Download Protein Structure and Function: From Folding to Regulation and more Lecture notes Biology in PDF only on Docsity!
Electron density map of the F 1 -ATPase associated with a ring of 10 c-subunits from the F 0 domain of ATP synthase, a molecular machine that carries out the synthesis of ATP in eubacteria, chloroplasts, and mitochondria. [Courtesy of Andrew Leslie, MRC Laboratory of Molecular Biology, Cambridge, UK.]
PROTEIN STRUCTURE
AND FUNCTION
P
roteins, the working molecules of a cell, carry out the program of activities encoded by genes. This program requires the coordinated effort of many different types of proteins, which first evolved as rudimentary molecules that facilitated a limited number of chemical reactions. Grad- ually, many of these primitive proteins evolved into a wide array of enzymes capable of catalyzing an incredible range of intracellular and extracellular chemical reactions, with a speed and specificity that is nearly impossible to attain in a test tube. With the passage of time, other proteins acquired specialized abilities and can be grouped into several broad functional classes: structural proteins, which provide struc- tural rigidity to the cell; transport proteins, which control the flow of materials across cellular membranes; regulatory pro- teins, which act as sensors and switches to control protein activity and gene function; signaling proteins, including cell- surface receptors and other proteins that transmit external signals to the cell interior; and motor proteins, which cause motion. A key to understanding the functional design of proteins is the realization that many have “moving” parts and are ca- pable of transmitting various forces and energy in an orderly fashion. However, several critical and complex cell processes—synthesis of nucleic acids and proteins, signal transduction, and photosynthesis—are carried out by huge
macromolecular assemblies sometimes referred to as molec- ular machines. A fundamental goal of molecular cell biologists is to un- derstand how cells carry out various processes essential for life. A major contribution toward achieving this goal is the identification of all of an organism’s proteins—that is, a list of the parts that compose the cellular machinery. The com- pilation of such lists has become feasible in recent years with the sequencing of entire genomes —complete sets of genes— of more and more organisms. From a computer analysis of
O U T L I N E
3.1 Hierarchical Structure of Proteins
3.2 Folding, Modification, and Degradation
of Proteins
3.3 Enzymes and the Chemical Work of Cells
3.4 Molecular Motors and the Mechanical Work
of Cells
3.5 Common Mechanisms for Regulating Protein
Function
3.6 Purifying, Detecting, and Characterizing Proteins
60 CHAPTER 3 •^ Protein Structure and Function
genome sequences, researchers can deduce the number and primary structure of the encoded proteins (Chapter 9). The term proteome was coined to refer to the entire protein com- plement of an organism. For example, the proteome of the yeast Saccharomyces cerevisiae consists of about 6000 dif- ferent proteins; the human proteome is only about five times as large, comprising about 32,000 different proteins. By comparing protein sequences and structures, scientists can classify many proteins in an organism’s proteome and deduce their functions by homology with proteins of known func- tion. Although the three-dimensional structures of relatively few proteins are known, the function of a protein whose structure has not been determined can often be inferred from its interactions with other proteins, from the effects result-
ing from genetically mutating it, from the biochemistry of the complex to which it belongs, or from all three. In this chapter, we begin our study of how the structure of a protein gives rise to its function, a theme that recurs throughout this book (Figure 3-1). The first section examines how chains of amino acid building blocks are arranged and the various higher-order folded forms that the chains assume. The next section deals with special proteins that aid in the folding of proteins, modifications that take place after the protein chain has been synthesized, and mechanisms that de- grade proteins. The third section focuses on proteins as cat- alysts and reviews the basic properties exhibited by all enzymes. We then introduce molecular motors, which con- vert chemical energy into motion. The structure and function of these functional classes of proteins and others are detailed in numerous later chapters. Various mechanisms that cells use to control the activity of proteins are covered next. The chapter concludes with a section on commonly used tech- niques in the biologist’s tool kit for isolating proteins and characterizing their properties.
Hierarchical Structure of Proteins Although constructed by the polymerization of only 20 dif- ferent amino acids into linear chains, proteins carry out an incredible array of diverse tasks. A protein chain folds into a unique shape that is stabilized by noncovalent interactions between regions in the linear sequence of amino acids. This spatial organization of a protein—its shape in three dimen- sions—is a key to understanding its function. Only when a protein is in its correct three-dimensional structure, or con- formation, is it able to function efficiently. A key concept in understanding how proteins work is that function is derived from three-dimensional structure, and three-dimensional structure is specified by amino acid sequence. Here, we con- sider the structure of proteins at four levels of organization, starting with their monomeric building blocks, the amino acids.
The Primary Structure of a Protein Is Its Linear Arrangement of Amino Acids We reviewed the properties of the amino acids used in syn- thesizing proteins and their linkage by peptide bonds into lin- ear chains in Chapter 2. The repeated amide N, � carbon (C�), and carbonyl C atoms of each amino acid residue form the backbone of a protein molecule from which the various side-chain groups project (Figure 3-2). As a consequence of the peptide linkage, the backbone exhibits directionality be- cause all the amino groups are located on the same side of the C� atoms. Thus one end of a protein has a free (unlinked) amino group (the N-terminus ) and the other end has a free carboxyl group (the C-terminus ). The sequence of a protein chain is conventionally written with its N-terminal amino acid on the left and its C-terminal amino acid on the right.
3.
60 CHAPTER 3 •^ Protein Structure and Function
MOLECULAR STRUCTURE Primary (sequence)
Secondary (local folding)
Tertiary (long-range folding)
Quaternary (multimeric organization)
FUNCTION
Signaling
Catalysis
Structure
Movement
Regulation
Transport
Supramolecular (large-scale assemblies)
"on"
"off"
A
B
(a)
(b)
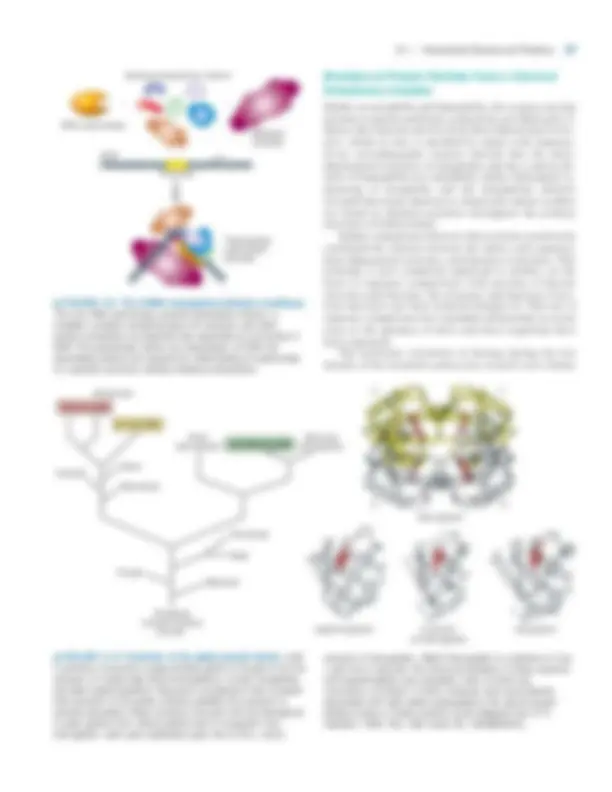
▲ FIGURE 3-1 Overview of protein structure and function. (a) The linear sequence of amino acids (primary structure) folds into helices or sheets (secondary structure) which pack into a globular or fibrous domain (tertiary structure). Some individual proteins self-associate into complexes (quaternary structure) that can consist of tens to hundreds of subunits (supramolecular assemblies). (b) Proteins display functions that include catalysis of chemical reactions (enzymes), flow of small molecules and ions (transport), sensing and reaction to the environment (signaling), control of protein activity (regulation), organization of the genome, lipid bilayer membrane, and cytoplasm (structure), and generation of force for movement (motor proteins). These functions and others arise from specific binding interactions and conformational changes in the structure of a properly folded protein.
