



Reinforcement Learning
Jes´us Fern´andez-Villaverde1and Galo Nu˜no2
September 1, 2022
1University of Pennsylvania
2Banco de Espa˜na


































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
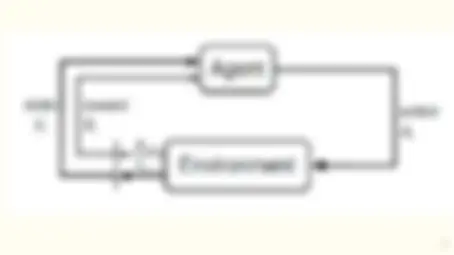
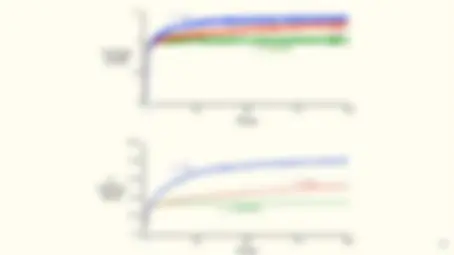
An introduction to reinforcement learning and distributional reinforcement learning. It explains why reinforcement learning is useful and compares it with alternative methods. It also discusses the multi-armed bandit problem and policy-based methods. exercises and a testbed to assess the effectiveness of different methods. It briefly touches on optimistic initial values. likely related to computer science, artificial intelligence, and machine learning.
Typology: Study notes
1 / 45

This page cannot be seen from the preview
Don't miss anything!
Jes´us Fern´andez-Villaverde^1 and Galo Nu˜no^2 September 1, 2022 (^1) University of Pennsylvania
(^2) Banco de Espa˜na
2
Qn(a) =
n
nX− 1
i=
Ri (a)
Qn+1(a) = Qn(a) +
n [Rn(a) − Qn(a)]
Averages of actions not picked are not updated.