Download think statistics chapter one and more Cheat Sheet Computer science in PDF only on Docsity!
Chapter 1. Exploratory Data Analysis
The thesis of this book is we can use data to answer questions, resolve debates, and make better decisions.
This chapter introduces the steps we’ll use to do that: loading and validating data, exploring, and choosing statistics that measure what we are interested in. As an example, we’ll use data from the National Survey of Family Growth (NSFG) to answer a question I heard when my wife and I were expecting our first child: do first babies tend to arrive late?
Evidence
You might have heard that first babies are more likely to be late. If you search the web with this question, you will find plenty of discussion. Some people claim it’s true, others say it’s a myth, and some people say it’s the other way around: first babies come early.
In many of these discussions, people provide data to support their claims. I found many examples like these:
“My two friends that have given birth recently to their first babies, BOTH went almost 2 weeks overdue before going into labour or being induced.”
“My first one came 2 weeks late and now I think the second one is going to come out two weeks early!!”
“I don’t think that can be true because my sister was my mother’s first and she was early, as with many of my cousins.”
Reports like these are called anecdotal evidence because they are based on data that is unpublished and usually personal. In casual conversation, there is nothing wrong with anecdotes, so I don’t mean to pick on the people I quoted.
But we might want evidence that is more persuasive and an answer that is more reliable. By those standards, anecdotal evidence usually fails, due to:
Small number of observations If pregnancy length is longer for first babies, the difference is probably small compared to natural variation. In that case, we might have to compare a large number of pregnancies to know whether there is a difference.
Selection bias People who join a discussion of this question might be interested because their first babies were late. In that case the process of selecting data would bias the results.
Confirmation bias People who believe the claim might be more likely to contribute examples that confirm it. People who doubt the claim are more likely to cite counterexamples.
By performing these steps with care to avoid pitfalls, we can reach conclusions that are more justified and more likely to be correct.
The National Survey of Family Growth
Since 1973 the US Centers for Disease Control and Prevention (CDC) have conducted the National Survey of Family Growth (NSFG), which is intended to gather “information on family life, marriage and divorce, pregnancy, infertility, use of contraception, and men’s and women’s health. The survey results are used…to plan health services and health education programs, and to do statistical studies of families, fertility, and health.”
We will use data collected by this survey to investigate whether first babies tend to be born late, and other questions. To use this data effectively, we have to understand the design of the study.
In general, the goal of a statistical study is to draw conclusions about a population. In the NSFG, the target population is people in the United States aged 15–44.
Ideally, surveys would collect data from every member of the population, but that’s seldom possible. Instead we collect data from a subset of the population called a sample. The people who participate in a survey are called respondents.
The NSFG is a cross-sectional study , which means that it captures a snapshot of a population at a point in time. The NSFG has been conducted several times now; each deployment is called a cycle. We will use data from Cycle 6, which was conducted from January 2002 to March
In general, cross-sectional studies are meant to be representative , which means that the sample is similar to the target population in all ways that are important for the purposes of the study. That ideal is hard to achieve in practice, but people who conduct surveys come as close as they can.
The NSFG is not representative; instead it is stratified , which means that it deliberately oversamples some groups. The designers of the study recruited three groups—Hispanics, African-Americans and teenagers—at rates higher than their representation in the US population to make sure that the number of respondents in each group is large enough to draw valid conclusions. The drawback of oversampling is that it is not as easy to draw conclusions about the population based on statistics from the sample. We will come back to this point later.
When working with this kind of data, it is important to be familiar with the codebook , which documents the design of the study, the survey questions, and the encoding of the responses.
Reading the Data
Before downloading NSFG data, you have to agree to the terms of use:
preg = read_stata(dct_file, dat_file)
The result is a DataFrame , which is a Pandas data structure that represents tabular data in rows and columns. This DataFrame contains a row for each pregnancy reported by a respondent and a column for each variable. A variable can contain responses to a survey question or values that are calculated based on responses to one or more questions.
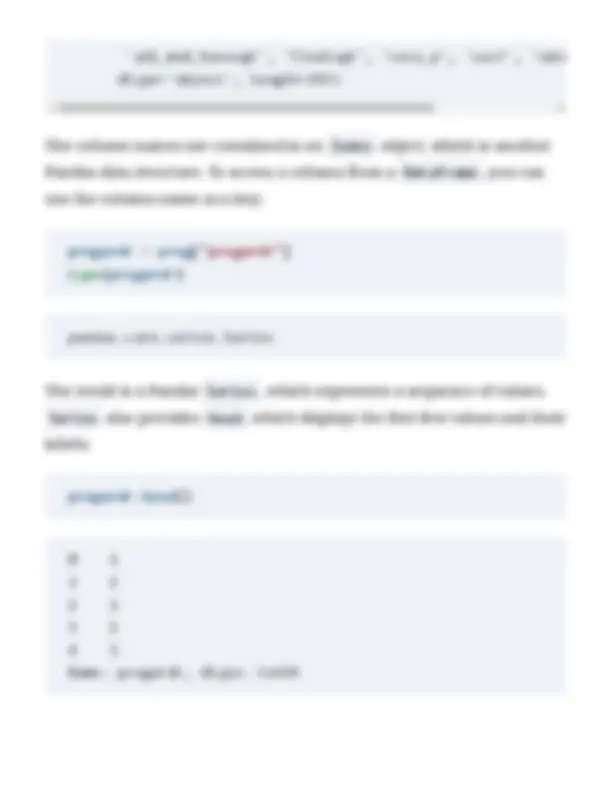
In addition to the data, a DataFrame also contains the variable names and their types, and it provides methods for accessing and modifying the data. The DataFrame has an attribute called shape that contains the number of rows and columns:
preg.shape
This dataset has 243 variables with information about 13, pregnancies. The DataFrame provides a method called head that displays the first few rows:
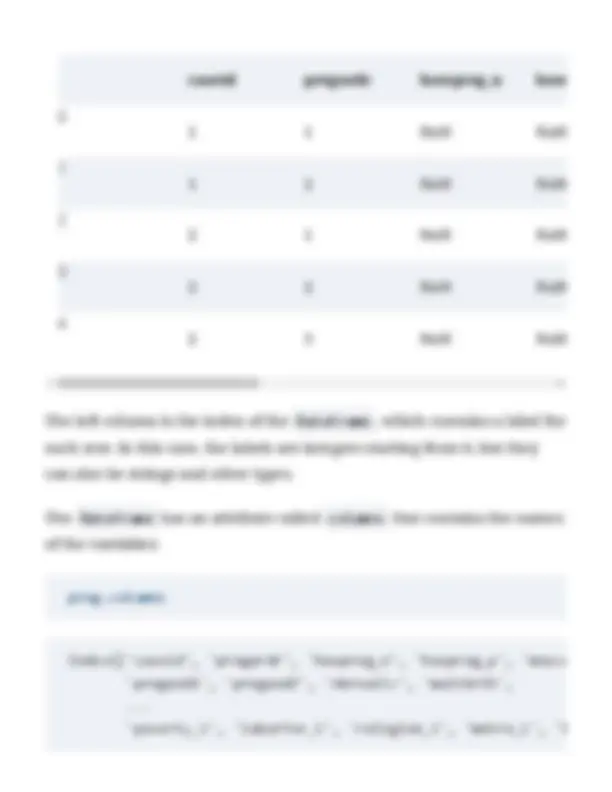
preg.head()
The left column is the index of the DataFrame , which contains a label for each row. In this case, the labels are integers starting from 0, but they can also be strings and other types.
The DataFrame has an attribute called columns that contains the names of the variables:
preg.columns
caseid pregordr howpreg_n how 0 1 1 NaN NaN 1 1 2 NaN NaN 2 2 1 NaN NaN 3 2 2 NaN NaN 4 2 3 NaN NaN
Index(['caseid', 'pregordr', 'howpreg_n', 'howpreg_p', 'moscu 'pregend1', 'pregend2', 'nbrnaliv', 'multbrth', ... 'poverty_i', 'laborfor_i', 'religion_i', 'metro_i', 'b
The last line includes the name of the Series and dtype , which is the type of the values. In this example, int64 indicates that the values are 64-bit integers.