62 CHAPTER 3 •^ Protein Structure and Function
The stable arrangement of amino acids in the � helix holds the backbone in a rodlike cylinder from which the side chains point outward. The hydrophobic or hydrophilic quality of the helix is determined entirely by the side chains because the polar groups of the peptide backbone are already engaged in hydrogen bonding in the helix.
The � Sheet Another type of secondary structure, the � sheet,
consists of laterally packed � strands. Each � strand is a short (5- to 8-residue), nearly fully extended polypeptide segment. Hydrogen bonding between backbone atoms in adjacent � strands, within either the same polypeptide chain or between different polypeptide chains, forms a � sheet (Figure 3-4a). The planarity of the peptide bond forces a � sheet to be pleated; hence this structure is also called a � pleated sheet, or simply a pleated sheet. Like � helices, � strands have a directionality de- fined by the orientation of the peptide bond. Therefore, in a pleated sheet, adjacent � strands can be oriented in the same (parallel) or opposite (antiparallel) directions with respect to each other. In both arrangements, the side chains project from both faces of the sheet (Figure 3-4b). In some proteins, � sheets form the floor of a binding pocket; the hydrophobic core of other proteins contains multiple � sheets.
Turns Composed of three or four residues, turns are located
on the surface of a protein, forming sharp bends that redirect the polypeptide backbone back toward the interior. These short, U-shaped secondary structures are stabilized by a hy- drogen bond between their end residues (see Figure 3-4a). Glycine and proline are commonly present in turns. The lack of a large side chain in glycine and the presence of a built-in bend in proline allow the polypeptide backbone to fold into a tight U shape. Turns allow large proteins to fold into highly compact structures. A polypeptide backbone also may con- tain longer bends, or loops. In contrast with turns, which ex-
hibit just a few well-defined structures, loops can be formed in many different ways.
Overall Folding of a Polypeptide Chain Yields Its Tertiary Structure Tertiary structure refers to the overall conformation of a polypeptide chain—that is, the three-dimensional arrange- ment of all its amino acid residues. In contrast with second- ary structures, which are stabilized by hydrogen bonds, tertiary structure is primarily stabilized by hydrophobic in- teractions between the nonpolar side chains, hydrogen bonds between polar side chains, and peptide bonds. These stabi- lizing forces hold elements of secondary structure—� helices, � strands, turns, and random coils—compactly together. Because the stabilizing interactions are weak, however, the tertiary structure of a protein is not rigidly fixed but under- goes continual and minute fluctuation. This variation in structure has important consequences in the function and regulation of proteins. Different ways of depicting the conformation of proteins convey different types of information. The simplest way to represent three-dimensional structure is to trace the course of the backbone atoms with a solid line (Figure 3-5a); the most complex model shows every atom (Figure 3-5b). The former, a C� trace, shows the overall organization of the polypeptide chain without consideration of the amino acid side chains; the latter, a ball-and-stick model, details the interactions be- tween side-chain atoms, which stabilize the protein’s confor- mation, as well as the atoms of the backbone. Even though both views are useful, the elements of secondary structure are not easily discerned in them. Another type of representation uses common shorthand symbols for depicting secondary structure—for example, coiled ribbons or solid cylinders for � helices, flat ribbons or arrows for � strands, and flexible
(a)
R R (^) R R
R R R
R
R R R
R
R R^
R
R R
R
R
R
R
R
R
R
R
R R
(b)
� FIGURE 3-4^ The^ �^ sheet, another common secondary structure in proteins. (a) Top view of a simple two-stranded � sheet with antiparallel � strands. The stabilizing hydrogen bonds between the � strands are indicated by green dashed lines. The short turn between the � strands also is stabilized by a hydrogen bond. (b) Side view of a � sheet. The projection of the R groups (green) above and below the plane of the sheet is obvious in this view. The fixed angle of the peptide bond produces a pleated contour.
thin strands for turns and loops (Figure 3-5c). This type of representation makes the secondary structures of a protein easy to see. However, none of these three ways of representing pro- tein structure convey much information about the protein surface, which is of interest because it is where other mole- cules bind to a protein. Computer analysis can identify the surface atoms that are in contact with the watery environ- ment. On this water-accessible surface, regions having a common chemical character (hydrophobicity or hydrophilic- ity) and electrical character (basic or acidic) can be mapped. Such models reveal the topography of the protein surface and the distribution of charge, both important features of bind- ing sites, as well as clefts in the surface where small mole- cules often bind (Figure 3-5d). This view represents a protein as it is “seen” by another molecule.
Motifs Are Regular Combinations of Secondary Structures Particular combinations of secondary structures, called mo- tifs or folds, build up the tertiary structure of a protein. In some cases, motifs are signatures for a specific function. For example, the helix-loop-helix is a Ca 2 �-binding motif marked by the presence of certain hydrophilic residues at in- variant positions in the loop (Figure 3-6a). Oxygen atoms in
the invariant residues bind a Ca^2 �^ ion through ionic bonds. This motif, also called the EF hand, has been found in more than 100 calcium-binding proteins. In another common motif, the zinc finger, three secondary structures—an � helix and two � strands with an antiparallel orientation—form a fingerlike bundle held together by a zinc ion (Figure 3-6b). This motif is most commonly found in proteins that bind RNA or DNA. Many proteins, especially fibrous proteins, self-associate into oligomers by using a third motif, the coiled coil. In these proteins, each polypeptide chain contains �-helical segments in which the hydrophobic residues, although apparently randomly arranged, are in a regular pattern—a repeated heptad sequence. In the heptad, a hydrophobic residue— sometimes valine, alanine, or methionine—is at position 1 and a leucine residue is at position 4. Because hydrophilic side chains extend from one side of the helix and hydropho- bic side chains extend from the opposite side, the overall hel- ical structure is amphipathic. The amphipathic character of these � helices permits two, three, or four helices to wind around each other, forming a coiled coil; hence the name of this motif (Figure 3-6c). We will encounter numerous additional motifs in later discussions of other proteins in this chapter and other chap- ters. The presence of the same motif in different proteins with similar functions clearly indicates that these useful
3.1 •^ Hierarchical Structure of Proteins 63
(a) Cα backbone trace (b) Ball and stick
(c) Ribbons (d) Solvent-accessible surface
� FIGURE 3-5^ Various graphic representations of the structure of Ras, a monomeric guanine nucleotide-binding protein. The inactive, guanosine diphosphate (GDP)–bound form is shown in all four panels, with GDP always depicted in blue spacefill. (a) The C� backbone trace demonstrates how the polypeptide is packed into the smallest possible volume. (b) A ball-and-stick representation reveals the location of all atoms. (c) A ribbon representation emphasizes how � strands (blue) and � helices (red) are organized in the protein. Note the turns and loops connecting pairs of helices and strands. (d) A model of the water-accessible surface reveals the numerous lumps, bumps, and crevices on the protein surface. Regions of positive charge are shaded blue; regions of negative charge are shaded red.
subjected to mutagenesis so that segments of the protein’s backbone are removed or changed. The activity of the trun- cated or altered protein product synthesized from the mu- tated gene is then monitored and serves as a source of insight about which part of a protein is critical to its function. The organization of large proteins into multiple do- mains illustrates the principle that complex molecules are built from simpler components. Like motifs of secondary structure, domains of tertiary structure are incorporated as modules into different proteins. In Chapter 10 we consider the mechanism by which the gene segments that correspond to domains became shuffled in the course of evolution, re- sulting in their appearance in many proteins. The modular approach to protein architecture is particularly easy to rec- ognize in large proteins, which tend to be mosaics of dif- ferent domains and thus can perform different functions simultaneously. The epidermal growth factor (EGF) domain is one exam- ple of a module that is present in several proteins (Figure 3-8). EGF is a small, soluble peptide hormone that binds to cells in the embryo and in skin and connective tissue in adults, caus- ing them to divide. It is generated by proteolytic cleavage be- tween repeated EGF domains in the EGF precursor protein, which is anchored in the cell membrane by a membrane- spanning domain. EGF modules are also present in other proteins and are liberated by proteolysis; these proteins in- clude tissue plasminogen activator (TPA), a protease that is used to dissolve blood clots in heart attack victims;
Neu protein, which takes part in embryonic differentiation; and Notch protein, a receptor protein in the plasma mem- brane that functions in developmentally important signaling (Chapter 14). Besides the EGF domain, these proteins con- tain domains found in other proteins. For example, TPA pos- sesses a trypsin domain, a common feature in enzymes that degrade proteins.
3.1 •^ Hierarchical Structure of Proteins 65
PROXIMAL
C
HA (^1)
N
HA 2
N
Globular domain
Fibrous domain
DISTAL
(a)
Viral membrane
(b) Sialic acid^ � FIGURE 3-7^ Tertiary and quaternary levels of structure in hemagglutinin (HA), a surface protein on influenza virus. This long multimeric molecule has three identical subunits, each composed of two polypeptide chains, HA 1 and HA 2. (a) Tertiary structure of each HA subunit constitutes the folding of its helices and strands into a compact structure that is 13.5 nm long and divided into two domains. The membrane-distal domain is folded into a globular conformation. The membrane-proximal domain has a fibrous, stemlike conformation owing to the alignment of two long � helices (cylinders) of HA 2 with � strands in HA 1. Short turns and longer loops, which usually lie at the surface of the molecule, connect the helices and strands in a given chain. (b) Quaternary structure of HA is stabilized by lateral interactions between the long helices (cylinders) in the fibrous domains of the three subunits (yellow, blue, and green), forming a triple-stranded coiled- coil stalk. Each of the distal globular domains in HA binds sialic acid (red) on the surface of target cells. Like many membrane proteins, HA contains several covalently linked carbohydrate chains (not shown).
EGF
Neu
TPA
EGF precursor
▲ FIGURE 3-8 Schematic diagrams of various proteins illustrating their modular nature. Epidermal growth factor (EGF) is generated by proteolytic cleavage of a precursor protein containing multiple EGF domains (green) and a membrane- spanning domain (blue). The EGF domain is also present in Neu protein and in tissue plasminogen activator (TPA). These proteins also contain other widely distributed domains indicated by shape and color. [Adapted from I. D. Campbell and P. Bork, 1993, Curr. Opin. Struct. Biol. 3 :385.]
66 CHAPTER 3 •^ Protein Structure and Function
Proteins Associate into Multimeric Structures
and Macromolecular Assemblies
Multimeric proteins consist of two or more polypeptides or subunits. A fourth level of structural organization, quaternary structure, describes the number (stoichiometry) and relative positions of the subunits in multimeric proteins. Hemagglu- tinin, for example, is a trimer of three identical subunits held together by noncovalent bonds (Figure 3-7b). Other multi- meric proteins can be composed of any number of identical or different subunits. The multimeric nature of many proteins is critical to mechanisms for regulating their function. In ad- dition, enzymes in the same pathway may be associated as subunits of a large multimeric protein within the cell, thereby increasing the efficiency of pathway operation. The highest level of protein structure is the association of proteins into macromolecular assemblies. Typically, such structures are very large, exceeding 1 mDa in mass, ap- proaching 30–300 nm in size, and containing tens to hun- dreds of polypeptide chains, as well as nucleic acids in some
cases. Macromolecular assemblies with a structural function include the capsid that encases the viral genome and bundles of cytoskeletal filaments that support and give shape to the plasma membrane. Other macromolecular assemblies act as molecular machines, carrying out the most complex cellular processes by integrating individual functions into one coor- dinated process. For example, the transcriptional machine that initiates the synthesis of messenger RNA (mRNA) con- sists of RNA polymerase, itself a multimeric protein, and at least 50 additional components including general transcrip- tion factors, promoter-binding proteins, helicase, and other protein complexes (Figure 3-9). The transcription factors and promoter-binding proteins correctly position a poly- merase molecule at a promoter, the DNA site that determines where transcription of a specific gene begins. After helicase unwinds the double-stranded DNA molecule, polymerase si- multaneously translocates along the DNA template strand and synthesizes an mRNA strand. The operational details of this complex machine and of others listed in Table 3-1 are discussed elsewhere.
