Download Naive Bayes Classifiers - Data Mining - Lecture Slides | STAT 59800 and more Study notes Data Analysis & Statistical Methods in PDF only on Docsity!
Data Mining
CS57300 / STAT 59800-
Purdue University February 17, 2009 1
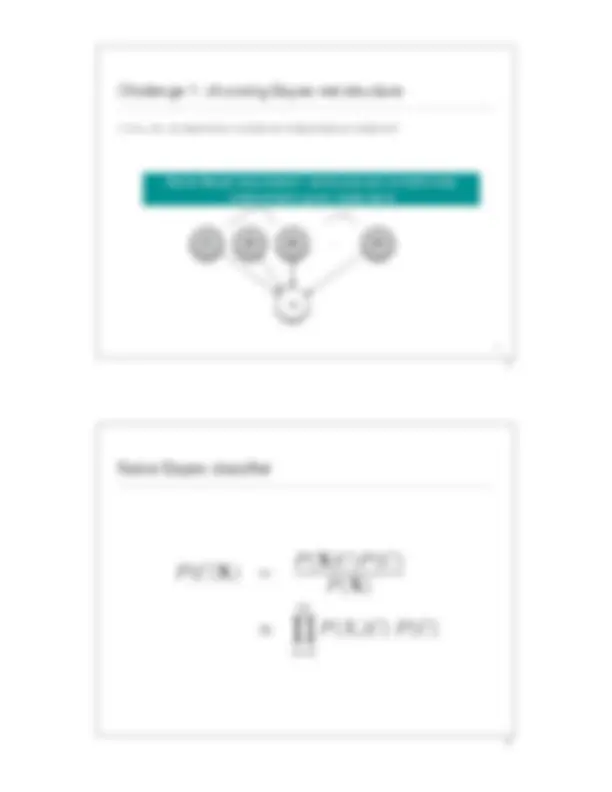
Naive Bayes classifiers
Example: Home security
3
Semantics
- The full joint distribution is defined as the product of the local conditional distributions: - P (X 1 , … ,Xn) =^ !i = 1 P (Xi | Parents(Xi ))
- Example:
- P(j! m! a! ¬b! ¬e) = P(j|a) P(m|a) P(a|¬b,¬e) P(¬b) P(¬e) n
NBC learning
- Estimate prior P(C) and conditional probability distributions P(Xi | C) independently w/MLE
- P(C)=9/ P(I=high|C=yes)=2/ P(I=med|C=yes)=4/ P(I=low|C=yes)=3/ etc. 15 CS 590 D 30 prediction
- Bayesian Classification
- Instance Based Methods
- Classification by decision tree induction
- Classification by Neural Networks
- Classification by Support Vector Machines (SVM)
- Prediction CS 590 D 31 Training Dataset age income student credit_rating buys_computer <= 30 high no fair no <= 30 high no excellent no 31 … 40 high no fair yes
40 medium no fair yes 40 low yes fair yes 40 low yes excellent no 31 … 40 low yes excellent yes <= 30 medium no fair no <= 30 low yes fair yes 40 medium yes fair yes <= 30 medium yes excellent yes 31 … 40 medium no excellent yes 31 … 40 high yes fair yes 40 medium no excellent no !"#$% &'((')$%+%% ,-./(,% & 0 '.% 12 #+(*+ 3 $% 456 7 Learning CPTs from examples
False 2 13 0
True 10 13 17
Low Medium High
f( x )
X 1
P[ X 1 = Low | f(x) = True] =
P[ F(x) = False] =
8
Zero counts are a problem
- If an attribute value does not occur in training example, we assign zero probability to that value
- How does that affect the conditional probability P[ F(x) | x ]?
- It equals 0!!!
- Why is this a problem?
- Adjust for zero counts by “smoothing” probability estimates 9
Add uniform prior
Smoothing: Laplace correction
False 2 13 0
True 10 13 17
Low Medium High
f( x )
X 1
P[ X 1 = High | f(x) = False] =
NBC learning
- Model space?
- Search algorithm?
