Download Priority Queues and Heaps: Implementation and Properties and more Study notes Computer Science in PDF only on Docsity!
COP 3502H – Computer Science I – CLASS NOTES - DAY #
A priority queue is essentially a list of items in which each item has associated
with it a priority. In general, different items may have different priorities and thus
we speak of one item having a higher priority than another. Given such a list we
can determine which is the highest (or lowest) priority item in the list. In general,
items are inserted into a priority queue in arbitrary order. However, items are
removed from the priority queue in the order of their priorities, typically starting
with the highest priority item first. A single integer value is commonly used to
indicate the priority of an item an typically the smaller this value the higher the
priority of the item, however, this is also a problem specific consideration and
other situations may occur.
Priority queues are commonly used by operating systems to manage the various
functions of process control. For example, consider the software which manages a
shared resource such as a networked printer. In general, it is possible for users to
submit print jobs much more quickly than it is possible for the printer to print them
(case in point are the CCII labs!). A simple solution is to place the print jobs into a
FIFO queue. While this may seem fair in that the jobs are printed on a first-come,
first-served basis, a user who has submitted a short document for printing will
experience a long delay when much longer documents are already in the queue.
An alternative solution is to use a priority queue in which the shorter the document,
the higher its priority. In fact, it can be proven that printing documents in the order
of their length minimizes the average time a user waits for their document to be
printed.
Priority queues are also often used in the implementation of algorithms. Typically
the problem to be solved consists of a number of subtasks, and the solution strategy
involves prioritizing the subtasks and then performing those subtasks in the order
of their priorities. Priority queues can be used to improve the performance of
many backtracking algorithms. Priority queues are the basis for an optimal
comparison based sorting algorithm known as the heap sort (we’ll look at this sort
later). Many graph algorithms utilize priority queues to control traversing within
the graph.
A mergeable priority queue is one that provides the ability to merge efficiently two
priority queues into one. While this capability goes beyond the depth at which we
will look at priority queues it is nonetheless an important aspect of dealing with
priority queues. The reason that I mention it here is that a special kind of tree,
Heaps and Priority Queues
called a leftist tree (no, its not a political statement) is typically employed when
two or more priority queues will be merged; we will not discuss leftist trees in any
detail, except for a cursory look. There are also more complex versions of priority
queues which are double-ended in which both the highest and lowest priority items
can be removed simultaneously. Efficient implementation of such a structure
requires an even more specialized type of tree called a pairing heap.
Priority Queue Summary
A priority queue is a structure where the highest priority item is the next item
that will be dequeued. (Note that a priority queue can also be used to select the
lowest priority item although this is less common.)
Implementation typically sets the highest priority item to have the lowest
integer value as its priority.
Thus, the node with the lowest integer value should always be at the head of the
queue.
If implemented as a binary heap, insertion and deletion can be done in
logarithmic time in the worst case.
Implementation Issues
A priority queue can be implemented in many different fashions, including that of
a linked list. If an unsorted list is used, enqueueing can be accomplished in O(1)
time. However, finding the element with highest priority and removing this item
from the list will require O(n) time where n is the number of items in the queue. If
a sorted list is used, finding the item with the highest priority and removing it
becomes a O(1) operation, however, the enqueueing of a new item now becomes
an O(n) operation.
Another way to implement a priority queue is to use a search tree. An AVL tree
is a balanced tree in which the left and right subtrees of the root node differ in
height by at most 1. If an AVL tree is used to implement the priority queue then it
can be shown that all three operations, finding the highest priority item, deleting
the highest priority item, and inserting a new item can all be accomplished in O(log
n) time. However, search trees provide more functionality than is required for a
priority queue. For instance, a search tree permits the removal of an arbitrary item
from the tree an operation which is not allowed in a priority queue.
What is required to implement a priority queue is a structure with more efficient
enqueueing and dequeueing operations than a linked list provides but with less
functionality than is supported by a search tree. A commonly used structure to
implement a priority queue is a heap which is a special case of a tree.
- In a complete binary tree, left and right references are not needed. Instead
the level-order traversal of the tree can be stored in single-dimension array.
The root node is stored in array position 1 (position 0 is utilized later by the
priority queue). For any element in array position i , its left child will be
found in position 2i and its right child will be found in position 2i+1. To
determine it a node at index i has children test to see if 2i > number of
elements. To determine the parent of a node at index i , check at index i/2 .