TABLE 3-1 Selected Molecular Machines
Machine*^ Main Components Cellular Location Function
Replisome (4) Helicase, primase, DNA polymerase Nucleus DNA replication Transcription initiation Promoter-binding protein, helicase, Nucleus RNA synthesis complex (11) general transcription factors (TFs), RNA polymerase, large multisubunit mediator complex Spliceosome (12) Pre-mRNA, small nuclear RNAs Nucleus mRNA splicing (snRNAs), protein factors Nuclear pore Nucleoporins (50–100) Nuclear membrane Nuclear import complex (12) and export Ribosome (4) Ribosomal proteins (�50) and four Cytoplasm/ER membrane Protein synthesis rRNA molecules (eukaryotes) organized into large and small subunits; associated mRNA and protein factors (IFs, EFs) Chaperonin (3) GroEL, GroES (bacteria) Cytoplasm, Protein folding mitochondria, endoplasmic reticulum Proteasome (3) Core proteins, regulatory (cap) proteins Cytoplasm Protein degradation Photosystem (8) Light-harvesting complex (multiple Thylakoid membrane Photosynthesis proteins and pigments), reaction center in plant chloroplasts, (initial stage) (multisubunit protein with associated plasma membrane of pigments and electron carriers) photosynthetic bacteria MAP kinase Scaffold protein, multiple different Cytoplasm Signal transduction cascades (14) protein kinases Sarcomere (19) Thick (myosin) filaments, thin (actin) Cytoplasm of Contraction filaments, Z lines, titin/nebulin muscle cells *Numbers in parentheses indicate chapters in which various machines are discussed.
68 CHAPTER 3 •^ Protein Structure and Function
of biological classification based on similarities and differ- ences in the amino acid sequences of proteins. Proteins that have a common ancestor are referred to as homologs. The main evidence for homology among proteins, and hence their common ancestry, is similarity in their sequences or structures. We can therefore describe homologous proteins as belonging to a “family” and can trace their lineage from comparisons of their sequences. The folded three-dimen- sional structures of homologous proteins are similar even if parts of their primary structure show little evidence of homology. The kinship among homologous proteins is most easily visualized by a tree diagram based on sequence analyses. For example, the amino acid sequences of globins from bacteria, plants, and animals suggest that they evolved from an an- cestral monomeric, oxygen-binding protein (Figure 3-10). With the passage of time, the gene for this ancestral protein slowly changed, initially diverging into lineages leading to animal and plant globins. Subsequent changes gave rise to myoglobin, a monomeric oxygen-storing protein in muscle, and to the � and � subunits of the tetrameric hemoglobin molecule (� 2 � 2 ) of the circulatory system.
KEY CONCEPTS OF SECTION 3.
Hierarchical Structure of Proteins
■ A protein is a linear polymer of amino acids linked together by peptide bonds. Various, mostly noncovalent, interactions between amino acids in the linear sequence stabilize a specific folded three-dimensional structure (con- formation) for each protein. ■ The � helix, � strand and sheet, and turn are the most prevalent elements of protein secondary structure, which is stabilized by hydrogen bonds between atoms of the pep- tide backbone. ■ Certain combinations of secondary structures give rise to different motifs, which are found in a variety of pro- teins and are often associated with specific functions (see Figure 3-6). ■ Protein tertiary structure results from hydrophobic in- teractions between nonpolar side groups and hydrogen bonds between polar side groups that stabilize folding of the secondary structure into a compact overall arrange- ment, or conformation. ■ Large proteins often contain distinct domains, independ- ently folded regions of tertiary structure with characteristic structural or functional properties or both (see Figure 3-7). ■ The incorporation of domains as modules in different proteins in the course of evolution has generated diversity in protein structure and function. ■ Quaternary structure encompasses the number and or- ganization of subunits in multimeric proteins.
■ Cells contain large macromolecular assemblies in which all the necessary participants in complex cellular processes (e.g., DNA, RNA, and protein synthesis; photosynthesis; signal transduction) are integrated to form molecular ma- chines (see Table 3-1). ■ The sequence of a protein determines its three-dimensional structure, which determines its function. In short, function derives from structure; structure derives from sequence. ■ Homologous proteins, which have similar sequences, structures, and functions, evolved from a common ancestor.
Folding, Modification, and Degradation of Proteins A polypeptide chain is synthesized by a complex process called translation in which the assembly of amino acids in a particu- lar sequence is dictated by messenger RNA (mRNA). The in- tricacies of translation are considered in Chapter 4. Here, we describe how the cell promotes the proper folding of a na- scent polypeptide chain and, in many cases, modifies residues or cleaves the polypeptide backbone to generate the final pro- tein. In addition, the cell has error-checking processes that eliminate incorrectly synthesized or folded proteins. Incor- rectly folded proteins usually lack biological activity and, in some cases, may actually be associated with disease. Protein misfolding is suppressed by two distinct mechanisms. First, cells have systems that reduce the chances for misfolded pro- teins to form. Second, any misfolded proteins that do form, as well as cytosolic proteins no longer needed by a cell, are de- graded by a specialized cellular garbage-disposal system.
The Information for Protein Folding Is Encoded in the Sequence Any polypeptide chain containing n residues could, in prin- ciple, fold into 8 n^ conformations. This value is based on the fact that only eight bond angles are stereochemically allowed in the polypeptide backbone. In general, however, all mole- cules of any protein species adopt a single conformation, called the native state; for the vast majority of proteins, the native state is the most stably folded form of the molecule. What guides proteins to their native folded state? The an- swer to this question initially came from in vitro studies on protein refolding. Thermal energy from heat, extremes of pH that alter the charges on amino acid side chains, and chemi- cals such as urea or guanidine hydrochloride at concentra- tions of 6–8 M can disrupt the weak noncovalent interactions that stabilize the native conformation of a protein. The denaturation resulting from such treatment causes a protein to lose both its native conformation and its biological activity. Many proteins that are completely unfolded in 8 M urea and � - mercaptoethanol (which reduces disulfide bonds) spon- taneously renature (refold) into their native states when the de- naturing reagents are removed by dialysis. Because no cofactors
3.
or other proteins are required, in vitro protein folding is a self- directed process. In other words, sufficient information must be contained in the protein’s primary sequence to direct cor- rect refolding. The observed similarity in the folded, three- dimensional structures of proteins with similar amino acid sequences, noted in Section 3.1, provided other evidence that the primary sequence also determines protein folding in vivo.
Folding of Proteins in Vivo Is Promoted
by Chaperones
Although protein folding occurs in vitro, only a minority of unfolded molecules undergo complete folding into the native conformation within a few minutes. Clearly, cells require a faster, more efficient mechanism for folding proteins into their correct shapes; otherwise, cells would waste much en- ergy in the synthesis of nonfunctional proteins and in the degradation of misfolded or unfolded proteins. Indeed, more than 95 percent of the proteins present within cells have been shown to be in their native conformation, despite high pro- tein concentrations (200–300 mg/ml), which favor the pre- cipitation of proteins in vitro. The explanation for the cell’s remarkable efficiency in promoting protein folding probably lies in chaperones, a
class of proteins found in all organisms from bacteria to hu- mans. Chaperones are located in every cellular compartment, bind a wide range of proteins, and function in the general protein-folding mechanism of cells. Two general families of chaperones are reconized: ■ (^) Molecular chaperones, which bind and stabilize un- folded or partly folded proteins, thereby preventing these proteins from aggregating and being degraded ■ (^) Chaperonins, which directly facilitate the folding of proteins Molecular chaperones consist of Hsp70 and its homologs: Hsp70 in the cytosol and mitochondrial matrix, BiP in the en- doplasmic reticulum, and DnaK in bacteria. First identified by their rapid appearance after a cell has been stressed by heat shock, Hsp70 and its homologs are the major chaperones in all organisms. (Hsc70 is a constitutively expressed homolog of Hsp70.) When bound to ATP, Hsp70-like proteins assume an open form in which an exposed hydrophobic pocket tran- siently binds to exposed hydrophobic regions of the unfolded target protein. Hydrolysis of the bound ATP causes molecu- lar chaperones to assume a closed form in which a target pro- tein can undergo folding. The exchange of ATP for ADP releases the target protein (Figure 3-11a, top ). This cycle is
3.2 •^ Folding, Modification, and Degradation of Proteins 69
(a) Ribosome
Partially folded protein
ATP
ADP
(b)
GroEL "tight" conformation
GroEL "relaxed" GroEL^ conformation
GroES
ADP
Pi
Properly folded protein
Properly folded protein
Protein
Protein
P (^) i
Hsp 70-ATP ATP
▲ FIGURE 3-11 Chaperone- and chaperonin-mediated protein folding. (a) Many proteins fold into their proper three- dimensional structures with the assistance of Hsp70-like proteins ( top ). These molecular chaperones transiently bind to a nascent polypeptide as it emerges from a ribosome. Proper folding of other proteins ( bottom ) depends on chaperonins such as the prokaryotic GroEL, a hollow, barrel-shaped complex of 14 identical 60,000-MW subunits arranged in two stacked rings.
One end of GroEL is transiently blocked by the co- chaperonin GroES, an assembly of 10,000-MW subunits. (b) In the absence of ATP or presence of ADP, GroEL exists in a “tight” conformational state that binds partly folded or misfolded proteins. Binding of ATP shifts GroEL to a more open, “relaxed” state , which releases the folded protein. See text for details. [Part (b) from A. Roseman et al., 1996, Cell 87 :241; courtesy of H. Saibil.]
M E D I A
C O N N E C T I O N S
Focus Animation: Chaperone-Mediated Folding
polypeptide chain. Proteolytic cleavage is a common mecha- nism for activating enzymes that function in blood coagula- tion, digestion, and programmed cell death (Chapter 22). Proteolysis also generates active peptide hormones, such as EGF and insulin, from larger precursor polypeptides. An unusual and rare type of processing, termed protein self-splicing, takes place in bacteria and some eukaryotes. This process is analogous to editing film: an internal segment of a polypeptide is removed and the ends of the polypeptide are rejoined. Unlike proteolytic processing, protein self- splicing is an autocatalytic process, which proceeds by itself without the participation of enzymes. The excised peptide appears to eliminate itself from the protein by a mechanism similar to that used in the processing of some RNA mole- cules (Chapter 12). In vertebrate cells, the processing of some proteins includes self-cleavage, but the subsequent ligation step is absent. One such protein is Hedgehog, a membrane- bound signaling molecule that is critical to a number of de- velopmental processes (Chapter 15).
Ubiquitin Marks Cytosolic Proteins
for Degradation in Proteasomes
In addition to chemical modifications and processing, the ac- tivity of a cellular protein depends on the amount present, which reflects the balance between its rate of synthesis and rate of degradation in the cell. The numerous ways that cells regulate protein synthesis are discussed in later chapters. In this section, we examine protein degradation, focusing on the major pathways for degrading cytosolic proteins. The life span of intracellular proteins varies from as short as a few minutes for mitotic cyclins, which help regulate pas- sage through mitosis, to as long as the age of an organism for proteins in the lens of the eye. Eukaryotic cells have several intracellular proteolytic pathways for degrading misfolded or denatured proteins, normal proteins whose concentration must be decreased, and extracellular proteins taken up by the cell. One major intracellular pathway is degradation by en- zymes within lysosomes, membrane-limited organelles whose acidic interior is filled with hydrolytic enzymes. Lysosomal degradation is directed primarily toward extracellular pro- teins taken up by the cell and aged or defective organelles of the cell (see Figure 5-20). Distinct from the lysosomal pathway are cytosolic mecha- nisms for degrading proteins. Chief among these mechanisms is a pathway that includes the chemical modification of a ly- sine side chain by the addition of ubiquitin, a 76-residue polypeptide, followed by degradation of the ubiquitin-tagged protein by a specialized proteolytic machine. Ubiquitination is a three-step process (Figure 3-13a):
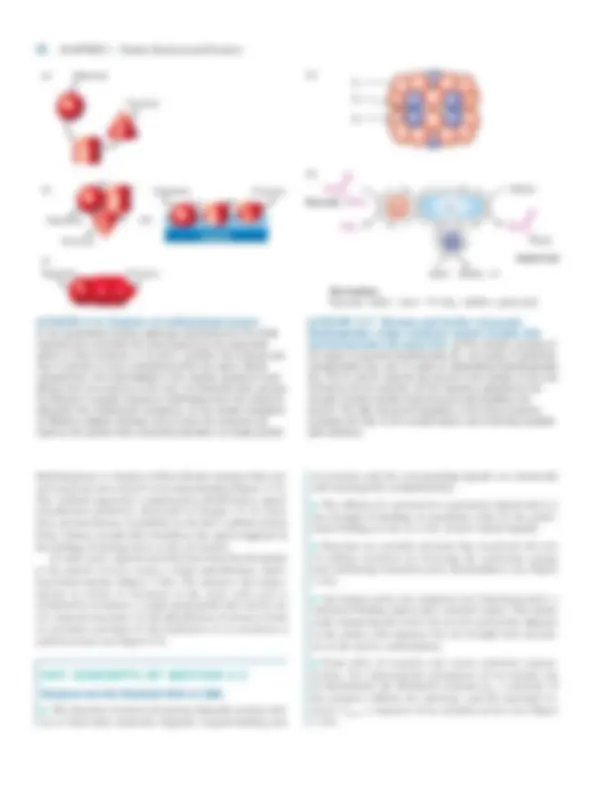
■ Activation of ubiquitin-activating enzyme (E1) by the addition of a ubitiquin molecule, a reaction that requires ATP
■ Transfer of this ubiquitin molecule to a cysteine residue in ubiquitin-conjugating enzyme (E2)
■ Formation of a peptide bond between the ubiquitin molecule bound to E2 and a lysine residue in the target protein, a reaction catalyzed by ubiquitin ligase (E3) This process is repeated many times, with each subsequent ubiquitin molecule being added to the preceding one. The re- sulting polyubiquitin chain is recognized by a proteasome, another of the cell’s molecular machines (Figure 3-13b). The numerous proteasomes dispersed throughout the cell cytosol proteolytically cleave ubiquitin-tagged proteins in an ATP- dependent process that yields short (7- to 8-residue) peptides and intact ubiquitin molecules.
3.2 •^ Folding, Modification, and Degradation of Proteins 71
(a)
Cytosolic target protein
Ub
Ub Ub Ubn
NH 2
Ub Ub
Ub
Proteasome
Peptides
Ub
E1 Ub^ Ub
E C O
E
AMP
E E
(^1 2 )
4
5
Steps 1, 2, 3 (n times) (b)
Cap
Core
Cap
E1 = Ubiquitin-activating enzyme E2 = Ubiquitin-conjugating enzyme E3 = Ubiquitin ligase Ub = Ubiquitin
ATP ADP
C
O NH
▲ FIGURE 3-13 Ubiquitin-mediated proteolytic pathway. (a) Enzyme E1 is activated by attachment of a ubiquitin (Ub) molecule (step ) and then transfers this Ub molecule to E2 (step ). Ubiquitin ligase (E3) transfers the bound Ub molecule on E2 to the side-chain —NH 2 of a lysine residue in a target protein (step ). Additional Ub molecules are added to the target protein by repeating steps – , forming a polyubiquitin chain that directs the tagged protein to a proteasome (step ). Within this large complex, the protein is cleaved into numerous small peptide fragments (step ). (b) Computer-generated image reveals that a proteasome has a cylindrical structure with a cap at each end of a core region. Proteolysis of ubiquitin-tagged proteins occurs along the inner wall of the core. [Part (b) from W. Baumeister et al., 1998, Cell 92 :357; courtesy of W. Baumeister.]
5
4
1 3
3
2
1
M E D I A
C O N N E C T I O N S
Overview Animation: Life Cycle of a Protein
72 CHAPTER 3 •^ Protein Structure and Function
Cellular proteins degraded by the ubiquitin-mediated pathway fall into one of two general categories: (1) native cy- tosolic proteins whose life spans are tightly controlled and (2) proteins that become misfolded in the course of their syn- thesis in the endoplasmic reticulum (ER). Both contain se- quences recognized by the ubiquitinating enzyme complex. The cyclins, for example, are cytosolic proteins whose amounts are tightly controlled throughout the cell cycle. These proteins contain the internal sequence Arg-X-X-Leu- Gly-X-Ile-Gly-Asp/Asn (X can be any amino acid), which is recognized by specific ubiquitinating enzyme complexes. At a specific time in the cell cycle, each cyclin is phosphorylated by a cyclin kinase. This phosphorylation is thought to cause a conformational change that exposes the recognition se- quence to the ubiquitinating enzymes, leading to degradation of the tagged cyclin (Chapter 21). Similarly, the misfolding of proteins in the endoplasmic reticulum exposes hydrophobic sequences normally buried within the folded protein. Such proteins are transported to the cytosol, where ubiquitinat- ing enzymes recognize the exposed hydrophobic sequences. The immune system also makes use of the ubiquitin- mediated pathway in the response to altered self-cells, par- ticularly virus-infected cells. Viral proteins within the cytosol of infected cells are ubiquitinated and then degraded in pro- teasomes specially designed for this role. The resulting anti- genic peptides are transported to the endoplasmic reticulum, where they bind to class I major histocompatibility complex (MHC) molecules within the ER membrane. Subsequently, the peptide-MHC complexes move to the cell membrane where the antigenic peptides can be recognized by cytotoxic T lymphocytes, which mediate the destruction of the infected cells.
Digestive Proteases Degrade Dietary Proteins
The major extracellular pathway for protein degradation is the system of digestive proteases that breaks down ingested pro- teins into peptides and amino acids in the intestinal tract. Three classes of proteases function in digestion. Endoproteases attack selected peptide bonds within a polypeptide chain. The principal endoproteases are pepsin, which preferentially cleaves the backbone adjacent to phenylalanine and leucine residues, and trypsin and chymotrypsin, which cleave the backbone adjacent to basic and aromatic residues. Exopepti- dases sequentially remove residues from the N-terminus (aminopeptidases) or C-terminus (carboxypeptidases) of a protein. Peptidases split oligopeptides containing as many as about 20 amino acids into di- and tripeptides and individual amino acids. These small molecules are then transported across the intestinal lining into the bloodstream. To protect a cell from degrading itself, endoproteases and carboxypeptidases are synthesized and secreted as inactive forms (zymogens): pepsin by chief cells in the lining of the stomach; the others by pancreatic cells. Proteolytic cleavage of the zymogens within the gastic or intestinal lumen yields the active enzymes. Intestinal epithelial cells produce aminopeptidases and the di- and tripeptidases.
Alternatively Folded Proteins Are Implicated in Slowly Developing Diseases
As noted earlier, each protein species normally folds into a single, energetically favorable conformation that is specified by its amino acid sequence. Recent evidence suggests, however, that a protein may fold into an al- ternative three-dimensional structure as the result of muta- tions, inappropriate post-translational modification, or other as-yet-unidentified reasons. Such “misfolding” not only leads to a loss of the normal function of the protein but also marks it for proteolytic degradation. The subsequent accumulation of proteolytic fragments contributes to certain degenerative diseases characterized by the presence of insoluble protein plaques in various organs, including the liver and brain. ❚
Some neurodegenerative diseases, including Alzheimer’s disease and Parkinson’s disease in humans and transmissible spongiform encephalopathy (“mad cow” disease) in cows
20 �m
(a)
100 nm
(b)
▲ EXPERIMENTAL FIGURE 3-14 Alzheimer’s disease is characterized by the formation of insoluble plaques composed of amyloid protein. (a) At low resolution, an amyloid plaque in the brain of an Alzheimer’s patient appears as a tangle of filaments. (b) The regular structure of filaments from plaques is revealed in the atomic force microscope. Proteolysis of the naturally occurring amyloid precursor protein yields a short fragment, called �-amyloid protein, that for unknown reasons changes from an �-helical to a �-sheet conformation. This alternative structure aggregates into the highly stable filaments (amyloid) found in plaques. Similar pathologic changes in other proteins cause other degenerative diseases. [Courtesy of K. Kosik.]
74 CHAPTER 3 •^ Protein Structure and Function
(Figure 3-15b). The intimate contact between these two sur- faces, stabilized by numerous noncovalent bonds, is respon- sible for the exquisite binding specificity exhibited by an antibody. The specificity of antibodies is so precise that they can distinguish between the cells of individual members of a species and in some cases can distinguish between proteins that differ by only a single amino acid. Because of their speci- ficity and the ease with which they can be produced, anti- bodies are highly useful reagents in many of the experiments discussed in subsequent chapters.
Enzymes Are Highly Efficient and Specific
Catalysts
In contrast with antibodies, which bind and simply present their ligands to other components of the immune system, en- zymes promote the chemical alteration of their ligands, called substrates. Almost every chemical reaction in the cell is catalyzed by a specific enzyme. Like all catalysts, enzymes do not affect the extent of a reaction, which is determined by the change in free energy � G between reactants and products (Chapter 2). For reactions that are energetically favorable (�� G ), enzymes increase the reaction rate by lowering the activation energy (Figure 3-16). In the test tube, catalysts such as charcoal and platinum facilitate reactions but usually only at high temperatures or pressures, at extremes of high
or low pH, or in organic solvents. As the cell’s protein cata- lysts, however, enzymes must function effectively in aqueous environment at 37�C, 1 atmosphere pressure, and pH 6.5–7.5. Two striking properties of enzymes enable them to func- tion as catalysts under the mild conditions present in cells: their enormous catalytic power and their high degree of specificity. The immense catalytic power of enzymes causes the rates of enzymatically catalyzed reactions to be 10^6 –10 12 times that of the corresponding uncatalyzed reactions under otherwise similar conditions. The exquisite specificity of enzymes—their ability to act selectively on one substrate or a small number of chemically similar substrates —is exempli- fied by the enzymes that act on amino acids. As noted in Chapter 2, amino acids can exist as two stereoisomers, des- ignated L and D , although only L isomers are normally found in biological systems. Not surprisingly, enzyme-catalyzed re- actions of L -amino acids take place much more rapidly than do those of D -amino acids, even though both stereoisomers of a given amino acid are the same size and possess the same R groups (see Figure 2-12). Approximately 3700 different types of enzymes, each of which catalyzes a single chemical reaction or set of closely re- lated reactions, have been classified in the enzyme database. Certain enzymes are found in the majority of cells because they catalyze the synthesis of common cellular products (e.g., proteins, nucleic acids, and phospholipids) or take part in the
▲ FIGURE 3-15 Antibody structure and antibody-antigen interaction. (a) Ribbon model of an antibody. Every antibody molecule consists of two identical heavy chains (red) and two identical light chains (blue) covalently linked by disulfide bonds. (b) The hand-in-glove fit between an antibody and an epitope on its antigen—in this case, chicken egg-white lysozyme. Regions
where the two molecules make contact are shown as surfaces. The antibody contacts the antigen with residues from all its complementarity-determining regions (CDRs). In this view, the complementarity of the antigen and antibody is especially apparent where “fingers” extending from the antigen surface are opposed to “clefts” in the antibody surface.
production of energy by the conversion of glucose and oxy- gen into carbon dioxide and water. Other enzymes are pres- ent only in a particular type of cell because they catalyze chemical reactions unique to that cell type (e.g., the enzymes that convert tyrosine into dopamine, a neurotransmitter, in nerve cells). Although most enzymes are located within cells, some are secreted and function in extracellular sites such as the blood, the lumen of the digestive tract, or even outside the organism. The catalytic activity of some enzymes is critical to cellu- lar processes other than the synthesis or degradation of mole- cules. For instance, many regulatory proteins and intracellular signaling proteins catalyze the phosphorylation of proteins, and some transport proteins catalyze the hydrolysis of ATP coupled to the movement of molecules across membranes.
An Enzyme’s Active Site Binds Substrates
and Carries Out Catalysis
Certain amino acid side chains of an enzyme are important in determining its specificity and catalytic power. In the na- tive conformation of an enzyme, these side chains are brought into proximity, forming the active site. Active sites thus consist of two functionally important regions: one that recognizes and binds the substrate (or substrates) and an- other that catalyzes the reaction after the substrate has been
bound. In some enzymes, the catalytic region is part of the substrate-binding region; in others, the two regions are struc- turally as well as functionally distinct. To illustrate how the active site binds a specific substrate and then promotes a chemical change in the bound substrate, we examine the action of cyclic AMP–dependent protein ki- nase, now generally referred to as protein kinase A (PKA). This enzyme and other protein kinases, which add a phos- phate group to serine, threonine, or tyrosine residues in pro- teins, are critical for regulating the activity of many cellular proteins, often in response to external signals. Because the eukaryotic protein kinases belong to a common superfam- ily, the structure of the active site and mechanism of phos- phorylation are very similar in all of them. Thus protein kinase A can serve as a general model for this important class of enzymes. The active site of protein kinase A is located in the 240- residue “kinase core” of the catalytic subunit. The kinase core, which is largely conserved in all protein kinases, is re- sponsible for the binding of substrates (ATP and a target pep- tide sequence) and the subsequent transfer of a phosphate group from ATP to a serine, threonine, or tyrosine residue in the target sequence. The kinase core consists of a large do- main and small one, with an intervening deep cleft; the active site comprises residues located in both domains.
Substrate Binding by Protein Kinases The structure of the
ATP-binding site in the catalytic kinase core complements the structure of the nucleotide substrate. The adenine ring of ATP sits snugly at the base of the cleft between the large and the small domains. A highly conserved sequence, Gly-X-Gly-X- X-Gly-X-Val (X can be any amino acid), dubbed the “glycine lid,” closes over the adenine ring and holds it in position (Fig- ure 3-17a). Other conserved residues in the binding pocket stabilize the highly charged phosphate groups. Although ATP is a common substrate for all protein ki- nases, the sequence of the target peptide varies among dif- ferent kinases. The peptide sequence recognized by protein kinase A is Arg-Arg-X-Ser-Y, where X is any amino acid and Y is a hydrophobic amino acid. The part of the polypeptide chain containing the target serine or threonine residue is bound to a shallow groove in the large domain of the kinase core. The peptide specificity of protein kinase A is conferred by several glutamic acid residues in the large domain, which form salt bridges with the two arginine residues in the tar- get peptide. Different residues determine the specificity of other protein kinases. The catalytic core of protein kinase A exists in an “open” and “closed” conformation (Figure 3-17b). In the open con- formation, the large and small domains of the core region are separated enough that substrate molecules can enter and bind. When the active site is occupied by substrate, the do- mains move together into the closed position. This change in tertiary structure, an example of induced fit, brings the tar- get peptide sequence sufficiently close to accept a phosphate
3.3 •^ Enzymes and the Chemical Work of Cells 75
Progress of reaction
Reactants
Transition state (uncatalyzed)
Transition state (catalyzed)
Products
∆ G� uncat
∆ G� cat
Free energy,
G
▲ FIGURE 3-16 Effect of a catalyst on the activation energy of a chemical reaction. This hypothetical reaction pathway depicts the changes in free energy G as a reaction proceeds. A reaction will take place spontaneously only if the total G of the products is less than that of the reactants (�� G ). However, all chemical reactions proceed through one or more high-energy transition states, and the rate of a reaction is inversely proportional to the activation energy (� G ‡^ ), which is the difference in free energy between the reactants and the highest point along the pathway. Enzymes and other catalysts accelerate the rate of a reaction by reducing the free energy of the transition state and thus � G ‡^.