The NSFG dataset contains 243 variables in total. Here are some of the ones we’ll use for the explorations in this book:
caseid The integer ID of the respondent.
pregordr A pregnancy serial number: the code for a respondent’s first pregnancy is 1, for the second pregnancy is 2, and so on.
prglngth The integer duration of the pregnancy in weeks.
outcome An integer code for the outcome of the pregnancy. The code 1 indicates a live birth.
birthord A serial number for live births: the code for a respondent’s first child is 1, and so on. For outcomes other than live birth, this field is blank.
birthwgt_lb and birthwgt_oz Contain the pounds and ounces parts of the birth weight of the baby.
agepreg The mother’s age at the end of the pregnancy.
finalwgt The statistical weight associated with the respondent. It is a floating- point value that indicates the number of people in the US population that this respondent represents.
If you read the codebook carefully, you will see that many of the variables are recodes , which means that they are not part of the raw data collected by the survey—they are calculated using the raw data.
For example, prglngth for live births is equal to the raw variable wksgest (weeks of gestation) if it is available; otherwise it is estimated using mosgest * 4.33 (months of gestation times the average number of weeks in a month).
Recodes are often based on logic that checks the consistency and accuracy of the data. In general it is a good idea to use recodes when they are available, unless there is a compelling reason to process the raw data yourself.
Validation
When data is exported from one software environment and imported into another, errors might be introduced. And when you are getting familiar with a new dataset, you might decode data incorrectly or misunderstand its meaning. If you invest time to validate the data, you can save time later and avoid errors.
which sorts the results according to the values in the Index (the left column):
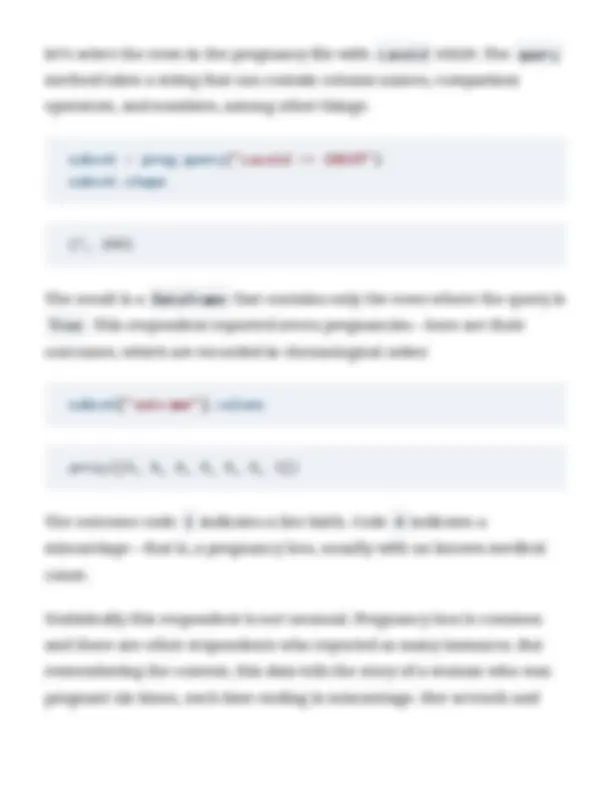
preg["outcome"].value_counts().sort_index()
outcome 1 9148 2 1862 3 120 4 1921 5 190 6 352 Name: count, dtype: int
Comparing the results with the published table, we can confirm that the values in outcome are correct. Similarly, here is the published table for birthwgt_lb :
Value Label Total
. inapplicable 4449
0-5 UNDER 6 POUNDS 1125
6 6 POUNDS 2223
7 7 POUNDS 3049
8 8 POUNDS 1889
9-95 9 POUNDS OR MORE 799
97 Not ascertained 1
98 REFUSED 1
99 DON’T KNOW 57
Total 13593
Birth weight is only recorded for pregnancies that ended in a live birth. The table indicates that there are 4,449 cases where this variable is inapplicable. In addition, there is one case where the question was not
NaN 4449 Name: count, dtype: int
The argument dropna=False means that value_counts does not ignore values that are “NA” or “Not applicable.” These values appear in the results as NaN , which stands for “Not a number”—and the count of these values is consistent with the count of inapplicable cases in the codebook.