Using an array to represent a tree is called an implicit tree representation. This
method is very fast on most systems and the traversal operation become trivial
and extremely fast.
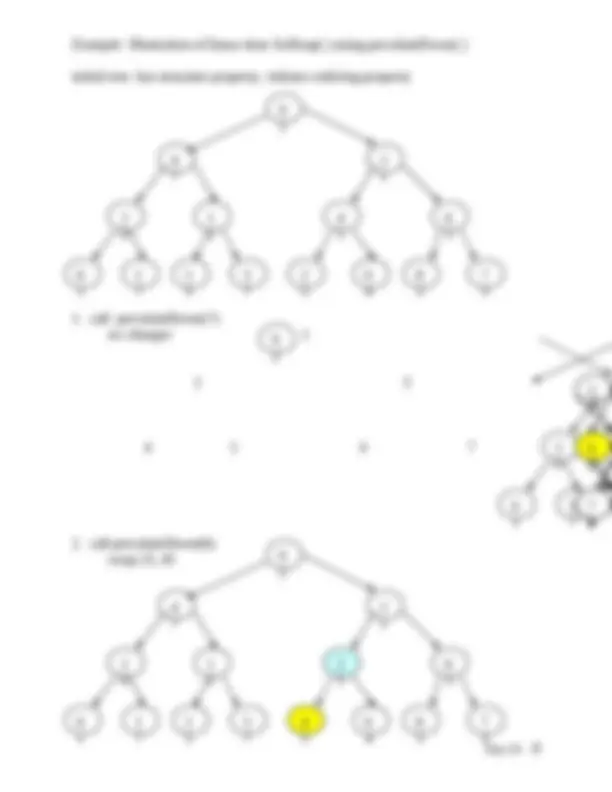
Example:
A B C D E F G H I J
Left child of node “A” ( index 1) is located at index (2*1) = 2 or node “B”
Right child of node “A” (index 1) is located at index (2*1) +1 = 3 or node “C”
Parent of node “F” (index 6) is located at 6/2 = 3 or node “C”
Parent of node “I” (index 9) is located at 9/2 = 4 or node “D”
Child of node “H” (index 8) is located at (2*8) = 16 out of range so no child
exists.
A
B C
D E F G
H I J
Ordering Property (Heap Order)
In a heap, for every node x with parent p , the key value in p is smaller than
the key value in x.
The root always has the highest priority.
Parent nodes have higher priority than their children.
To indicate that the root has no parent and is of the highest priority, the
implicit representation (the one using an array) will put ∞ position 0 of the
array.
Basic Operations on the Heap
Insert
- Insert a node into the next available spot (i.e., in the bottom ply).
- Compare the key value of the new node with its parent’s key value, if the
new node’s key value is less than its parent’s – interchange the nodes.
- “Percolate” the node up into its correct position by recursively applying
step #2.
Example:
Example:
`
`
More Details on Insertion into a Binary Heap
The insertion technique that we used for inserting items into the binary heap,
inserted N items and required O(log 2 N) time to find the right spot at which to do
the insertion. Thus the time required to insert N items is: O(N log 2 N).
A better solution
A better solution to this problem involves a different technique for handling the
insertion. The general algorithm is to place the items into the heap in arbitrary
order (heap ordering is not preserved) while maintaining the structure property of
the tree (the tree is complete). After the initial tree is constructed, then a fixHeap
operation is called on every non-leaf node in the tree using a reverse level-order
traversal which will percolate down non-heap ordered nodes eventually creating a
heap-ordered tree. This process is shown below
Since the binary heap is implemented as an array, we can fill the array (insert the N
items) without regard to their proper order in linear time, O(N). Then call fixHeap
to structure the heap in linear time O(N). Therefore, this method will require O(N
log 2 N) time in the worst case.
[Note: fixHeap can be implemented in linear time. The following example
illustrates how this technique works.] Starting with the first non-leaf level from
the bottom of the tree, using a reverse level-order traversal, percolate the minimum
value to the root of the current subtree. Note that leaf nodes do not need to be
considered as they have no children with which to compare. The reason for the
linear time bound is the bound which will be set on the number of swaps that
fixHeap will need to make ensure heap ordering and this bound will be O(N). The
theorem for this is in your textbook, if you’re interested.
