



Database Management Systems Design
Docsity.com



























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
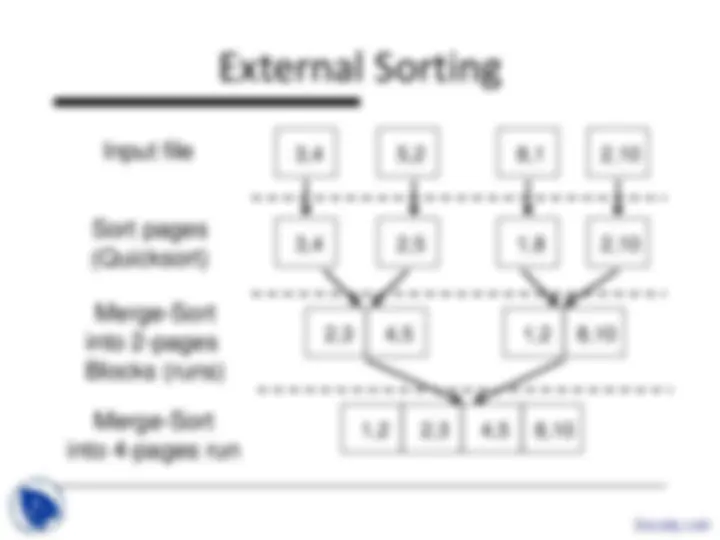
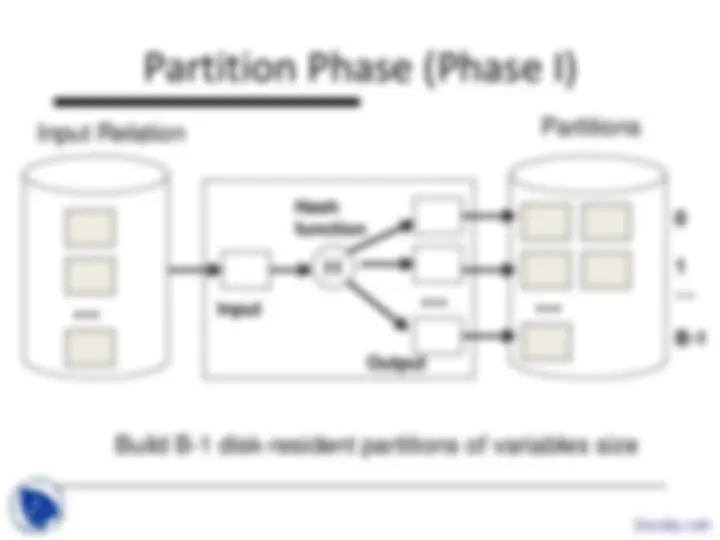
The concept of external sorting and its implementation in database systems. It also covers the selection operators and their access paths, including file scan, index scan, hash index, and b+-tree. Examples and cost estimates for each access path.
Typology: Slides
1 / 39

This page cannot be seen from the preview
Don't miss anything!
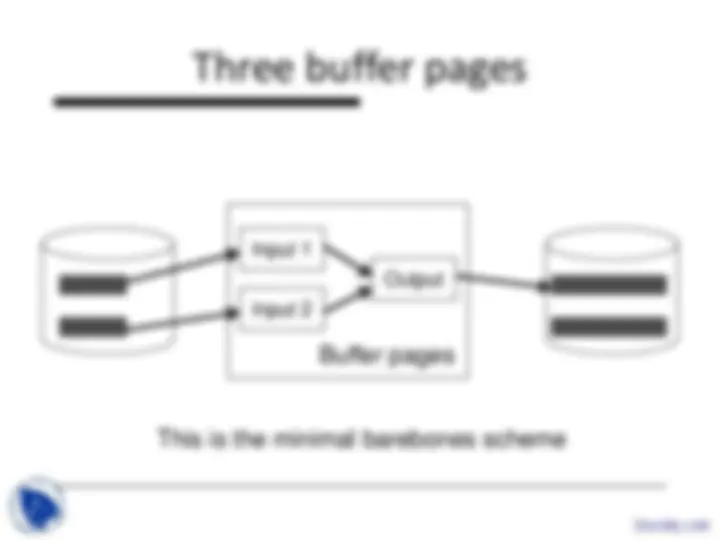
Input 1
Input 2 Output
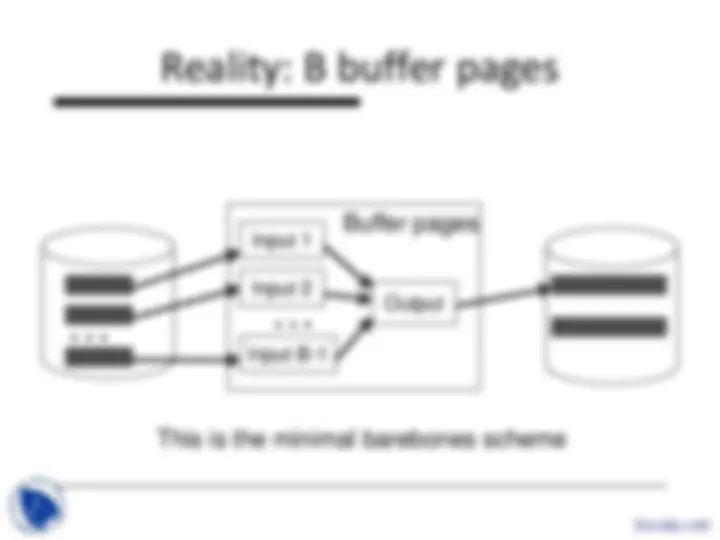
Input B-