



Lecture 7:
Vector Processing
Docsity.com










































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
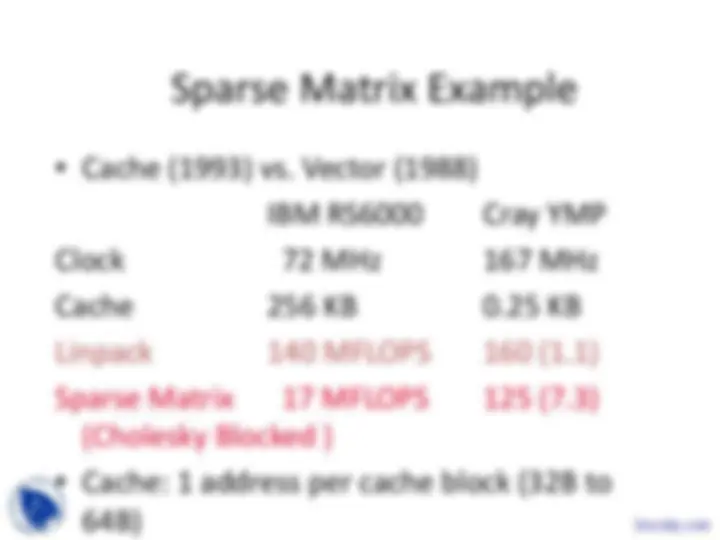
Vector processing, its properties, advantages, and challenges. Vector processors have high-level operations that work on linear arrays of numbers, leading to significant reductions in operations and instructions. However, they also have start-up penalties and vector length limitations. Examples of vector machines and vector instructions, as well as optimizations like conditional execution and sparse matrices.
Typology: Slides
1 / 53

