


Dec. 2006 Algorithm Design Methods Slide 1
Fault-Tolerant Computing
Software
Design
Methods













Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of algorithm design methods for fault-tolerant computing, focusing on the use of commercial off-the-shelf (cots) components and robust data structures. The presentation covers the history of software-implemented fault tolerance (sift), limitations of cots-based approaches, and methods for protecting commonly used data structures. The document also discusses the concept of algorithm-based error tolerance and data diversity.
Typology: Study Guides, Projects, Research
1 / 21

This page cannot be seen from the preview
Don't miss anything!
Dec. 2006
Algorithm Design Methods
Slide 1
Dec. 2006
Algorithm Design Methods
Slide 2
Released
Revised
Revised
First^
Dec. 2006
This presentation has been prepared for the graduatecourse ECE 257A (Fault-Tolerant Computing) byBehrooz Parhami, Professor of Electrical and ComputerEngineering at University of California, Santa Barbara.The material contained herein can be used freely inclassroom teaching or any other educational setting.Unauthorized uses are prohibited. © Behrooz Parhami
Dec. 2006
Algorithm Design Methods
Slide 4
Dec. 2006
Algorithm Design Methods
Slide 5
Component
Logic
Service
Result
Information
System
Level^ →
Low-Level Impaired
Mid-Level Impaired
High-Level Impaired
Unimpaired
Entry Legend:
Deviation
Remedy
Tolerance
Ideal
Defective
Faulty
Erroneous
Malfunctioning
Degraded
Failed
Dec. 2006
Algorithm Design Methods
Slide 7
SIFT (software-implemented fault tolerance), developed at Stanford inearly 1970s using mostly COTS components, was one of two competing“concept systems” for fly-by-wire aircraft control The other one, FTMP (fault-tolerant multiprocessor), developed at MIT,used a hardware-intensive approach System failure rate goal: 10
–9^ /hr over a 10-hour flight
SIFT allocated tasks for execution on multiple, loosely synchronizedCOTS processor-memory pairs (skew of up to 50
μs was acceptable);
only the bus system was custom designed Some fundamental results on, and methods for, clock synchronizationemerged from this project To prevent errors from propagating, processors obtained multiple copiesof data from different memories over different buses (local voting)
Dec. 2006
Algorithm Design Methods
Slide 8
Dec. 2006
Algorithm Design Methods
Slide 10
Simple linked list: 0-detectable, 0-correctable Circular list, with node count and unique ID: 1-detectable, 0-correctable
ID^
ID^
ID^
ID^
ID
Size Doubly linked list, with node count and ID: 2-detectable, 1-correctable
ID^
ID^
ID^
ID^
ID
Size Cannot recover from even one erroneous link Add skip links to make this 3-detectable, 1-correctable
Skip
Dec. 2006
Algorithm Design Methods
Slide 11
Trees, FIFOs, stacks (LIFOs), heaps, queues In general, a linked data structure is 2-detectable and 1-correctable iffthe link network is 2-connected Robust data structures provide fairly good protection with little designeffort or run-time overhead^ Audits can be performed during idle time^ Reuse possibility makes the method even more effective Robustness features to protect the structure can be combined withcoding methods (such as checksums) to protect the content
Dec. 2006
Algorithm Design Methods
Slide 13
M^ =r^
M^ =f^
2
Matrix M^ =c^
Row checksum matrix
Column checksum matrix
Full checksum matrix
Error coding applied to data structures, rather than at the level of atomicdata elements Example: mod-8checksums usedfor matrices If^ Z^ =^
then Z =^ X f^
×^ Y c r In^ M , any singlef error is correctableand any 3 errorsare detectable Four errors maygo undetected
Dec. 2006
Algorithm Design Methods
Slide 14
If^ Z^ =^
then Z =^ X f^
×^ Y c r
Column checksummatrix for
X 2
46 + 20 + 42 = 108 = 4 mod 8 20 + 41 + 30 = 91 = 3 mod 8
35 = 3 mod 8
36 = 4 mod 8
×^ Row checksum matrix for
Y
Dec. 2006
Algorithm Design Methods
Cell 6 Slide 16
Cell 1^
Cell 2^
Cell 3^
Cell 4^
Cell 5
Linear array with an extra cell can redo the same pipelined computationwith each step of the original computation shifted in space Each cell
i^ + 1 compares the result of step
i^ that it received from the left
in the first computation to the result of step
i^ that it obtains in the second
computation With two extra cells in the linear array, three computations can bepipelined and voting used to derive highly reliable results
1
2
3
4
5
1 ′^
2 ′^
3 ′^
4 ′^
5 ′
Dec. 2006
Algorithm Design Methods
Slide 17
Byzantine Timing Omission Crash Node stops (does notundergo incorrect transitions)
Node does not respondto some inputs
Node responds eithertoo early or too late
Totally arbitrary behavior
Dec. 2006
Algorithm Design Methods
Slide 19
A group of processes may be cooperating for solving a problem The group’s membership may expand and contract owing to changingprocessing requirements or because of malfunctions and repairs Reliable multicast:
message guaranteed to be received by all
members within the group ECE 254C:
Advanced Computer Architecture – Distributed Systems (course devoted to distributed computing and its reliability issues)
Dec. 2006
Algorithm Design Methods
Slide 20
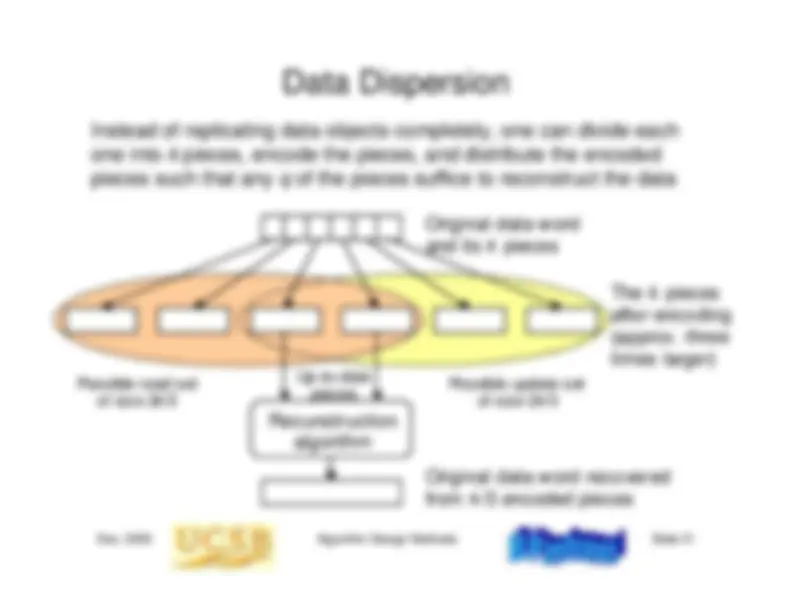
Resilient objects using the primary site approach Active replicas: the state-machine approach Request is sent to all replicas All replicas are equivalent and any one of them can service the request Ensure that all replicas are in same state (e.g., via atomic broadcast) Read and write quorumsExample: 9 replicas, arranged in 2D gridRows constitute write quorumsColumns constitute read quorumsA read quorum contains the latest update Maintaining replica consistency very difficult under Byzantine faults Will discuss Byzantine agreement next time
Mostup-to-datereplicasPossibleread quorum