Download Guide to Code Optimization: Compiler Options, Interprocedural Optimization, and Performanc and more Study notes Military Strategy and Training in PDF only on Docsity!
Optimization and Performance
Engineering for Scientific Applications
(x86-64)
Byoung-Do Kim
TACC
June 12, 2009
Outline
1. Introduction
2. Compiler Options
3. Performance Libraries
4. Code Optimizations
1 Compiler Options
- Three important Categories
- Optimization Level
- Architecture Specification
- Interprocedural Optimization
You should always have at least one option from each category!
2 Compilers and Optimization
- Compilers can perform significant optimization
- The compiler follows your lead!
- Structure code to make apparent what the compiler should do (so that the compilers and others can understand it).
- Use simple language constructs (e.g. don’t use pointers, or OO code).
- Use latest compilers.
- Always check compiler options <compiler_command> --help {lists/explains options}
- Look for architecture options for your system See User Guides – usually lists “best practice” options cat /proc/cpuinfo {shows cpu information}
- Experiment with different options.
- May need routine-specific options (use - ipo ).
Optimization Levels
• Operations performed at default optimization
level
- instruction rescheduling
- copy propagation
- software pipelining
- common subexpression elimination
- prefetching, (some loop transformations)
• Operations performed at aggressive
optimization levels
- Usually enabled by – O
- more aggressive prefetching, loop transformations
Architecture Specification
X87 instruction sets are now replaced by SSE “Vector” instruction sets.
(S)SSE = (Supplemental) Streaming SIMD Extension
SSE instructions sets are chip dependent
(SSE instructions pipeline and simultaneously execute independent operations to get multiple results per clock period.)
The – x { code = W, P, T, O, S} directs the compiler to use most advanced SSE instruction set for the target hardware.
Interprocedural Optimization (IP)
- Most compilers will handle IP within a single file (option – ip)
- The Intel -ipo compiler option does more
- It adds additional information to each object file.
- Then, during loading, the code is recompiled and IP among ALL objects is performed.
- May take much more time: Code is recompiled during linking
- It is Important to include options in link command (-ipo – O# -xW, etc.) (special Intel xild loader replaces ld)
- When archiving in a library, you must use xiar, instead of ar.
Interprocedural Optimization (IP)
Intel
-ip enable single-file interprocedural (IP) optimizations (within files). Line numbers produced for debugging -ipo enable multi-file IP optimizations (between files)
PGI
-Mipa=fast,inline Interprocedural Optimization
Other PGI Compiler Options
Processor-specific optimization options:
-fast -O2 -Munroll=c:1 -Mnoframe -Mlre -Mautoinline -Mvect=sse -Mscalarsse -Mcache_align -Mflushz
-mp thread generation for OpenMP directives -Minfo=mp,ipa OpenMP/Interprocedural Opt. reporting
Compilers - Best Practice
- Normal compiling for Ranger
intel icc/ifort -O3 -ipo -xW prog.c/cc/f
pgi pgcc/pgcpp/pgf95 -fast -tp barcelona-
-Mipa=fast,inline
prog.c/cc/f
gnu gcc – O3 – fast – xipo -mtune=barcelona -march=barcelona
prog.c
- O2 is default opt, compile with – O0 if this breaks (very rare)
- The effects of -xW and -xO options may vary
- Don’t include debug options for a production compile!
ifort – O2 – g – CB test.c
Linux x86-64 (Lonestar/Ranger)
Libraries - 3rd^ Party Applications
gprof
TAU PAPI
DDT
…
Amber NAMD GROMACS
Gamess NWchem
…
SPRNG
Metis/parmetis
FFTW (2/3)
MKL GSL GotoBLAS
PETSc
PLAPACK SCALAPACK SLEPc
…
NetCDF HDF (4/5)
Parallel I/O
GridFTP …
Performance Math Libs Method Libs Applications I/O
Intel MKL 10.0 (Math Kernel Library)
• Optimized for the IA32, x86-64, IA64 architectures
• supports both Fortran and C interfaces
• Includes functions in the following areas:
- BLAS (levels 1-3)
- LAPACK
- FFT routines
- … others
- Vector Math Library (VML)
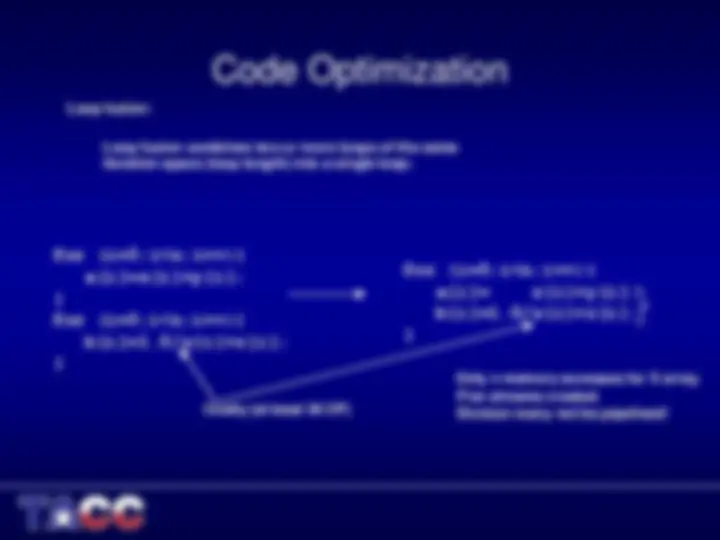
Code Optimization
- Always minimize stride length
- Stride length 1 is optimal for vectorizable code.
- This increases cache efficiency, and sets up hardware and software prefetching.
- Stride lengths of powers of two are typically the worst case scenario leading to cache misses.
- Strive to write Vectorizable Loops
- Can be sent to a SIMD Unit
- Can be unrolled and pipelined
- Can be parallelized through OpenMP Directives
- Can be “automatically” parallelized (be careful…)
G4/5 Velocity Engine (SIMD) Intel/AMD MMX, SSE, SSE2, SSE3 (SIMD) Cray Vector Units
SIMD (Single Instruction
Multiple Data)
SSE (Streaming SIMD
Extensions) instructions
operate on multiple data
arguments simultaneously
• Write loops with independent iterations, so
that SSE instructions can be employed
SIMD
4 Code Optimization
Data Pool
PU
PU
PU
PU
Instructions