


1
Extreme Computing: Parallel Prefix Reductions
8/12/08
Parallel Reduction





















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Material Type: Notes; Class: Introduction to Parallel Algorithms and Programming; Subject: Computer Science and Engr.; University: Notre Dame; Term: Fall 2008;
Typology: Study notes
1 / 29

This page cannot be seen from the preview
Don't miss anything!
Extreme Computing: Parallel Prefix Reductions
8/12/
Extreme Computing: Parallel Prefix Reductions
8/12/
Extreme Computing: Parallel Prefix Reductions
8/12/
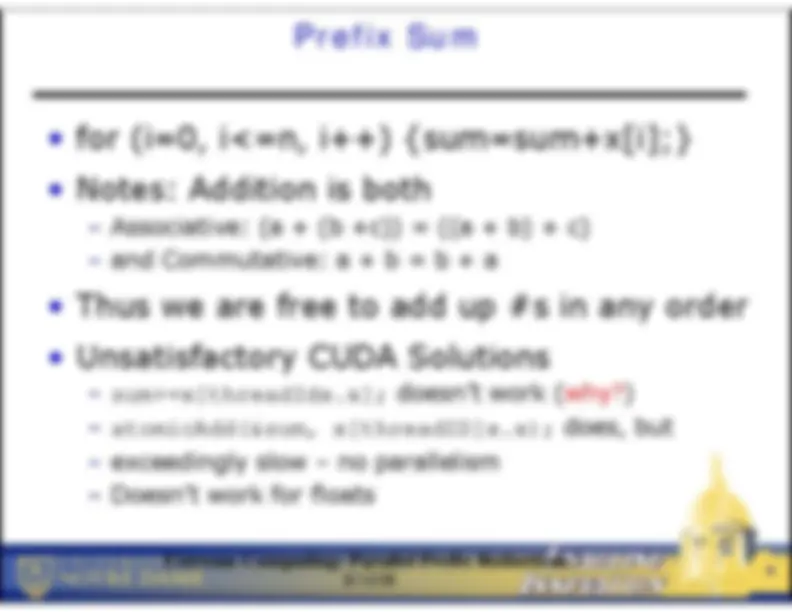
sum+=x[threadIdx.x];
doesn’t work (why?)
atomicAdd(&sum,
x[threadID]x.x);
does, but
Extreme Computing: Parallel Prefix Reductions
8/12/
Step 1: P processors consume 2P operands & create P results
Step 2: P/2 processors consume P operands & create P/2 results
Step K-1: 2 processors consume 4 operands & create 2 results
Step K: 1 processor consume 2 operands & creates 1 results
Assume P = 2
K
Extreme Computing: Parallel Prefix Reductions
8/12/
Note that data is kept grouped in consecutive locations
Time O(log2(N))
Extreme Computing: Parallel Prefix Reductions
8/12/
temp0 (in shared)
N/(2*blockDIM) points
Extreme Computing: Parallel Prefix Reductions
8/12/
Timing It Out
k
, N=
mk
, M>>
nd
2
rd
3
2
mk
m-
2
m-
m
P/log(P)
Extreme Computing: Parallel Prefix Reductions
8/12/
Recurrances
Extreme Computing: Parallel Prefix Reductions
8/12/
(see Parallel Prefix Sum (Scan) with CUDA, Jan. 2008, p.4)
Exactly
length
adds
Each of n threads does log2(n) adds, for total of nlog2(n) addsProblem in CUDA: for large n need to sync the updates
Standard Sequential codeSimple minded Parallel Code: n processors (1 per output)
Extreme Computing: Parallel Prefix Reductions
8/12/
Double Buffered Version
Extreme Computing: Parallel Prefix Reductions
8/12/
(see Parallel Prefix Sum (Scan) with CUDA, Jan. 2008 p. 7)
balanced trees
d
Extreme Computing: Parallel Prefix Reductions
8/12/
d=2 d=1 d=
Note error
in text
Final
Contents of Memory
Extreme Computing: Parallel Prefix Reductions
8/12/
(see Parallel Prefix Sum (Scan) with CUDA, Jan. 2008 p. 10)
Extreme Computing: Parallel Prefix Reductions
8/12/
(see Parallel Prefix Sum (Scan) with CUDA, Jan. 2008 p. 10)