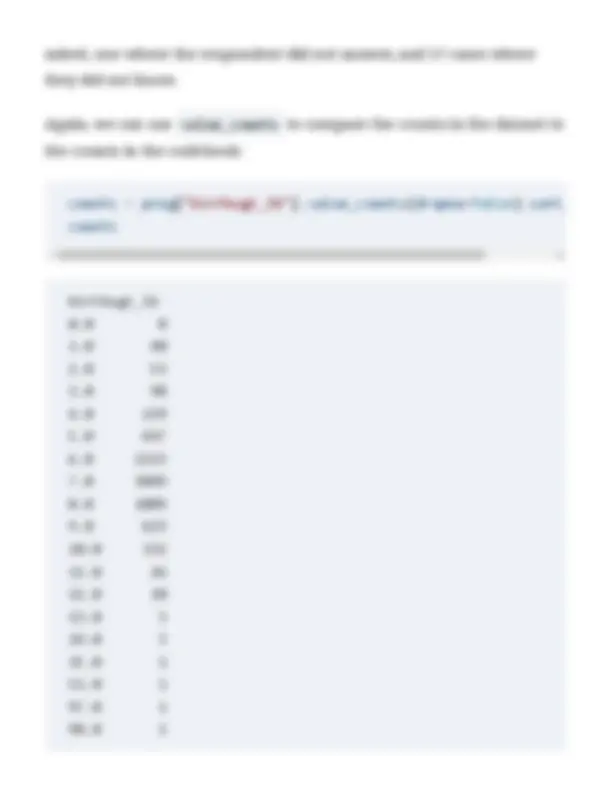
The counts for 6, 7, and 8 pounds are consistent with the codebook. To check the counts for the weight range from 0 to 5 pounds, we can use an attribute called loc —which is short for “location”—and a slice index to select a subset of the counts:
counts.loc[0:5]
birthwgt_lb 0.0 8 1.0 40 2.0 53 3.0 98 4.0 229 5.0 697 Name: count, dtype: int
And we can use the sum method to add them up:
counts.loc[0:5].sum()
The total is consistent with the codebook.
The values 97, 98, and 99 represent cases where the birth weight is unknown. There are several ways we might handle missing data. A simple option is to replace these values with NaN. At the same time, we will also replace a value that is clearly wrong, 51 pounds.
We can use the replace method like this:
The first argument is a list of values to be replaced. The second argument, np.nan , gets the NaN value from NumPy.
When you read data like this, you often have to check for errors and deal with special values. Operations like this are called data cleaning.
Transformation
As another kind of data cleaning, sometimes we have to convert data into different formats, and perform other calculations.
For example, agepreg contains the mother’s age at the end of the pregnancy. According to the codebook, it is an integer number of