This page cannot be seen from the preview
Don't miss anything!
Computers in the News
Computer News
Thermal gradients Traditional mobile processor versus Crusoe running DVD application
Program
0
10
20
30
40
50
60
gcc expresso li fpppp doducd tomcatv
10
(^1512)
52
17
56
10
(^1512)
47
16 10 13 11
35
15
34
9 10 11
22 12 8 8 9
14 9
14 (^6 4 3 6 4 2 6 4 3 8 5 3 74 3 )
45
22
Infinite 256 128 64 32 16 8 4
(Figure 4.48, Page 332) Perfect disambiguation (HW), 1K Selective Prediction, 16 entry return, 64 registers, issue as many as window
Infinite 256 128 64 32 16 8 4
Integer: 6 - 12
FP: 8 - 45
Window
Properties of Vector Processors
Operation & Instruction Count: RISC v. Vector Processor
Spec92fp Operations (Millions)(from F. Quintana, U. Barcelona.) Instructions (M)
Program RISC Vector R / V RISC Vector R / V
swim256 115 95 1.1x 115 0.8 142x
hydro2d 58 40 1.4x 58 0.8 71x
nasa7 69 41 1.7x 69 2.2 31x
su2cor 51 35 1.4x 51 1.8 29x
tomcatv 15 10 1.4x 15 1.3 11x
wave5 27 25 1.1x 27 7.2 4x
mdljdp2 32 52 0.6x 32 15.8 2x Vector reduces ops by 1.2X, instructions by 20X
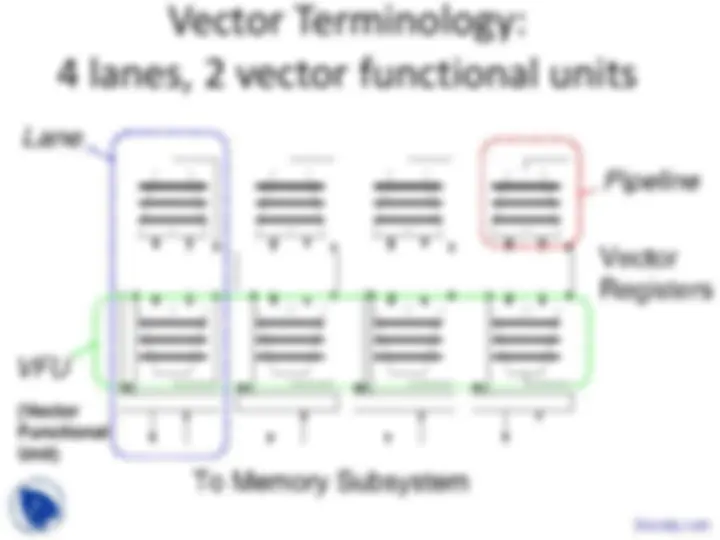
Components of Vector Processor
“DLXV” Vector
Instr. Operands OperationInstructions Comment
scalar + vector
scalar x vector
LD F0,a ADDI R4,Rx,#512 ;last address to load loop: LD F2, 0(Rx) ;load X(i) MULTD F2,F0, F2 ;aX(i) LD F4, 0(Ry) ;load Y(i) ADDD F4,F2, F4 ;aX(i) + Y(i) SD F4 ,0(Ry) ;store into Y(i) ADDI Rx,Rx,#8 ;increment index to X ADDI Ry,Ry,#8 ;increment index to Y SUB R20,R4,Rx ;compute bound BNZ R20,loop ;check if done
LD F0,a ;load scalar a LV V1,Rx ;load vector X MULTS V2,F0,V1 ;vector-scalar mult. LV V3,Ry ;load vector Y ADDV V4,V2,V3 ;add SV Ry,V4 ;store the result
Assuming vectors X, Y are length 64 Scalar vs. Vector
578 (2+964) vs. 321 (1+564) ops (1.8X) 578 (2+964) vs. 6 instructions (96X) 64 operation vectors + no loop overhead also 64X fewer pipeline hazards*
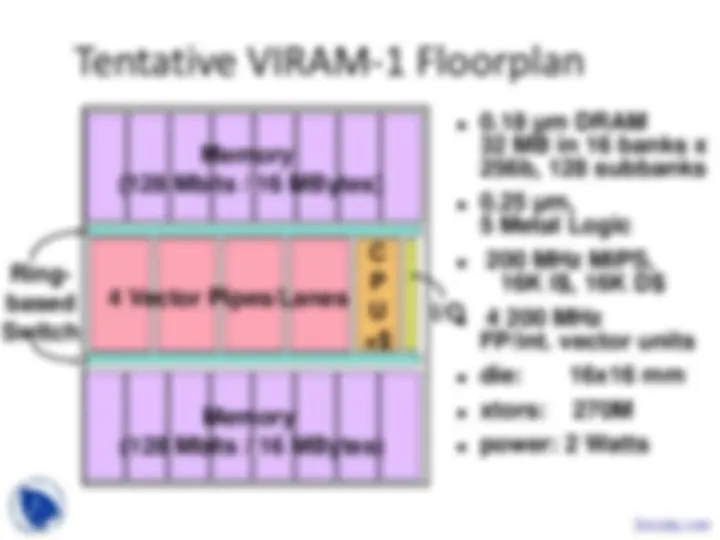
Example Vector Machines
Vector Surprise
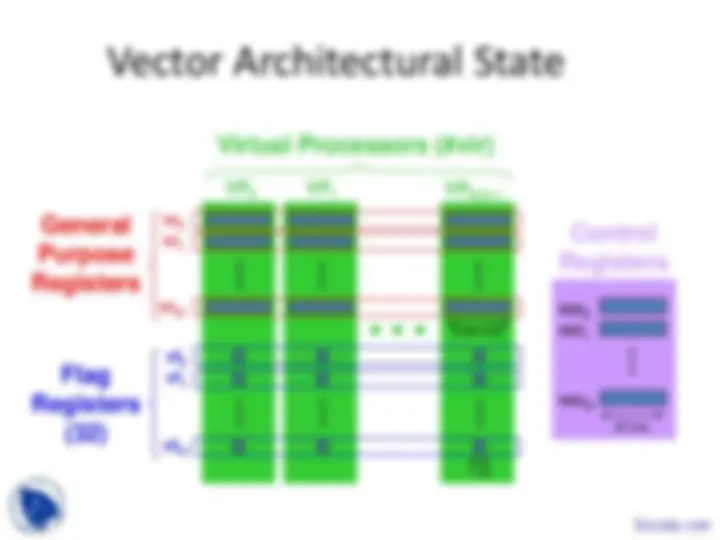
Virtual Processor Vector Model