



Quantitative Data Analysis

























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Covers the Social Research aspect of Quantitative Data Analysis
Typology: Schemes and Mind Maps
1 / 39

This page cannot be seen from the preview
Don't miss anything!
(^) This section explores: (^) The importance of analysing data from the earliest stage of your research; (^) The distinctions between the different variables generated in quantitative research; (^) Knowing how to examine variables and relationships between them; (^) Methods for analysing a single variable at a time (univariate analysis); (^) Methods for analysing relationships between variables (bivariate analysis); (^) The analysis of relationships between three variables (multivariate analysis).
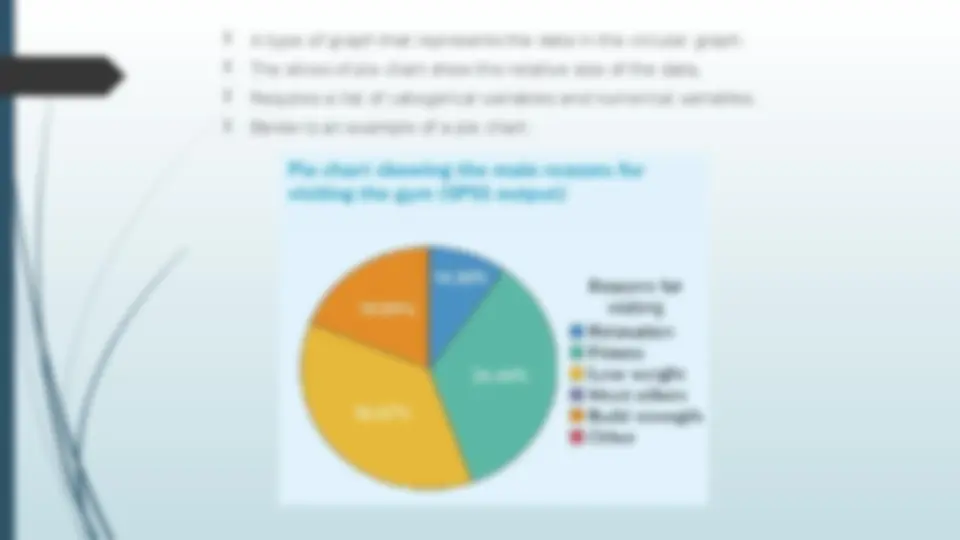
(^) She secures access to contact sample from nearby gym (^) The gym has 1,200 members (^) Student decided to take a random sample of 10% (120 members) of the membership (^) She sends out postal questionnaires with a letter of support from the gym (^) Student focused on how much time people spend on: (^) Cardiovascular and weights equipment, and (^) Exercises. (^) Requested to return the questionnaires to her in a prepaid reply envelope (^) Student ends up with a sample of 90 questionnaires—a response rate of 75%
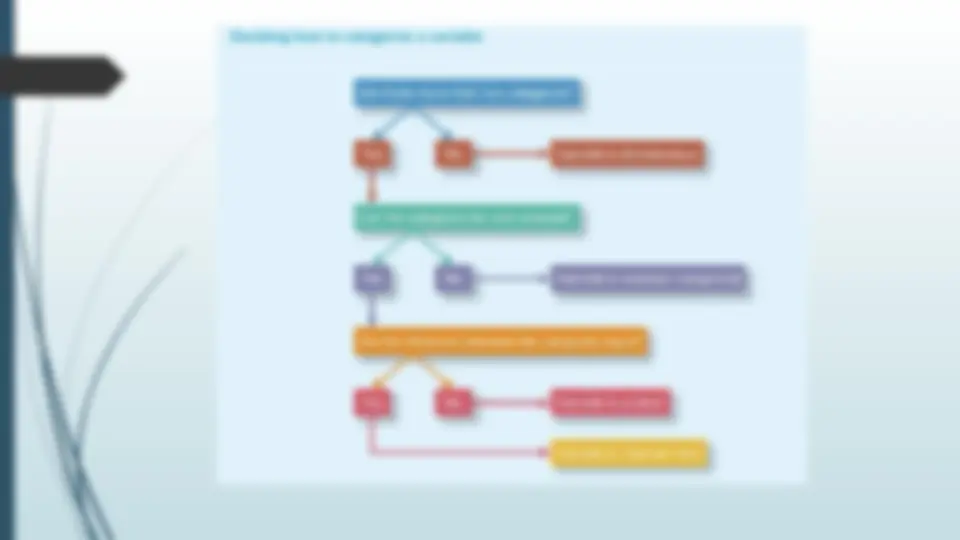
(^) Def: characteristics that can take on different values, such as height, age, test scores etc. (^) Researchers often manipulate or measure independent and dependent variables (^) To test cause-and-effect relationships. (^) The independent variable is the cause. (^) Its value is independent of other variables in your study. (^) The dependent variable is the effect. (^) Its value depends on changes in the independent variable.
(^) Distance between variables is equal.
(^) Categorical variable for which the possible values are rank ordered. (^) The distances between the categories are uneven or unknown.
(^) Nominal variables that can only take on two values, (^) They can be considered as having attributes of the other three types of variable. (^) They look as though they are nominal variables, but because they have only one interval (^) They are sometimes treated as ordinal variables. (^) However, it is probably safest to treat them as if they were ordinary nominal variables. (^) For example, males and females.
Coding (^) To conduct analysis, researchers often must engage in a coding process (^) This is conducted after the data have been collected. (^) Quantitative coding - categorising the non-numerical information into groups and (^) Assigning the numerical codes to these groups. (^) Raw numerical data is captured into a codebook (^) This numerical data is categorized (assigned location) in the codebook (^) This makes it easier for processing and analysis
(^) A codebook serves two essential functions:
(^) Independent variable attributes are typically presented in the table’s columns, (^) Dependent variable attributes are presented in rows.
(^) Table 7.1 shows association between gender and experiencing harassing behaviours at work (^) Gender is the independent variable (the predictor); (^) The harassing behaviours listed are the dependent variables (the outcome) (^) Independent variable - influences outcomes – cause (^) Dependent variable – outcome as a result of independent variable – effect