preg["birthwgt_lb"] = preg["birthwgt_lb"].replace([51, 97, 98
Now we can use the cleaned values to create a new column that combines pounds and ounces into a single quantity:
The average of the result seems plausible.
Summary Statistics
A statistic is a number derived from a dataset, usually intended to quantify some aspect of the data. Examples include the count, mean, variance, and standard deviation.
A Series object has a count method that returns the number of values that are not nan :
weights = preg["totalwgt_lb"] n = weights.count() n
preg["totalwgt_lb"] = preg["birthwgt_lb"] + preg["birthwgt_oz preg["totalwgt_lb"].mean()
It also provides a sum method that returns the sum of the values—we can use it to compute the mean like this:
mean = weights.sum() / n mean
But as we’ve already seen, there’s also a mean method that does the same thing:
weights.mean()
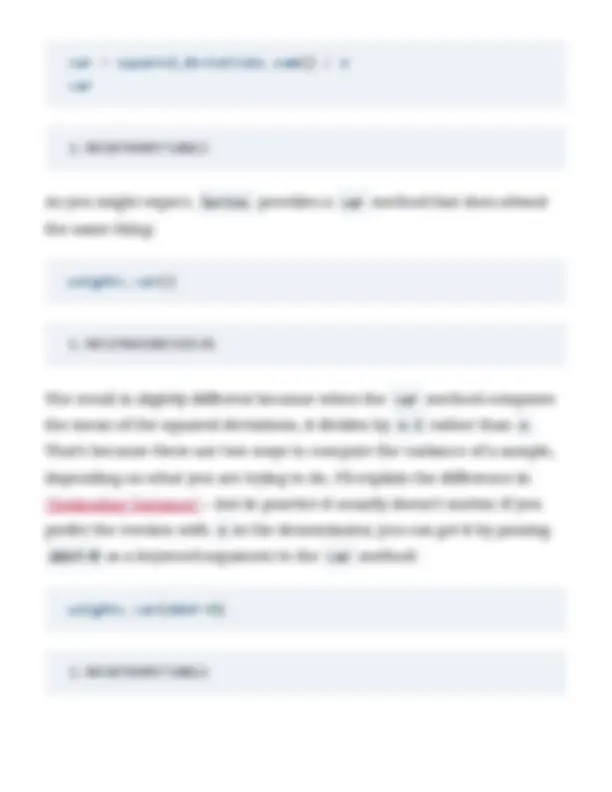
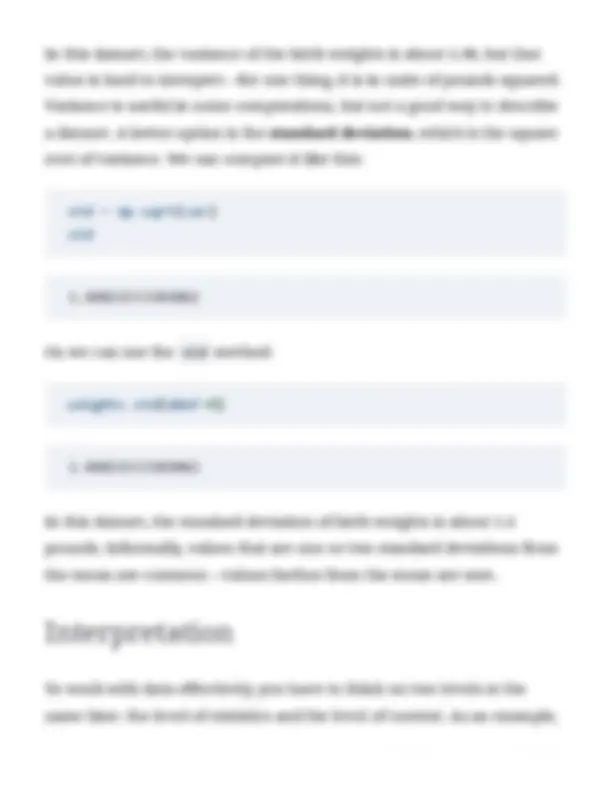
In this dataset, the average birth weight is about 7.3 pounds.
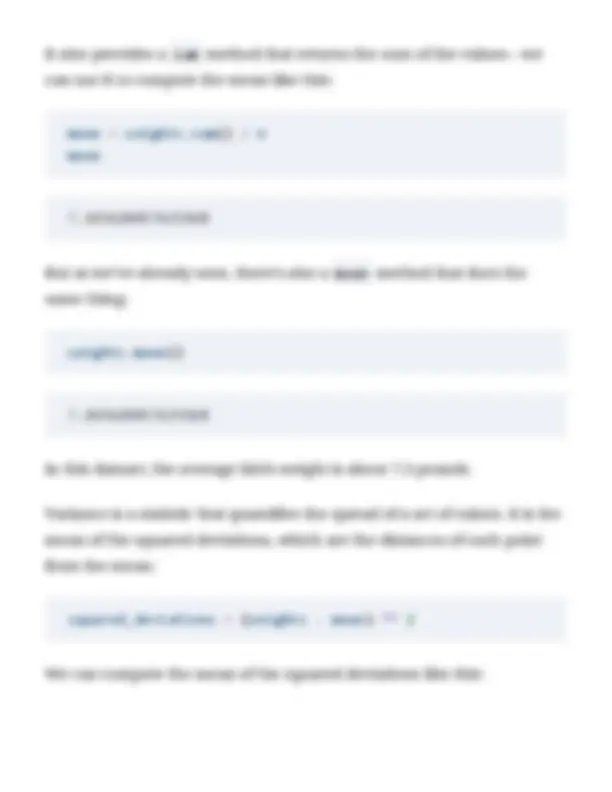
Variance is a statistic that quantifies the spread of a set of values. It is the mean of the squared deviations, which are the distances of each point from the mean:
squared_deviations = (weights - mean) ** 2
We can compute the mean of the squared deviations like this: