



Ravi Ramamurthy
DMX Group
Microsoft Research
1 5/25/2011 Stanford Talk
docsity.com































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
This lecture was delivered by Chandrakiran Bonjani at Allahabad University. Its related to Database System Implementation and its main points are: SQL, Server, Optimizer, Critique, Empirical, Statistics, Cascades, Framework, Extensible, Logical, Algorithms
Typology: Slides
1 / 44

This page cannot be seen from the preview
Don't miss anything!
5/25/2011 Stanford Talk 1
5/25/2011 Stanford Talk
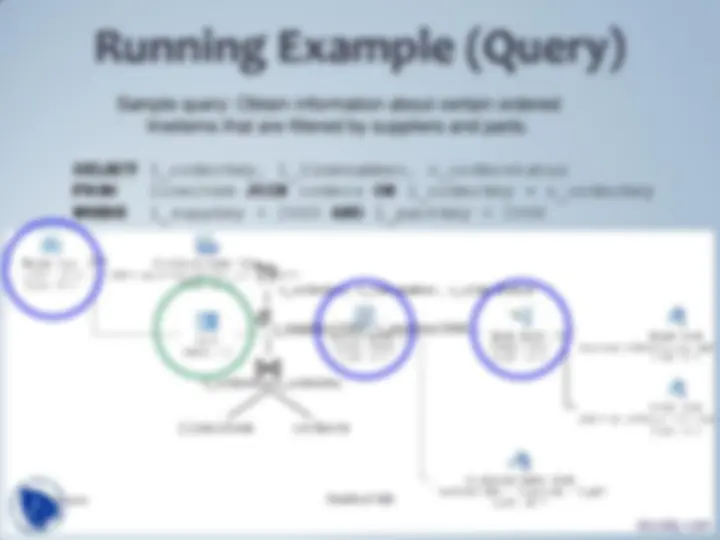
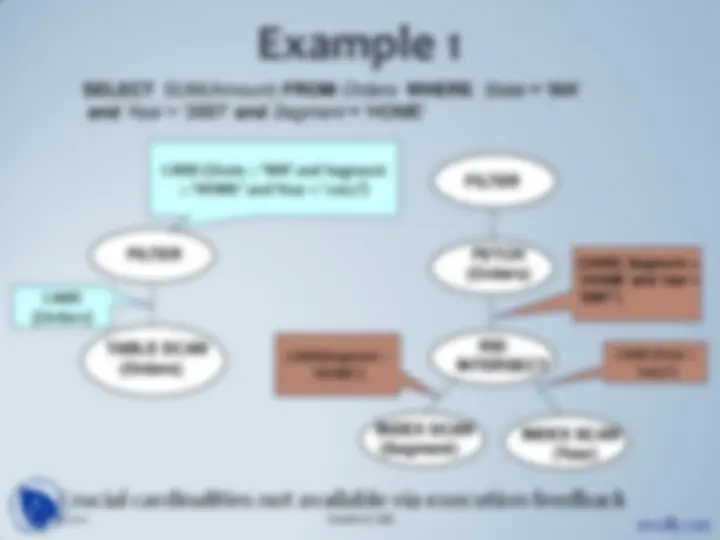
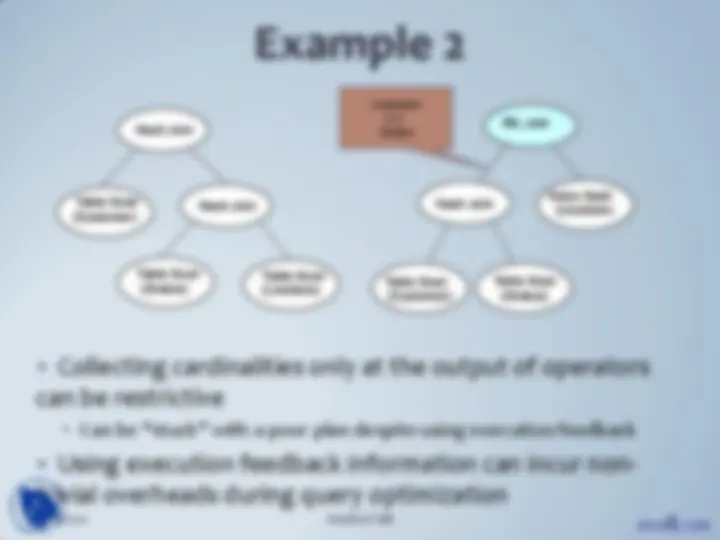
SELECT l_orderkey, l_linenumber, o_orderstatus FROM lineitem JOIN orders ON l_orderkey = o_orderkey
WHERE l_suppkey < 2000 AND l_partkey < 2000
lineitem
l_suppkey<2000, l_partkey<
l_orderkey=o_orderkey
orders
l_orderkey, l_linenumber, o_orderstatus
Sample query: Obtain information about certain ordered
lineitems that are filtered by suppliers and parts.
5/25/2011 Stanford Talk
( Programs = Algorithms + Data Structures )
5/25/2011 Stanford Talk
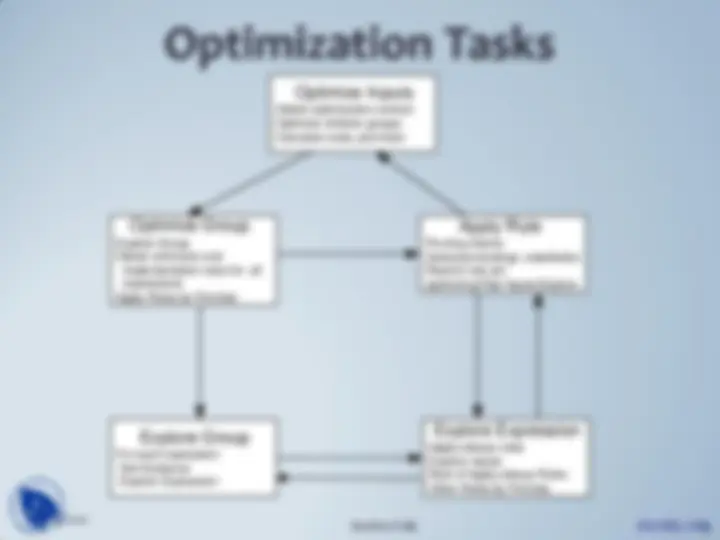
Search Space Memory
Compactly stores all explored alternatives (AND-OR graph)
Groups together equivalent operator trees and their plans
Provides memoization, duplicate detection, property and cost
management, etc.
b>
a< R
a<10 b>201) SELECT (a<10, ) R S
R 1) GET(R) S 1) GET(S)
R b> S
JOIN (x=y, , )
...
...
Groups
Expressions
5/25/2011 Stanford Talk
Logical Properties
Valid for whole group E.g.: cardinality, output columns, column equivalences, distinctness
Flow bottom-up
Root Group 12: 0) Join 7 8 11 Group 11: 0) Comp (=) 9 10 Group 10: 0) Identifier (l_orderkey) Group 9: 0) Identifier (o_orderkey) Group 8: 0) Get (orders) Group 7: 0) Select 5 6 Group 6: 0) Logical (and) 2 4 Group 5: 0) Get (lineitem) Group 4: 0) Comp (<) 3 1 Group 3: 0) Identifier (l_partkey) Group 2: 0) Comp (<) 0 1 Group 1: 0) Const (2000) Group 0: 0) Identifier (l_suppkey)
