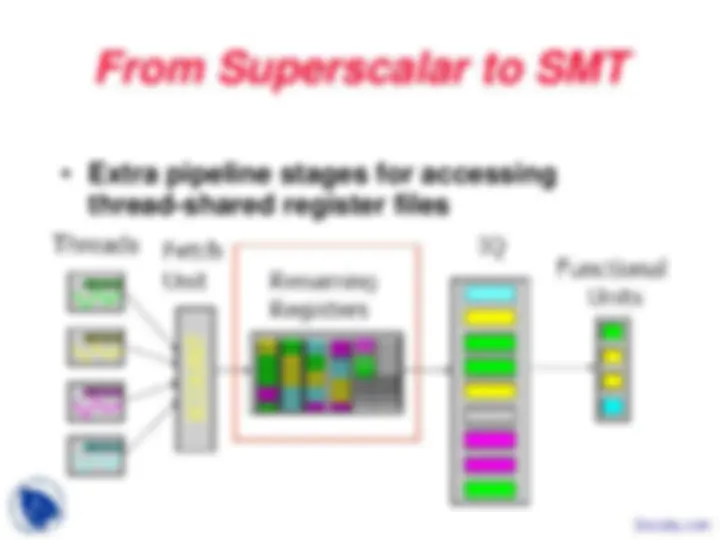
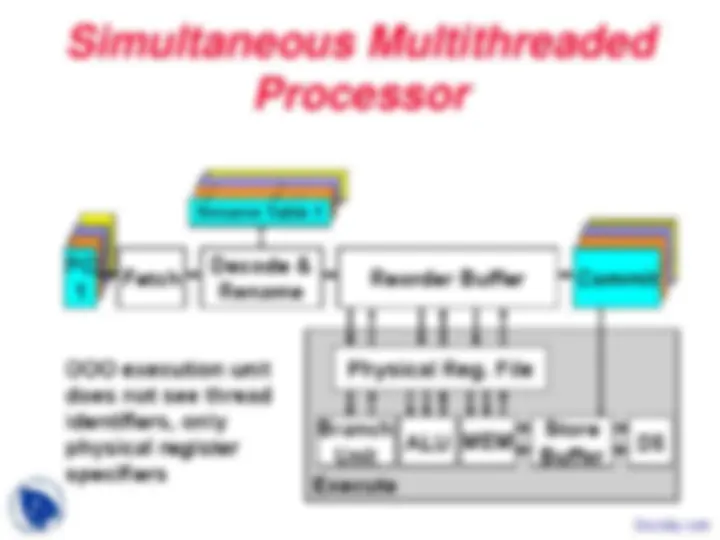
During the course work of the Intro to Computer Architecture, we study the main concept regarding the:Multithreading, Pipeline Hazards, Peripheral Processors, Simple Multithreaded Pipeline, Multithreading Costs, Thread Scheduling Policies, Coarse-Grained Multithreading, Multithreading Design Choices, Instruction Format
Typology: Slides
1 / 30

This page cannot be seen from the preview
Don't miss anything!
LW r1, 0(r2) LW r5, 12(r1) ADDI r5, r5, # SW 12(r1), r