


Allama Iqbal Open University Islamabad
Course Code (5412)
Assignment No 1
Spring 2025
Name:
Junaid Ahmad
Student I.D
0000344015
Program:
5412




























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Statistics for management assignment for 2025. #aiou #Hrm
Typology: Study Guides, Projects, Research
1 / 37

This page cannot be seen from the preview
Don't miss anything!
Name: Junaid Ahmad Student I.D 0000344015 Program: 5412
Semester: Spring 2025 Total Marks: 100 Pass Marks: 50
(Units: 1 - 5)
(a) What does Statistic mean? Definition:
Statistics is broadly divided into two major types:
1. Descriptive Statistics: Descriptive statistics deals with summarizing and organizing data in an informative way. It helps us to describe the basic features of the data. Key Functions: - Organizing data through tables and charts. - Summarizing data with numerical measures. Common Tools: - Measures of Central Tendency: Mean, Median, Mode. - Measures of Dispersion: Range, Variance, Standard Deviation. - Graphical Representations: Histograms, Bar charts, Pie charts. Example: Suppose a teacher calculates the average marks of students in a class — this is descriptive statistics as it summarizes the data. 2. Inferential Statistics: Inferential statistics allows us to draw conclusions and make predictions about a population based on a sample. Key Techniques: - Hypothesis Testing
Example: Population data classified into Punjab, Sindh, Balochistan, KPK, etc.
2. Chronological Classification: Data is arranged according to time (years, months, days). Example: Annual rainfall data from 2010 to 2020. 3. Qualitative Classification: Based on qualities or attributes which cannot be measured numerically such as gender, religion, literacy, marital status, etc. Types: - Simple Classification: One attribute (e.g., male/female) - Manifold Classification: Two or more attributes (e.g., married males, unmarried females) 4. Quantitative Classification: Based on numerical variables or measurable quantities like age, height, weight, income, etc.
Example: Age group: 0-10, 11-20, 21-30 years. Principles of Classification: To ensure meaningful and accurate classification of data, certain principles must be followed:
1. Clarity and Simplicity: The classification should be simple and clear. Complex categories can confuse the reader. 2. Exclusiveness and Exhaustiveness: Each data item must fit into one and only one category (mutually exclusive), and all data must be covered (collectively exhaustive). 3. Stability: Classification criteria should remain consistent throughout the study unless there is a justifiable reason to modify it. 4. Uniformity of Measurement: All items should be measured using the same standard. For example, height should be measured in either inches or centimeters consistently.
Conclusion: Statistics is a powerful discipline that helps us draw meaningful conclusions from data. It begins with the collection of data and proceeds with classification, tabulation, and analysis. Statistics as a measure helps in summarizing data, while classification organizes it into understandable groups. Both these processes are essential for any kind of quantitative or qualitative research. A deep understanding of these foundational concepts enables students, researchers, and professionals to make informed and accurate decisions based on empirical evidence.
(a) Criteria for Judging the Merits of an Average & Merits/Demerits of Different Averages
Definition of Average: An average , or measure of central tendency , is a single numerical value that represents the "center" or typical value of a dataset. It helps to summarize large volumes of data into one representative value, providing a quick understanding of the general trend of the data. Criteria to Judge a Good Average: A good average must fulfill the following criteria:
1. Simplicity: It should be simple to understand and easy to calculate. Even a person without deep statistical knowledge should be able to grasp its meaning. 2. Rigidly Defined: It must have a clear and unambiguous definition so that it gives consistent results when applied by different people. 3. Based on All Observations: A reliable average should take into account every value in the dataset to give a more representative result. 4. Not Affected by Extreme Values: It should not be unduly affected by very large or very small values (outliers) that can distort the result.
3. Mode: The value that occurs most frequently in a dataset. Merits: - Simple to understand. - Not affected by extreme values. - Useful for categorical data (e.g., most popular product). Demerits: - May not exist or may have more than one value (bimodal or multimodal). - Doesn't represent the dataset well in many cases. - Not suitable for further statistical analysis. Summary Table of Merits and Demerits: Average Type Merits Demerits Arithmetic Mean Simple, uses all data, algebraically treatable Affected by outliers, not good for skewed data Median Not affected by outliers, suitable for skewed data Ignores extreme values, hard to use in calculations Mode Simple, best for qualitative data May be undefined or multiple, not algebra-friendly
Example:
A parameter is a numerical value that describes a characteristic of the entire population. Example:
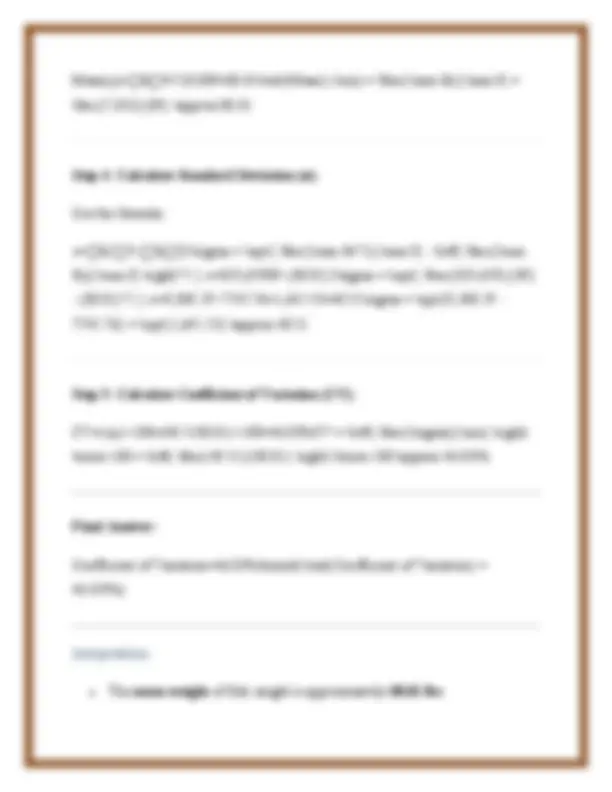
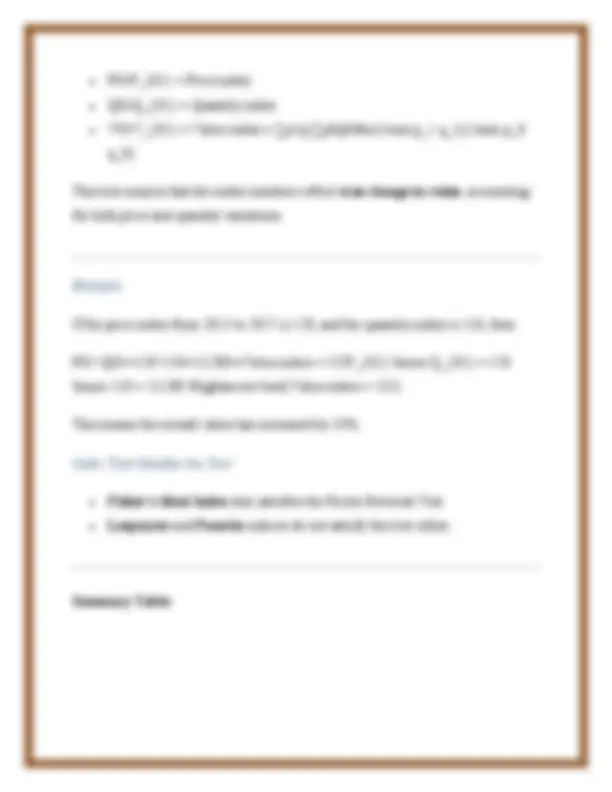
(a) What is the Coefficient of Variation? (10 marks) Definition: The Coefficient of Variation (CV) is a statistical measure that represents the ratio of the standard deviation (σ) to the mean (μ) of a dataset. It is a relative measure of dispersion that helps in comparing the variability of two or more datasets that have different units or widely different means. Formula: Coefficient of Variation (CV)=(Standard Deviation (σ)Mean (μ))×100\text{Coeffic ient of Variation (CV)} = \left( \frac{\text{Standard Deviation (σ)}}{\text{Mean (μ)}} \right) \times 100 Purpose and Use: