



SUN ULTRASPARC-III
ARCHITECTURE
Docsity.com























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
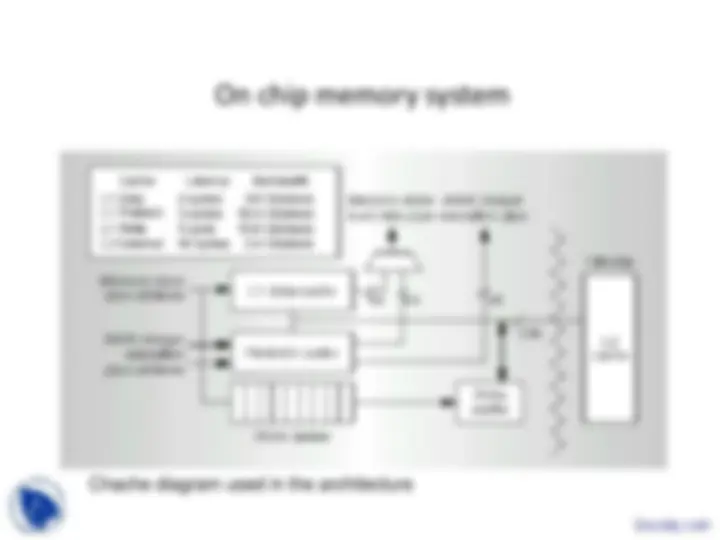
An overview of the sun ultrasparc-iii architecture, focusing on its major functional units and pipeline design. The processor's micro-architecture includes six major units: instruction issue unit, floating point unit, integer execution unit, data cache unit, external memory unit, and system interface unit. The pipeline design consists of various stages, including instruction fetch, decode, execute, and write. The instruction issue unit is responsible for fetching instructions and managing the instruction queue, while the execution unit handles the execution of instructions. The data cache is accessed in parallel with the integer execution unit stages. The floating point unit has a side pipeline that runs parallel to the integer pipeline. The document also discusses the benefits of high instruction parallelism and the use of register files.
Typology: Slides
1 / 33

This page cannot be seen from the preview
Don't miss anything!
-64 bit integer address and data -Superscalar implementations -Extremely fast trap handling and context switching.
The presentation will look in detail to the SUN Microsystem’s Ultra SPARC III v9 architecture.
Communication paths between architectural units
This unit includes:
Pipeline
Pipeline blocks
Stage Function
A Generate instruction fetch addresses, generate pre- decoded instruction bits on P Fetch first cycle of instructions from cache; access first cycle of branch prediction F Fetch second cycle of instructions from cache; access second cycle of branch prediction; translate virtual-to- physical address B Calculate branch target addresses; decode first cycle of instructions I Decode second cycle of instructions;enqueue instructions into the queue J Steer instructions to execution units R Read integer register file operands; check operand dependencies E Execute integers for arithmetic, logical, and shift instructions; read, and check dependency of, first cycle of data cache access floating-point register file
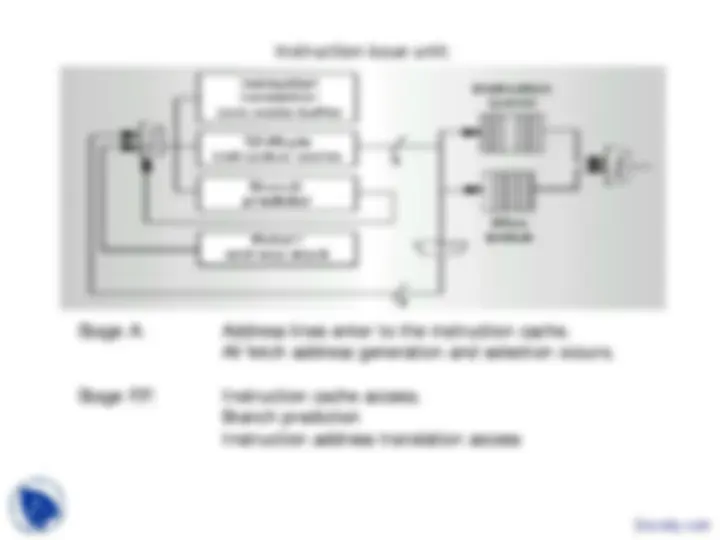
Instruction issue unit:
Stage A: Address lines enter to the instruction cache. All fetch address generation and selection occurs.
Stage P,F: Instruction cache access. Branch prediction Instruction address translation access
By the time the instructions are available from the cache in the B stage, we also have the physical address from the translator and a prediction for any branch that was fetched.
The processor uses all this information in the B stage to determine whether to follow a sequential or taken-branch path
Instruction buffer (queue)
Integer execute unit
However only four Instructions per cycle (IPC) can be executed in a sustain manner.
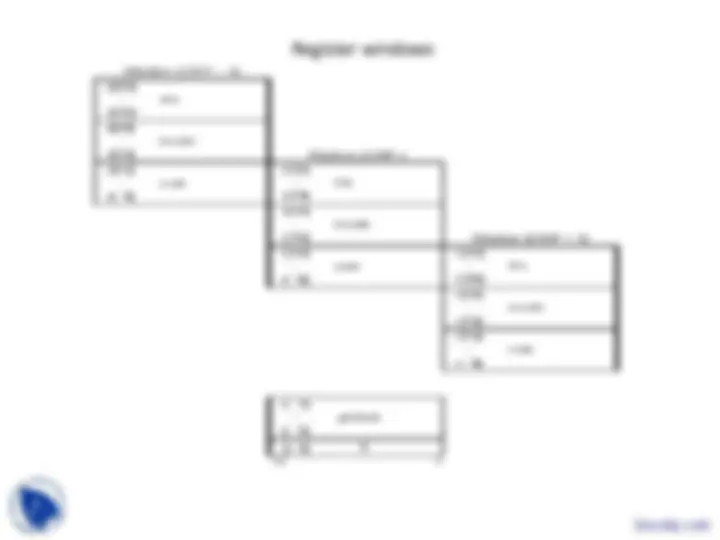
Register windows
WARF
8x8=64 for local registers in the window 8x8=64 registers for 16 IN/OUT shared registers. 28 register for 4 set of 8 global registers.