Download System Architecture - Computer Systems Architecture - Lecture Slides and more Slides Computer Architecture and Organization in PDF only on Docsity!
The IBM Blue Gene/L System
Architecture
What is Blue Gene/L?
- Blue Gene is an IBM Research project dedicated to exploring the frontiers in supercomputing.
- In November 2004, the IBM Blue Gene computer became the fastest supercomputer in the world.
- This project is designed to scale to 65,536 dual-processor nodes, with a peak performance of 360 TeraFLOPS.
- Example usage:
- hydrodynamics
- quantum chemistry
- molecular dynamics
- climate modeling
- financial modeling
Main Design Principles for Blue Gene/L
- Some science & engineering applications scale up to and beyond 10,000 parallel processes.
- Improve computing capability, holding total system cost.
- Reduce cost/FLOP.
- Reduce complexity and size.
- ~25KW/rack is max for air-cooling in standard room.
- Need to improve performance/power ratio.
- 700MHz PowerPC440 for ASIC has excellent FLOP/Watt.
- Maximize Integration:
- On chip: ASIC with everything except main memory.
- Off chip: Maximize number of nodes in a rack..
- Large systems require excellent reliability, availability, serviceability (RAS)
Main Design Principles (cont’d)
- Make cost/performance trade-offs considering the end-use: - Applications <> Architecture <> Packaging - Examples: - 1 or 2 differential signals per torus link. - I.e. 1.4 or 2.8Gb/s. - Maximum of 3 or 4 neighbors on collective network. - I.e. Depth of network and thus global latency.
- Maximize the overall system efficiency:
- Small team designed all of Blue Gene/L.
- Example: Chose ASIC die and chip pin-out to ease circuit card routing.
Blue Gene/L Architecture
- Up to 323264=65536 nodes (3D torus).
- Max 360 teraFLOPS computation power.
- Each processor can perform 4 floating point
operations per cycle (in the form of two 64-bit floating point multiply-add’s per cycle)
- 5 networks connect nodes to themselves and
to the world.
Node Architecture
- IBM PowerPC embedded CMOS processors, embedded DRAM, and system-on-a-chip technique is used.
- 11.1-mm square die size, allowing for a very high density of processing.
- The ASIC uses IBM CMOS CU-11 0.13 micron technology.
- 700 Mhz processor speed close to memory speed.
- Two processors per node.
- Second processor is intended primarily for handling message passing operations
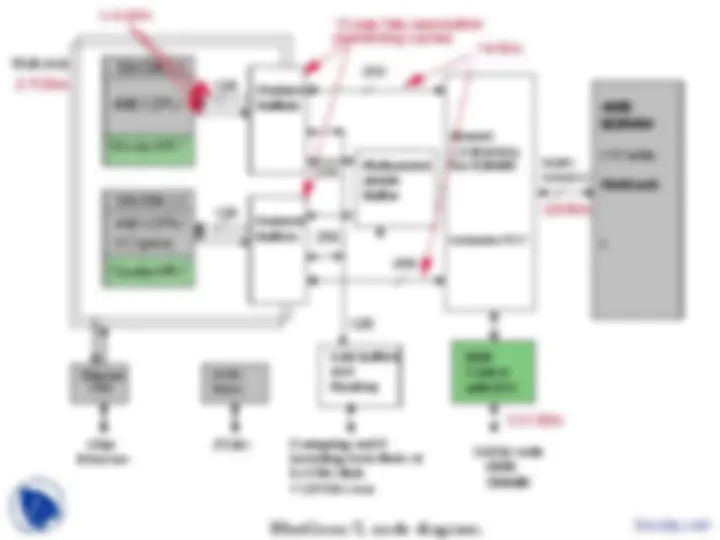
BlueGene/L node diagram. Docsity.com
Link ASIC
- In addition to the compute ASIC, there is a “link” ASIC.
- When crossing
- a midplane boundary
- BG/L’s torus
- global combining tree
- global interrupt signals pass through the BG/L link ASIC.
- It redrives signals over the cables between BG/L midplanes.
- The link ASIC can redirect signals between its different ports.
- enables BG/L to be partitioned into multiple, logically separate systems in which there is no traffic interference between systems.
The FP2 core (cont’d)
- This enhanced set goes beyond the capabilities of
traditional SIMD architectures.
- A single instruction can initiate a different but related
operation on different data.
- Single Instruction Multiple Operation Multiple Data
(SIMOMD).
- Either of the sides can access data from the other
side’s register file.
- This saves a lot of swapping when working purely on
complex arithmetic operations.
Memory System
- It is designed for high bandwidth, low latency
memory and cache accesses.
- An L2 hit returns in 6 to 10 processor cycles
- An L3 hit in about 25 cycles
- An L3 miss in about 75 cycles
- System has a 16 byte interface to nine 256Mb
SDRAM-DDR devices.
- Operating at a speed of one half or one third
of the processor.
Torus Network (cont’d)
- Class Routing Capability (Deadlock-free
Hardware Multicast)
- Packets can be deposited along route to specified destination.
- Allows for efficient one to many in some instances
- Active messages allows for fast transposes as
required in FFTs.
- Independent on-chip network interfaces enable
concurrent access.
Other Networks
- A global combining/broadcast tree for
collective operations
- A Gigabit Ethernet network for connection to
other systems, such as hosts and file systems.
- A global barrier and interrupt network
- And another Gigabit Ethernet to JTAG network
for machine control
Gb Ethernet Disk/Host I/O Network
- IO nodes are leaves on collective network.
- Compute and IO nodes use same ASIC, but:
- IO node has Ethernet not torus. Provedes IO seperation on application.
- Compute node has torus, not Ethernet: No need for 65536 cables.
- Configurable ratio of IO to compute = 1:8,16,32,64,128.
- Application runs on compute nodes, not IO nodes.
Fast Barrier/Interrupt Network
- Four Independent Barrier or Interrupt Channels
- Independently Configurable as "or" or "and"
- Asynchronous Propagation
- Halt operation quickly (current estimate is 1.3usec worst case round trip)
- 3/4 of this delay is time-of-flight.
- Sticky bit operation
- Allows global barriers with a single channel.
- User Space Accessible
- It is partitioned along same boundaries as Tree, and Torus
- Each user partition contains it's own set of barrier/ interrupt signals