Download R programming practical file sem 4 du and more Lab Reports Advanced Computer Programming in PDF only on Docsity!
Kanchan Sagar
20/CS/
R Programming Practical File
Sem - 4
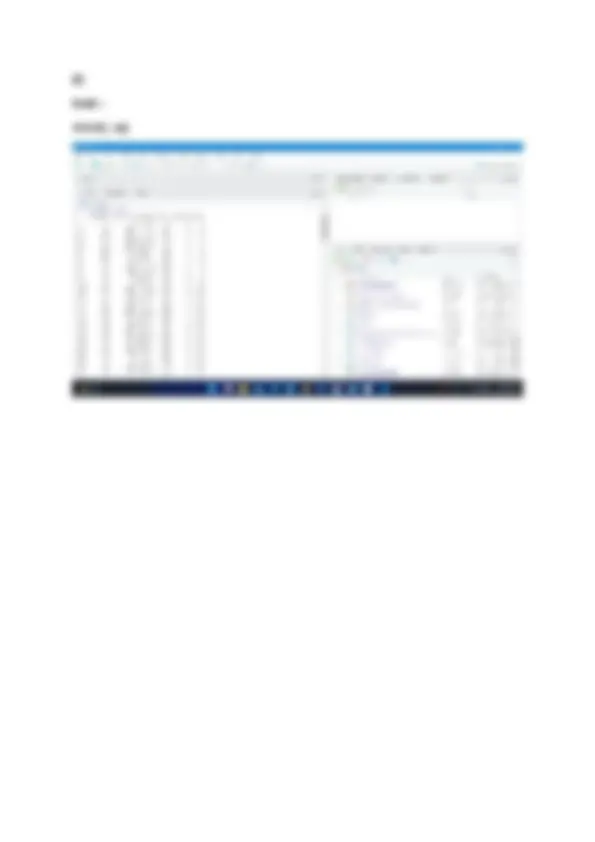
Q1. Write the R commands to do the following: a. Create a numeric, character, integer and logical vector. b. Create two numeric vectors x and y of different lengths. Next, observe the output of 2*x + y - 3. c. Create a sequence of all the odd numbers between 100 and 500. d. Calculate the mean and standard deviation of sequence created in part c. e. Create a list containing a vector, an array and a list. f. Create two multiplication compatible matrices M1 and M2 and display their product. g. Display row-wise and column-wise mean of the matrix M1. h. Combine the matrices M1 and M2 (as in previous part) using rbind/cbind function. i. Convert a 3x4 matrix into 2x4 matrix.
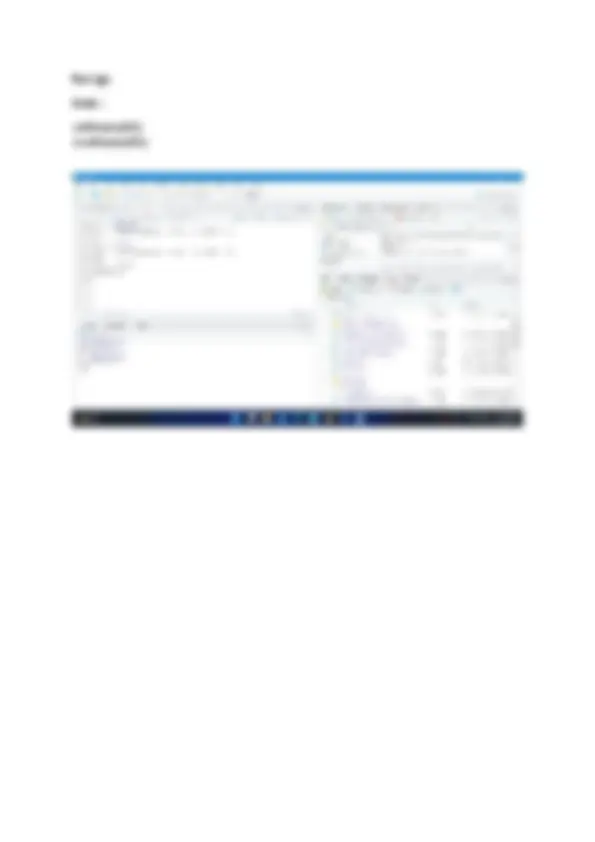
Solution : Part (a) Code : X <- c(1 : 10) as.numeric(x) as.character(x)
Part (b) Code : X <- c(1 : 5) as.numeric(x) y <- c(1 : 9) as.numeric(y) z <- 2 *x+y- 3 z
Part (c) Code : for (num in 100 : 500) { if (num %% 2 == 1) { print(paste("odd number is :", num)) } }
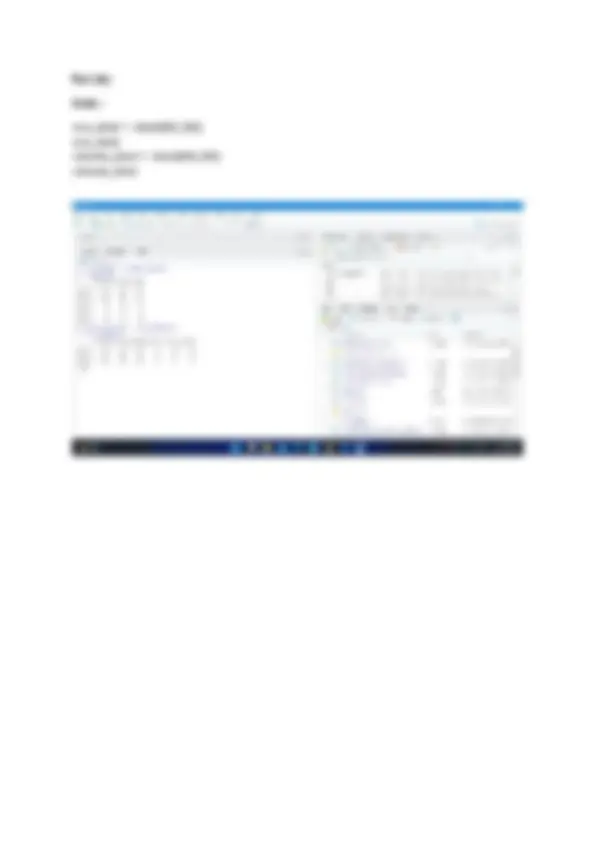
Part (f) Code : a <- c(10:18) M1 <- matrix(data=a , nrow = 3, ncol = 3) M b <- c(1:9) M2 <- matrix(data=b , nrow = 3, ncol = 3) M M3 <- M1*M M
Part (g) Code : colMeans(M1) rowMeans(M1)
Part (i) Code : B <- matrix(1 : 4, nrow = 3, ncol = 4) B B <- B[1 : 2] B
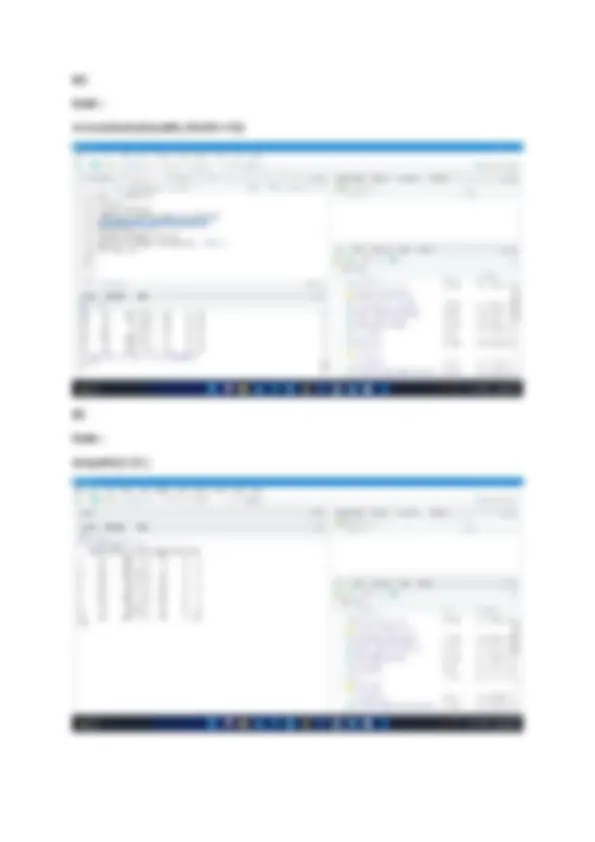
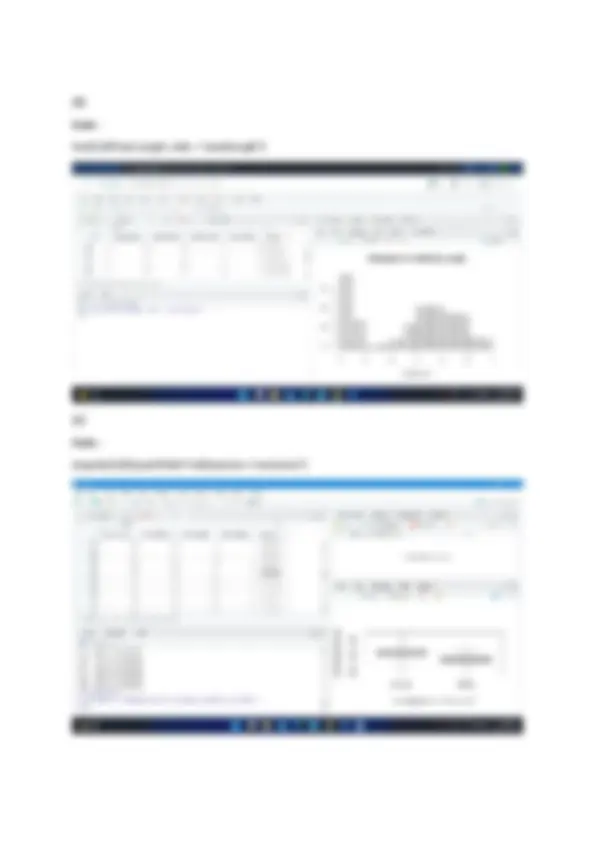
Q2. Use the airquality dataset and write R commands to do the following: a. Display the structure of the dataset. b. Display the number of observations and variables in this dataset. c. Display the count of complete rows. d. Display the data for the observation having Temp between 70 and 80. e. Display the count of observations where Month = 5. f. Display first 10 rows of the dataset. g. Display summary of Wind variable. h. Display the complete dataset sorted as per the decreasing order of Temp variable. i. Add a new observation to this dataset. Solution : (a) code : aq <- airquality str(aq)
(e) Code : nrow(subset(airquality,Month==5)) (f) Code : airquality[1:10,]
(g) Code : summary(airquality$Wind) (h) Code : aq[order(aq$Temp, decreasing = TRUE),]