Example: Illustration of linear time fixHeap( ) using percolateDown( )
initial tree: has structure property, violates ordering property
- call percolateDown(7)
no changes 1
- call percolateDown(6)
swap 25, 45
- call percolateDown(2)
swap 12, 47 then swap 37, 47
- call percolateDown(1)
swap 12, 92, followed by 17, 92 , followed by 20, 92
final heap shown above
This technique is not without its problems, which include:
Requires 2N space as 2 arrays are needed, one for the unordered heap and one
created in heap order by fixHeap( ).
Fix: This problem can be solved by using a “sliding heap” and altering the
method fixHeap( ) to return the largest item. As maximal items are returned
we remove them from the heap and decrease the size of the heap by one.
The removed item is then placed into the cell of the array which has been
“freed” from the heap.
Example:
- call fixHeap( )
- call fixHeap( )
- call fixHeap( )
- call fixHeap( )
- call fixHeap( )
- call fixHeap( )
Day 24 - 11
heap
end of
heap
heap
end of
heap heap
end of
heap
heap
end of
heap
heap
end of
heap
heap
end of
heap
heap
end of
heap
end of
heap
end of
heap
the heap and will be O(n). For larger values of k , the running time is O( k log n)
since the time will be dominated by the k deletions from the heap. If k = n/2, then
the running time is (n log n).
Sorting Using A Binary Heap
Think about the process that we just went through to select the k th smallest
element from a list of elements. Instead of assuming the k < n , what happens if k
= n? If we set k = n and record the values that are removed from the heap as they
are removed, we will have essentially sorted the elements in the array in O(n log n)
time. Recall that all of the comparison based sorting algorithms that we covered
earlier in the semester had a O(n
2 ) worst case running time.
Recall that the binary heap has both an ordering property and a structure
property. The ordering property ensures that the items in the heap are basically
sorted from minimum (root) value to maximum values (leafs).
Removing (or reading) everything results in a sort.
If this can be done in O(N log 2 N) time, then we have found an optimal
“comparison” based sorting algorithm.
The deletion technique, called deleteMin( ) (our Java method), removes the root
item from the heap and requires O(1) time to do this, then the heap structure is
reset and the ordering preserved which requires an additional O(log 2 N) time.
Since there are N items in the heap, removing all of them (i.e., emptying the heap)
requires O(N log 2 N) time. The method deleteMin( ) still requires O(N log 2 N)
time in the worst case.
Backtracking Algorithms
Using a priority queue to control the searching within the search space constructed
by a backtracking algorithm can make the algorithm much more efficient than a
search controlled simply based upon a level order traversal of the search space.
The better the chance of finding a solution down one path the higher the priority
should be that this path is explored before a path which has a lower probability of
finding a solution (that is, a solution better than any currently discovered). Thus
the value of the objective function for each node on a particular level will be
prioritized and placed into a priority queue with the solution space searched on a
highest priority first basis.
MinHeaps and MaxHeaps
In the examples that we covered above, the heaps were all MinHeaps. In a
MinHeap the items with the smaller values are higher up in the tree (closer to the
root) with the root node having the smallest value in the heap. Typically, in
Computer Science applications involving priority, the smaller the priority number
assigned to an element the higher the priority of that element. In this fashion a
MinHeap works well. However, there are also applications which require O(1)
access to the item with the largest value. This type of heap is called a MaxHeap.
A MaxHeap maintains the larger valued items higher in the tree with the root node
having the largest value of all items in the heap. The leaf nodes in a MaxHeap will
contain the smallest valued items in the heap.
More Complex Heap Structures
Leftist Heaps
A leftist heap is a tree that tends to “lean” to the left. That is to say it is skewed to
the left. This skewing is defined in terms of the shortest path from the root to a
leaf node (external node). In a leftist tree, the shortest path to a leaf node is always
found in the right subtree of the root.
Every node in a binary tree has associated with it a quantity called its null path
length , which is defined as follows:
Definition: Null path length of a node:
Consider an arbitrary node x in some binary tree T. The null path length of node x
is the shortest path in T from x to an external node of T. The null path length of
node x is the length of its null path.
Typically, the null path length is expressed not in terms of an arbitrary node x , but
rather in terms of the entire tree:
Definition: Null path length of a tree:
The null path length of an empty tree is zero and the null path length of a non-
empty binary tree T = {r, T L
, T
R } is the null path length of its root r.
A leftist tree is a tree defined as: