



Lecture No.
27
docsity.com










Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An in-depth exploration of memory management concepts, including page replacement algorithms (global and per-process), thrashing, and the working set model. Learn about the implications of these concepts for system performance and memory usage.
Typology: Slides
1 / 18

This page cannot be seen from the preview
Don't miss anything!
Per-process each process has a separate pool of pages
a page fault in one process can only replace one of this process’s frames isolates process and therefore relieves interference from other processes
but, isolates process and therefore prevents process from using other’s (comparatively) idle resources efficient memory usage requires a mechanism for (slowly) changing the allocations to each pool Qs: What is “slowly”? How big a pool? When to migrate?
Per-process page replacement
P1 P
pool barrier
Thrashing
could be that there is enough memory but a bad replacement algorithm (one incompatible with program behavior)
could be that memory is over-committed
Making the best of a bad situation
Single process thrashing? If process does not fit or does not reuse memory, OS can do nothing except contain damage. System thrashing? If thrashing arises because of the sum of several processes then adapt: figure out how much memory each process needs change scheduling priorities to run processes in groups whose memory needs can be satisfied (shedding load) if new processes try to start, can refuse (admission control) Careful: example of technical vs social. OS not only way to solve this problem (and others). solution: go and buy more memory.
The working set model of program behavior
The working set of a process is used to model the dynamic locality of its memory usage working set = set of pages process currently “needs” formally defined by Peter Denning in the 1960’s Definition: a page is in the working set (WS) only if it was referenced in the last w references obviously the working set (the particular pages) varies over the life of the program so does the working set size (the number of pages in the WS)
Hypothetical Working Set algorithm
How to implement working set?
Associate an idle time with each page frame
idle time = amount of CPU time received by process since last access to page page’s idle time > T? page not part of working set
How to calculate?
Scan all resident pages of a process reference bit on? clear page’s idle time, clear use bit reference bit off? add process CPU time (since last scan) to idle time Unix: scan happens every few seconds T on order of a minute or more
Some problems
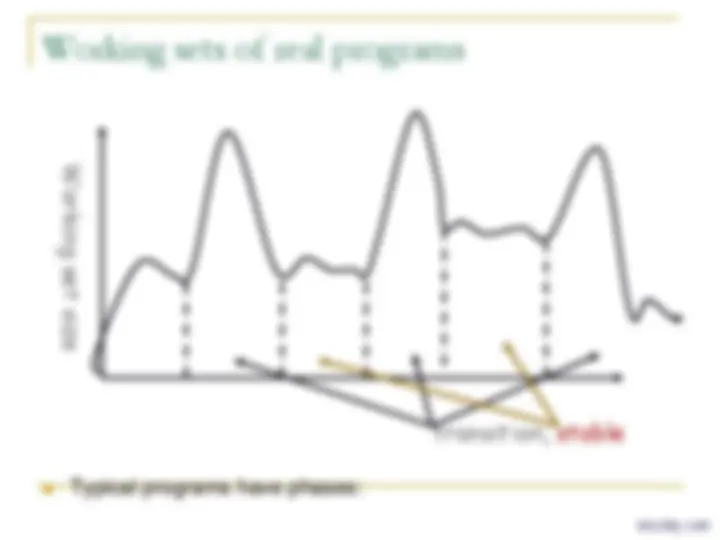
Working sets of real programs
Page Fault Frequency (PFF)
Fault resumption. lets us lie about many
things
Emulate reference bits:
Set page permissions to “invalid”. On any access will get a fault: Mark as referenced
Emulate non-existent instructions:
Give inst an illegal opcode. When executed will cause “illegal instruction” fault. Handler checks opcode: if for fake inst, do, otherwise kill. Run OS on top of another OS!
Make OS into normal process When it does something “privileged” the real OS will get woken up with a fault. If op allowed, do it, otherwise kill. User-mode Linux, vmware.com