Download Data Structures: Hash Tables and Skip Lists and more Slides Computer Science in PDF only on Docsity!
Algorithms
Hash Tables
Homework 4
● Programming assignment:
■ Implement Skip Lists
■ Evaluate performance
■ Extra credit: compare performance to randomly
built BST
■ Due Mar 9 (Fri before Spring Break)
■ Will post later today
Summary: Skip Lists
● O(1) expected time for most operations
● O(lg n) expected time for insert
● O(n^2 ) time worst case
■ But random, so no particular order of insertion
evokes worst-case behavior
● O(n) expected storage requirements
● Easy to code
Review: Hash Tables
● Hash table:
■ Given a table T and a record x, with key (=
symbol) and satellite data, we need to support:
○ Insert (T, x)
○ Delete (T, x)
○ Search(T, x)
■ We want these to be fast, but don’t care about
sorting the records
■ In this discussion we consider all keys to be
(possibly large) natural numbers
Review: The Problem With
Direct Addressing
● Direct addressing works well when the range
m of keys is relatively small
● But what if the keys are 32-bit integers?
■ Problem 1: direct-address table will have
2 32 entries, more than 4 billion
■ Problem 2: even if memory is not an issue, the
time to initialize the elements to NULL may be
● Solution: map keys to smaller range 0..m-
● This mapping is called a hash function
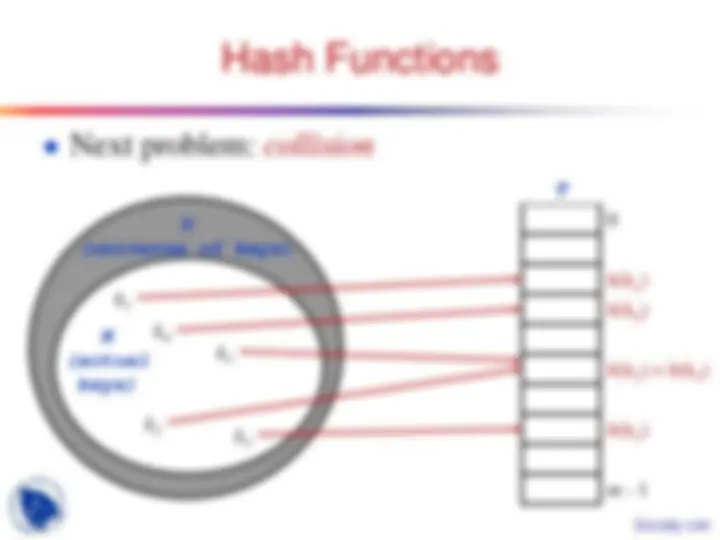
Hash Functions
● Next problem: collision
T
m - 1
h(k 1 ) h(k 4 )
h(k 2 ) = h(k 5 )
h(k 3 )
k (^4)
k 2 k (^3)
k (^1)
k (^5)
U
(universe of keys)
K
(actual keys)
Open Addressing
● Basic idea (details in Section 12.4):
■ To insert: if slot is full, try another slot, …, until an
open slot is found (probing)
■ To search, follow same sequence of probes as
would be used when inserting the element
○ If reach element with correct key, return it
○ If reach a NULL pointer, element is not in table
● Good for fixed sets (adding but no deletion)
■ Example: spell checking
● Table needn’t be much bigger than n
Chaining
● Chaining puts elements that hash to the same
slot in a linked list:
T
k 4
k 2 k^3
k (^1)
k (^5)
U
(universe of keys)
K
(actual keys)
k (^6) k (^8)
k (^7)
k 1 k 4 ——
k 5 k 2
k 3 k 8 k 6 ——
k 7 ——
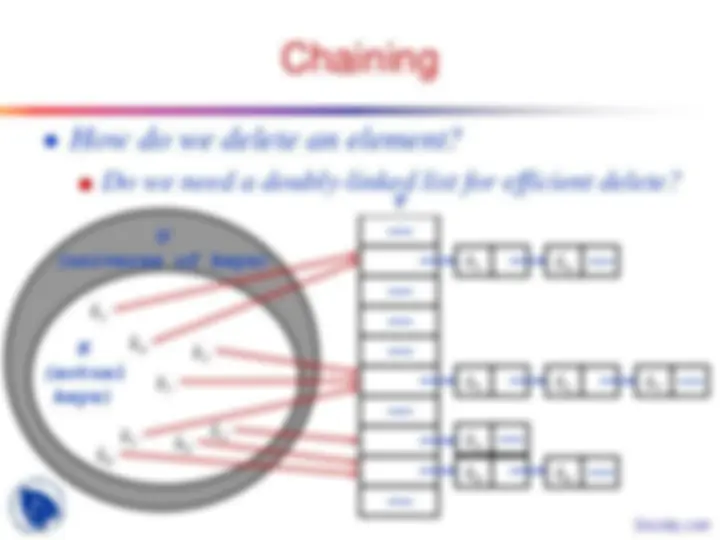
Chaining
T
k 4
k 2 k^3
k (^1)
k (^5)
U
(universe of keys)
K
(actual keys)
k (^6) k (^8)
k (^7)
k 1 k 4 ——
k 5 k 2
k 3 k 8 k 6 ——
k 7 ——
● How do we delete an element?
■ Do we need a doubly-linked list for efficient delete?
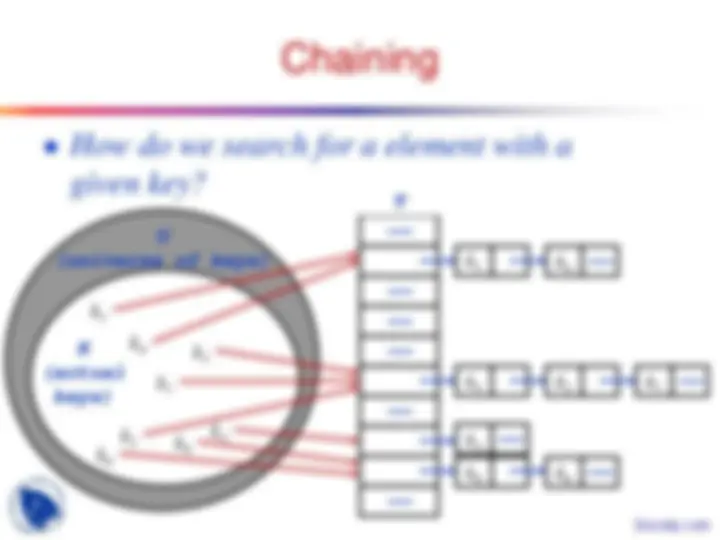
Chaining
● How do we search for a element with a
given key?
T
k 4
k 2 k^3
k (^1)
k (^5)
U
(universe of keys)
K
(actual keys)
k (^6) k (^8)
k (^7)
k 1 k 4 ——
k 5 k 2
k 3 k 8 k 6 ——
k 7 ——
Analysis of Chaining
● Assume simple uniform hashing: each key in
table is equally likely to be hashed to any slot
● Given n keys and m slots in the table, the
load factor α = n/m = average # keys per slot
● What will be the average cost of an
unsuccessful search for a key? A: O(1+ α)
Analysis of Chaining
● Assume simple uniform hashing: each key in
table is equally likely to be hashed to any slot
● Given n keys and m slots in the table, the
load factor α = n/m = average # keys per slot
● What will be the average cost of an
unsuccessful search for a key? A: O(1+ α)
● What will be the average cost of a successful
search?
Analysis of Chaining Continued
● So the cost of searching = O(1 + α)
● If the number of keys n is proportional to the
number of slots in the table, what is α?
● A: α = O(1)
■ In other words, we can make the expected cost of
searching constant if we make α constant
Choosing A Hash Function
● Clearly choosing the hash function well is
crucial
■ What will a worst-case hash function do?
■ What will be the time to search in this case?
● What are desirable features of the hash
function?
■ Should distribute keys uniformly into slots
■ Should not depend on patterns in the data