



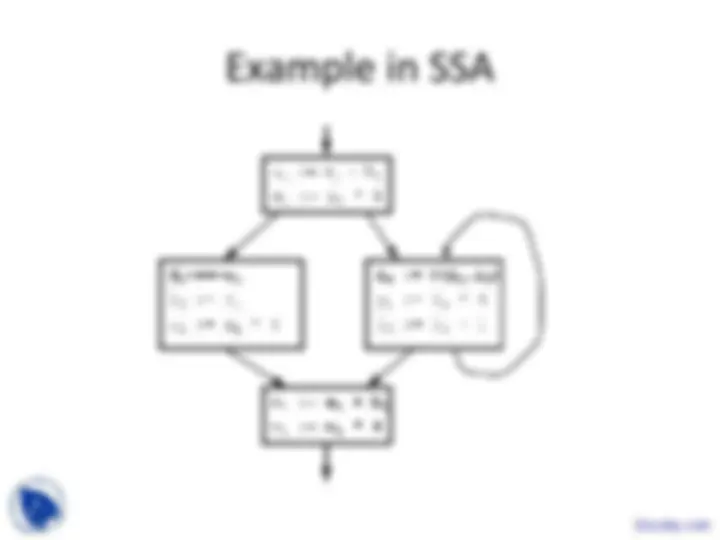
Program Representations
Docsity.com




















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
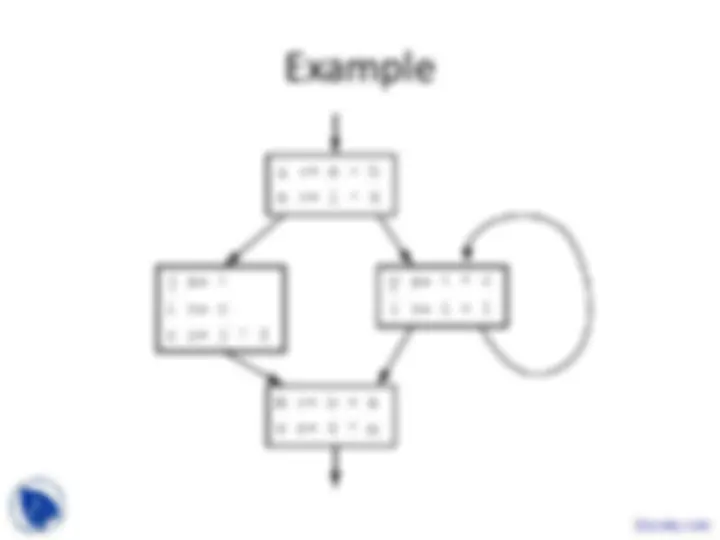
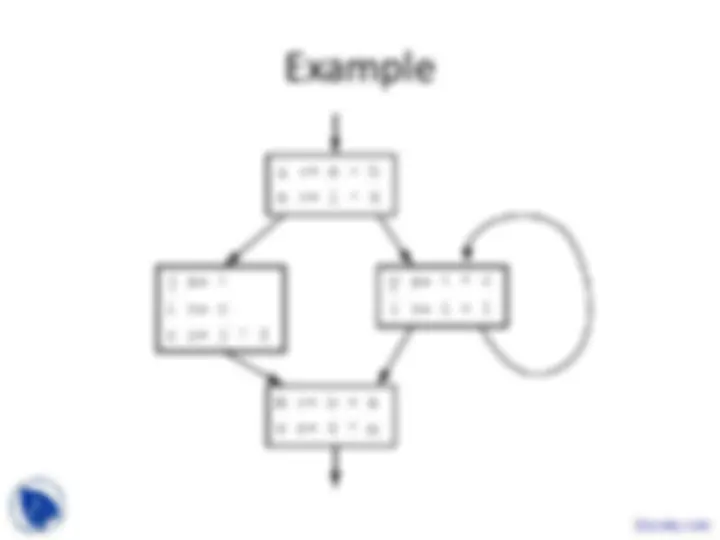
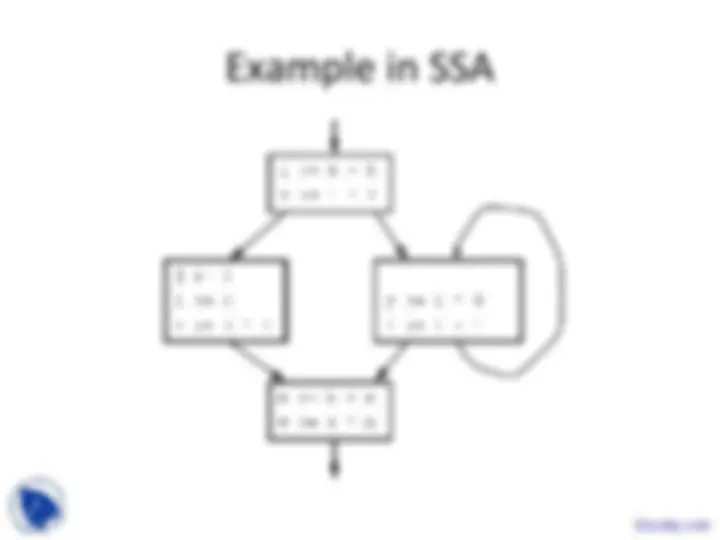
These are the Lecture Slides of Advanced Compiler which includes Partial Transfer Functions, Input Information, Output Information, Data-Based Context Sensitivity, Bottom-Up Example, Infinite Domains, Interprocedural Analysis etc. Key important points are: Program Representations, Input Languages, Typed Binaries, Source-Level Debugging, High-Level Syntax, Abstract Syntax Tree, Translate Input Programs, Assembly Code, Virtual Machine Code
Typology: Slides
1 / 32

This page cannot be seen from the preview
Don't miss anything!
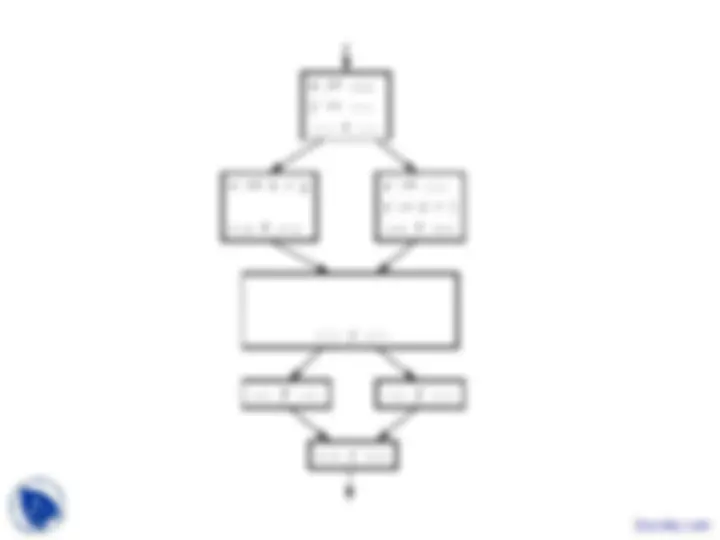
X := Y op Z
in
out
FX := Y op Z (in) =
X := Y
in
out
FX := Y(in) =