moving molecules between widely dispersed enzymes (Figure 3-20a). To overcome this impediment, cells have evolved mechanisms for bringing enzymes in a common pathway into close proximity. In the simplest such mechanism, polypeptides with differ- ent catalytic activities cluster closely together as subunits of a multimeric enzyme or assemble on a common “scaffold” (Figure 3-20b). This arrangement allows the products of one reaction to be channeled directly to the next enzyme in the pathway. The first approach is illustrated by pyruvate
3.3 •^ Enzymes and the Chemical Work of Cells 77
Vmax
[E] = 1.0 unit
Vmax
[E] = 0.25 unit Rate of formation of reactionproduct (P) (relative units)
0 Km
(a)
Concentration of substrate [S]
Vmax
0
Km for S’
(b)
Concentration of substrate ([S] or [S’])
Rate of reaction
(^) High-affinity substrate (S) Low-affinity substrate (S’)
Km for S
▲ EXPERIMENTAL FIGURE 3-19 The K m and V max for an enzyme-catalyzed reaction are determined from plots of the initial velocity versus substrate concentration. The shape of these hypothetical kinetic curves is characteristic of a simple enzyme-catalyzed reaction in which one substrate (S) is converted into product (P). The initial velocity is measured immediately after addition of enzyme to substrate before the substrate concentration changes appreciably. (a) Plots of the initial velocity at two different concentrations of enzyme [E] as a function of substrate concentration [S]. The [S] that yields a half- maximal reaction rate is the Michaelis constant K m , a measure of the affinity of E for S. Doubling the enzyme concentration causes a proportional increase in the reaction rate, and so the maximal velocity V max is doubled; the K m , however, is unaltered. (b) Plots of the initial velocity versus substrate concentration with a substrate S for which the enzyme has a high affinity and with a substrate S for which the enzyme has a low affinity. Note that the V max is the same with both substrates but that K m is higher for S , the low-affinity substrate.
ADP
Phosphorylated peptide
Phosphate transfer
End state
Intermediate state
ATP
Formation of transition state
Initial state
ATP
O O O O
O
O P O P
CH 2 C
O O
O Mg 2+
Mg 2+
O P
O O
O
CH 2 C
O O
O O
P
O
O
O P O P
CH 2 C
O O
O Mg2+
Lys-
Mg 2+
O
P
O O α
γ
β
O
O
O
O P O P
Asp-
Ser or Thr of target peptide
−
Lys-72 Asp- − −
−
−
2 −
2 −
2 −
H
▲ FIGURE 3-18 Mechanism of phosphorylation by protein kinase A. ( Top ) Initially, ATP and the target peptide bind to the active site (see Figure 3-17a). Electrons of the phosphate group are delocalized by interactions with lysine side chains and Mg 2 �. Colored circles represent the residues in the kinase core critical to substrate binding and phosphoryl transfer. Note that these residues are not adjacent to one another in the amino acid sequence. ( Middle ) A new bond then forms between the serine or threonine side-chain oxygen atom and phosphate, yielding a pentavalent intermediate. ( Bottom ) The phosphoester bond between the � and phosphates is broken, yielding the products ADP and a peptide with a phosphorylated serine or threonine side chain. The catalytic mechanism of other protein kinases is similar.
78 CHAPTER 3 •^ Protein Structure and Function
dehydrogenase, a complex of three distinct enzymes that con- verts pyruvate into acetyl CoA in mitochondria (Figure 3-21). The scaffold approach is employed by MAP kinase signal- transduction pathways, discussed in Chapter 14. In yeast, three protein kinases assembled on the Ste5 scaffold protein form a kinase cascade that transduces the signal triggered by the binding of mating factor to the cell surface. In some cases, separate proteins have been fused together at the genetic level to create a single multidomain, multi- functional enzyme (Figure 3-20c). For instance, the isomer- ization of citrate to isocitrate in the citric acid cycle is catalyzed by aconitase, a single polypeptide that carries out two separate reactions: (1) the dehydration of citrate to form cis -aconitate and then (2) the hydration of cis -aconitate to yield isocitrate (see Figure 8-9).
KEY CONCEPTS OF SECTION 3.
Enzymes and the Chemical Work of Cells
■ The function of nearly all proteins depends on their abil- ity to bind other molecules (ligands). Ligand-binding sites
on proteins and the corresponding ligands are chemically and topologically complementary. ■ The affinity of a protein for a particular ligand refers to the strength of binding; its specificity refers to the prefer- ential binding of one or a few closely related ligands. ■ Enzymes are catalytic proteins that accelerate the rate of cellular reactions by lowering the activation energy and stabilizing transition-state intermediates (see Figure 3-16). ■ An enzyme active site comprises two functional parts: a substrate-binding region and a catalytic region. The amino acids composing the active site are not necessarily adjacent in the amino acid sequence but are brought into proxim- ity in the native conformation. ■ From plots of reaction rate versus substrate concen- tration, two characteristic parameters of an enzyme can be determined: the Michaelis constant K m , a measure of the enzyme’s affinity for substrate, and the maximal ve- locity V max , a measure of its catalytic power (see Figure 3-19).
Reactants
A Products
B
C
C C
A (^) B
Reactants
Products
A
Scaffold
C
C
B
B
A
Reactants Products
Reactants Products
OR
(a)
(b)
(c)
▲ FIGURE 3-20 Evolution of multifunctional enzyme. In the hypothetical reaction pathways illustrated here the initial reactants are converted into final products by the sequential action of three enzymes: A, B, and C. (a) When the enzymes are free in solution or even constrained within the same cellular compartment, the intermediates in the reaction sequence must diffuse from one enzyme to the next, an inherently slow process. (b) Diffusion is greatly reduced or eliminated when the enzymes associate into multisubunit complexes. (c) The closest integration of different catalytic activities occurs when the enzymes are fused at the genetic level, becoming domains in a single protein.
O
HSCoA
CH 3 C SCoA Acetyl CoA NAD+ NADH + H+
O CH 3 C COO−
Pyruvate + NAD+^ + CoA CO 2 + NADH + acetyl CoA
CO 2
E 1 E 2
E 2
E 3
Pyruvate
(b)
(a) E 1
E 3
Net reaction:
▲ FIGURE 3-21 Structure and function of pyruvate dehydrogenase, a large multimeric enzyme complex that converts pyruvate into acetyl CoA. (a) The complex consists of 24 copies of pyruvate decarboxylase (E 1 ), 24 copies of lipoamide transacetylase (E 2 ), and 12 copies of dihydrolipoyl dehydrogenase (E 3 ). The E 1 and E 3 subunits are bound to the outside of the core formed by the E 2 subunits. (b) The reactions catalyzed by the complex include several enzyme-bound intermediates (not shown). The tight structural integration of the three enzymes increases the rate of the overall reaction and minimizes possible side reactions.