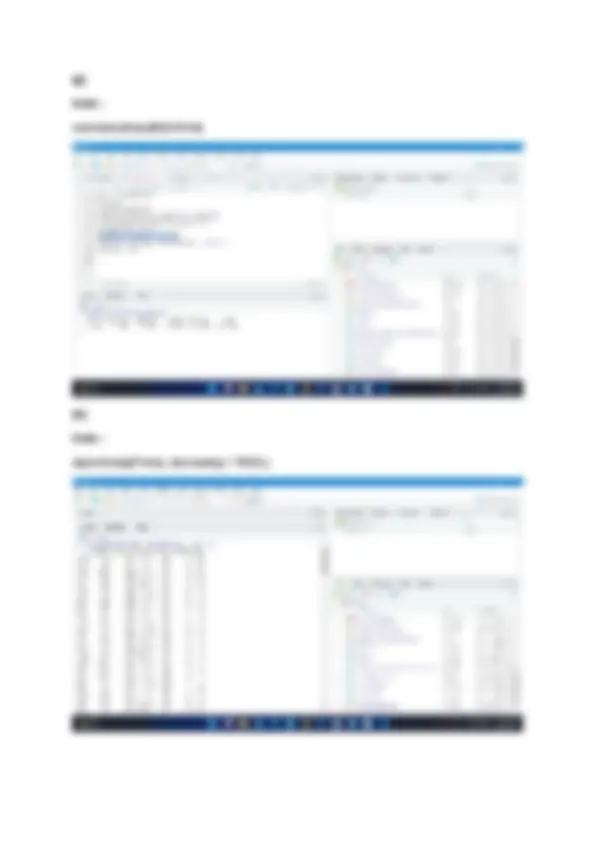
Q3. Download the Toy Dataset CSV file available on Kaggle via the link given ( https://www.kaggle.com/carlolepelaars/toy-dataset). Write R commands to do the following: a. Read the CSV into a data frame object. b. Attach the data frame to the environment. c. Count the number of rows with City = New York City. d. Display rows that have top 5 income values. e. Find out the number of rows with income greater than average income. f. Find the highest salary for the female population. g. Randomly select 10 rows from the given dataset. h. Detach the data frame object from the environment. Solution: (a) Code : library(readr) toy_dataset <- read_csv(“toy_dataset.csv”)
(b) Code : view(toy_dataset) (c) Code : Sum(toy_dataset$City == ‘New York City’)
(f) Code : max(toy_dataset$Income, toy_dataset$Gender == ’Female’) (g) Code : rnorm(toy_dataset, 10)
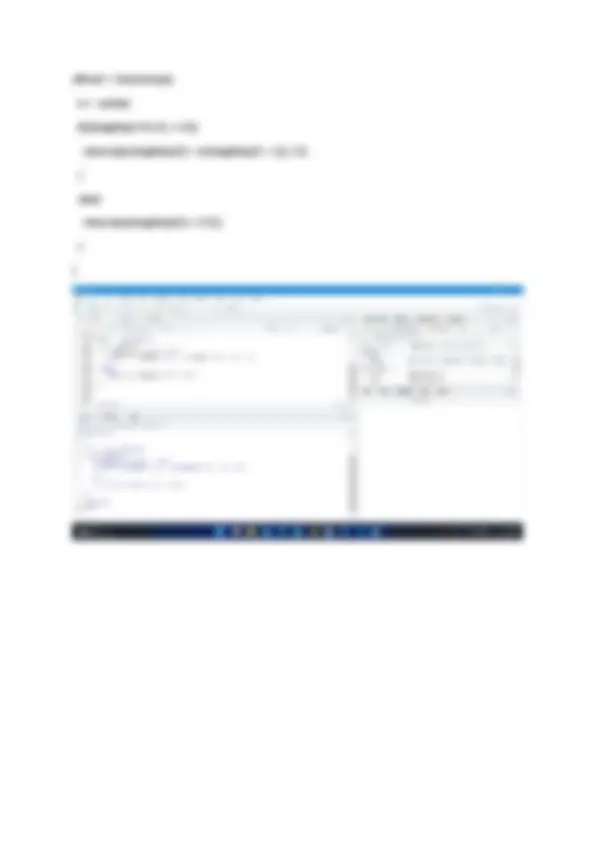
Q4. Write R commands to do the following: a. Create a sample STUDENT table in the MySQL database. b. Insert 5 rows into the STUDENT table. c. Display all the information stored in STUDENT table. d. Delete all the rows from STUDENT table. e. Drop the STUDENT table. Solution : Code : #a. Create a sample STUDENT table in the MySQL database. library(RMySQL) conn<- dbConnect(MySQL(),dbname="world",user="root",host="localhost",port= 3306 ,passwo rd="root") tables<-dbListTables(conn) #con is a predefined function tables #b. Insert 5 rows into the STUDENT table. myquery<-dbSendQuery(conn,"INSERT into student values("Nikita Dey",98)") myquery<-dbSendQuery(conn,"INSERT into student values("Kang Tae Moo",95)") myquery<-dbSendQuery(conn,"INSERT into student values("Son Jong ki",99)") myquery<-dbSendQuery(conn,"INSERT into student values("Minque",98)") myquery<-dbSendQuery(conn,"INSERT into student values("Eunwoo",98)") #c.Display all the information stored in STUDENT table. #selecting rows myquery<-dbSendQuery(conn,"SELECT * from student") dbFetch(myquery,n= 5 ) dbClearResult(myquery) #d.Delete all the rows from STUDENT table. myquery<-dbSendQuery(conn,"DELETE from student") myquery<-dbSendQuery(conn,"SELECT * from student") dbFetch(myquery,n= 5 ) dbClearResult(myquery) #e. Drop the STUDENT table. myquery<-dbSendQuery(conn,"DROP table student") myquery<-dbSendQuery(conn,"SELECT * from student")