Download Embedded Systems: Optimizing Instruction Execution in Software Design and more Slides Computer Science in PDF only on Docsity!
3-Software Design Basics in
Embedded Systems
Optimizing the design of General
Purpose processors
Pipelining: Increasing Instruction
Throughput
Fetch-instr.
Decode
Fetch ops.
Execute
Store res.
Wash
Dry
Time
Non-pipelined Pipelined
Time
Time
Pipelined
pipelined instruction execution
non-pipelined dish cleaning pipelined dish cleaning
Instruction 1
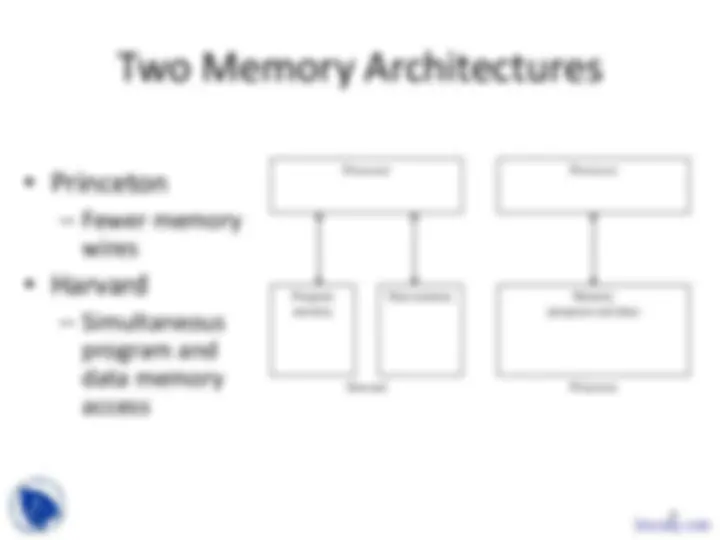
Two Memory Architectures
• Princeton
– Fewer memory
wires
• Harvard
– Simultaneous
program and
data memory
access
Processor
Program memory
Data memory
Processor
Memory (program and data)
Harvard Princeton
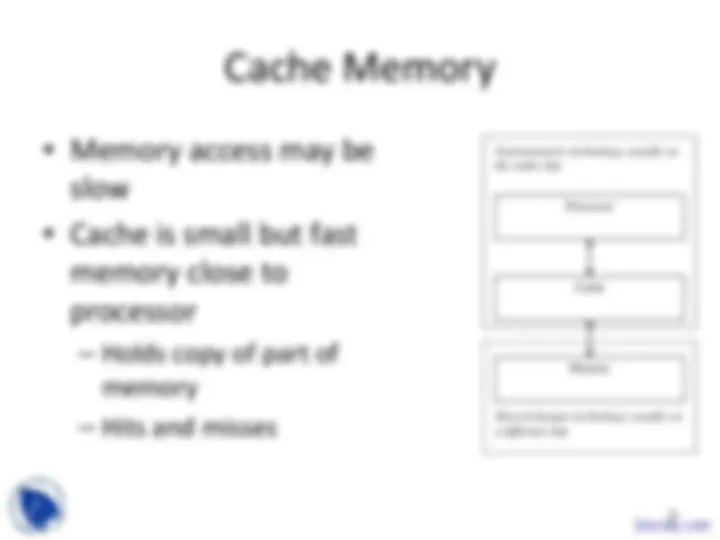
Cache Memory
• Memory access may be
slow
• Cache is small but fast
memory close to
processor
– Holds copy of part of
memory
– Hits and misses
Processor
Memory
Cache
Fast/expensive technology, usually on the same chip
Slower/cheaper technology, usually on a different chip
Assembly-Level Instructions
• Instruction Set
– Defines the legal set of instructions for that processor
• Data transfer: memory/register, register/register, I/O, etc.
• Arithmetic/logical: move register through ALU and back
• Branches: determine next PC value when not just PC+
opcode operand1 operand
opcode operand1 operand
opcode operand1 operand
opcode operand1 operand
Instruction 1
Instruction 2
Instruction 3
Instruction 4
A Simple Instruction Set
opcode operands
MOV Rn, direct
MOV @Rn, Rm
ADD Rn, Rm
0000 Rn direct
0010 Rn
0100 Rn Rm
Rn = M(direct)
Rn = Rn + Rm
SUB Rn, Rm 0101 Rm Rn = Rn - Rm
MOV Rn, #immed. 0011 Rn immediate Rn = immediate
Assembly instruct. First byte Second byte Operation
JZ Rn, relative 0110 Rn relative PC = PC+ relative (only if Rn is 0)
Rn
MOV direct, Rn 0001 Rn direct M(direct) = Rn
Rm (^) M(Rn) = Rm
Sample Programs
- Try some others
- Handshake: Wait until the value of M[254] is not 0, set M[255] to 1, wait until M[254] is
0, set M[255] to 0 (assume those locations are ports).
- (Harder) Count the occurrences of zero in an array stored in memory locations 100
through 199.
int total = 0; for (int i=10; i!=0; i--) total += i; // next instructions...
C program
MOV R0, #0; // total = 0 MOV R1, #10; // i = 10
JZ R1, Next; // Done if i= ADD R0, R1; // total += i
MOV R2, #1; // constant 1
JZ R3, Loop; // Jump always
Loop:
Next: // next instructions...
SUB R1, R2; // i--
Equivalent assembly program
MOV R3, #0; // constant 0
Programmer Considerations
• Program and data memory space
– Embedded processors often very limited
• e.g., 64 Kbytes program, 256 bytes of RAM
(expandable)
• Registers: How many are there?
– Only a direct concern for assembly-level
programmers
• I/O
– How communicate with external signals?
• Interrupts 11
Application-Specific Instruction-Set
Processors (ASIPs)
• General-purpose processors
– Sometimes too general to be effective in
demanding application
• e.g., video processing – requires huge video buffers and
operations on large arrays of data, inefficient on a GPP
– But single-purpose processor has high NRE, not
programmable
• ASIPs – targeted to a particular domain
– Contain architectural features specific to that
domain
• e.g., embedded control, digital signal processing, video
processing, network processing, telecommunications, 13
A Common ASIP: Microcontroller
- For embedded control applications
- Reading sensors, setting actuators
- Mostly dealing with events (bits): data is present, but not in huge amounts
- e.g., VCR, disk drive, digital camera (assuming SPP for image compression), washing
machine, microwave oven
- Microcontroller features
- On-chip peripherals
- Timers, analog-digital converters, serial communication, etc.
- Tightly integrated for programmer, typically part of register space
- On-chip program and data memory
- Direct programmer access to many of the chip’s pins
- Specialized instructions for bit-manipulation and other low-level operations
Trend: Even More Customized
ASIPs
- In the past, microprocessors were acquired as chips
- Today, we increasingly acquire a processor as Intellectual Property (IP)
- e.g., synthesizable VHDL model
- Opportunity to add a custom datapath hardware and a few custom instructions, or
delete a few instructions
- Can have significant performance, power and size impacts
- Problem: need compiler/debugger for customized ASIP
- Remember, most development uses structured languages
- One solution: automatic compiler/debugger generation
- Another solution: retargettable compilers
- e.g., www.improvsys.com (customized VLIW architectures)
Selecting a Microprocessor
- Issues
- Technical: speed, power, size, cost
- Other: development environment, prior expertise, licensing, etc.
- Speed: how evaluate a processor’s speed?
- Clock speed – but instructions per cycle may differ
- Instructions per second – but work per instr. may differ
- Dhrystone: Synthetic benchmark, developed in 1984. Dhrystones/sec.
- MIPS: 1 MIPS = 1757 Dhrystones per second (based on Digital’s VAX 11/780). A.k.a.
Dhrystone MIPS. Commonly used today.
- So, 750 MIPS = 750*1757 = 1,317,750 Dhrystones per second
- SPEC: set of more realistic benchmarks, but oriented to desktops
- EEMBC – EDN Embedded Benchmark Consortium, www.eembc.org
- Suites of benchmarks: automotive, consumer electronics, networking, office
automation, telecommunications
Designing a General Purpose
Processor
- Not something an embedded system
designer would normally do (if desire
a complex big scale GPP)
- But instructive to see how simply we
can build one top down
- Remember that real processors aren’t
usually built this way
- Much more optimized, much
more bottom-up design
Declarations: bit PC[16], IR[16]; bit M[64k][16], RF[16][16];
Aliases: op IR[15..12] rn IR[11..8] rm IR[7..4]
dir IR[7..0] imm IR[7..0] rel IR[7..0]
Reset
Fetch
Decode
IR=M[PC]; PC=PC+
Mov1 RF[rn] = M[dir]
Mov
Mov
Mov
Add
Sub
Jz 0110
0101
0100
0011
0010
0001
op = 0000
M[dir] = RF[rn]
M[rn] = RF[rm]
RF[rn]= imm
RF[rn] =RF[rn]+RF[rm]
RF[rn] = RF[rn]-RF[rm]
PC=(RF[rn]=0) ?rel :PC
to Fetch
to Fetch
to Fetch
to Fetch
to Fetch
to Fetch
to Fetch
PC=0;
from states below
FSMD
Architecture of a Simple
Microprocessor
- Storage devices for each declared
variable
- register file holds each of the
variables
- Functional units to carry out the
FSMD operations
- One ALU carries out every required
operation
- Connections added among the
components’ ports corresponding to
the operations required by the FSM
- Unique identifiers created for every
control signal
Datapath
PC IR
Controller (Next-state and control logic; state register)
Memory
RF (16)
RFwa RFwe RFr1a RFr1e RFr2a RFr2e
RFr1 RFr
RFw
ALU
ALUs
2x1 mux
ALUz
RFs
PCld PCinc PCclr
Ms (^) 3x1 mux Mre Mwe
To all input control signals
From all output control signals
Control unit
16 Irld
2
1
0
A D
1
0