- Evaluation function? 13
Other predictive models
Nearest neighbor
- Instance-based method
- Store instance and delay processing until a new instance must be classified
- All point represented in m-dimensional space
- Nearest neighbors are calculated using Euclidean distance
- k-NN returns the most common value among k closest training examples
Nearest neighbor decision boundary
- All points in such a cell are labeled by the class of the training point, forming a Voronoi tesselation of the feature space. Source: http://www.cs.bilkent.edu.tr/~saksoy/courses/cs551-Spring2008/slides/cs551_nonbayesian1.pdf
Neural networks
- Analogous to biological systems
- Massive parallelism is computationally efficient
- First learning algorithm in 1959 (Rosenblatt)
- Perceptron learning rule
- Provide target outputs with inputs for a single neuron
- Incrementally update weights to learn to produce outputs 19
Neuron
CS 590 D 56
A Neuron
-^ μ k
f
weighted sum Input vector x output y Activation function weight vector w ! w 0 w 1 wn x 0 x 1 xn y sign( ) For Example n i 0 = (^)! wi xi + μ k =
Multi-Layer Perceptron
20
Perceptron
!"#$"%&#'( !"#$%&'($)%&%"+#'+,'-$'"#).* ()%/$ ,012'3'!)*+",- ./+ 01234 (/ 5 /+ 00 4 5 '
' ' (^) ' ' '
- 6)7%*$'&.8$ ",':"'!) 6 *+ 3 ",- 7819 7&."( ) 6 ,: 717 ) 67 ,7#:"'+ 3 6 ,, f (x) = ∑^ m i= wixi + b y = sign[f (x)] Model: Learning:
if y(j)(
∑^ m
i=
wixi(j) + b) ≤ 0
then w ← w + ηy(j)x(j)
21
Perceptron learning
- Model space?
- Search algorithm?
- Evaluation function?
Maximize margin
Source: Introduction to Data Mining, Tan, Steinbach, and Kumar 25
Linear SVMs
- Search for hyperplane with largest margin
- Margin=d+ + d- where d+ is distance to closest positive example and d- is distance to closest negative example !"#$%&'()**+&,'-$.,+&'/%. 0 "#$ 1
2 (-/1'5++A'>+&'0?$&5%#$'B",0',0$'5%&;$1,'8%&;"#
7
7 (^777) 7 7
Constrained optimization
Eq 1 : x(j) · w + b ≥ +1 f or y(j) = + Eq 2 : x(j) · w + b ≤ − 1 f or y(j) = − 1 Eq 3 : y(j)(x(j) · w + b) − 1 ≥ 0 ∀y(j) H 1 : x(j) · w + b = + 1 H 2 : x(j) · w + b = − 1 d+ = d− = 1 ||w||
- Can maximize margin by minimizing ||w||^2 subject to constraints
margin =
||w||
27
Constrained optimization
- Can maximize margin by minimizing ||w|| subject to constraints on Eq
- Introduce Lagrange multipliers and minimize
Limitations of linear SVMs
- Linear classifiers cannot deal with:
- Non-linear concepts
- Noisy data
- Solutions:
- Soft margin (e.g., allow mistakes in training data)
- Network of simple linear classifiers (e.g., neural networks)
- Map data into richer feature space (e.g., non-linear features) and then use linear classifier 31
Map to new features
- Define a new set of features where data are linearly separable:
#(x)=[x 1 , x 2 , x 1 x 2 , x 12 , x 22 ,...] !"#$%&'()*
' : ' ' : : !;' 9 !;: 9 !;: 9 !;: 9 !;' 9 !;' 9
Kernel trick
- Note that the dual problem only depends on #iT#j
- Move to an infinite number of features by replacing # with a kernel: #iT#j " K(i,j)
- Here kernel K is a function that returns the value of the dot product between the two arguments
- As long as kernel is symmetric and positive semi-definite you can forget about the features - Example: Polynomial kernel K(i,j)=[r+ x(i)Tx(j)]d 33
Kernel SVMs
- State-of-the-art classifier (with good kernel)
- Solves computational problem of working in high dimensional space
- Non-parametric classifier (keeps all data around in kernel)
- Learning: O(n^2 ) (approximations available for O(n))