Root Group 12: 5 Apply(lineitem_0) 8 47 4 HashJoin 7.5 8.3 11.0 [Cost=70.75] 3 MergeJoin 8.1 7.3 11.0 [Cost=68.12] 2 MergeJoin 7.3 8.1 11.0 [Cost=72.14] 1 Join 8 7 11 0 Join 7 8 11
Group 7: 7 Filter 5.3 6 6 Filter 44 2 5 Apply (lineitem_0) 32.1 41.1 [Cost=45.43] 4 Apply (lineitem_0) 32.3 41.2 [Cost=50.33] 3 Sort (l_orderkey) 7.5 [Cost=46.22] 2 Filter 5.1 6.0 [Cost=94.71] 1 Filter 15.1 6.0 [Cost=94.71] 0 Select 5 6 ...
Physical Properties Valid for specific expression E.g.: sort columns, halloween protection, cursors Flow in both directions (derived vs. required) 5/25/2011 Stanford Talk
Root Group 12: 0) Join 7 8 11 Group 11: 0) Comp (=) 9 10 Group 10: 0) Identifier (l_orderkey) Group 9: 0) Identifier (o_orderkey) Group 8: 0) Get (orders) Group 7: 0) Select 5 6 Group 6: 0) Logical (and) 2 4 Group 5: 0) Get (lineitem) Group 4: 0) Comp (<) 3 1 Group 3: 0) Identifier (l_partkey) Group 2: 0) Comp (<) 0 1 Group 1: 0) Const (2000) Group 0: 0) Identifier (l_suppkey)
Root Group 12: 0) Join 7 8 11 1) Join 8 7 11 Group 11: 0) Comp (=) 9 10 Group 10: 0) Identifier (l_orderkey) Group 9: 0) Identifier (o_orderkey) Group 8: 0) Get (orders) Group 7: 0) Select 5 6 Group 6: 0) Logical (and) 2 4 Group 5: 0) Get (lineitem) Group 4: 0) Comp (<) 3 1 Group 3: 0) Identifier (l_partkey) Group 2: 0) Comp (<) 0 1 Group 1: 0) Const (2000) Group 0: 0) Identifier (l_suppkey)
5/25/2011 (^) Stanford Talk
**Group 15: 0) GetIdx lineitem
Group 13: 0) GetIdx orders_ Root Group 12: 0) Join 7 8 11
5/25/2011 Stanford Talk
SELECT l_tax, o_totalprice
FROM lineitem JOIN orders ON l_orderkey = o_orderkey WHERE l_suppkey < 2000 AND l_partkey < 2000
SELECT l_tax, o_totalprice
FROM lineitem JOIN orders ON l_orderkey = o_orderkey WHERE l_suppkey < 20000 AND l_partkey < 20000
Stanford Talk
5/25/2011 Microsoft Confidential 17